







 论文探讨了强化学习在文本生成中的挑战,尤其是词表过大导致的低效问题。PCL通过引入熵,结合策略优化和价值函数,旨在提高采样效率,确保在满足随机性和奖励最大化的同时进行更有效的模型更新。
论文探讨了强化学习在文本生成中的挑战,尤其是词表过大导致的低效问题。PCL通过引入熵,结合策略优化和价值函数,旨在提高采样效率,确保在满足随机性和奖励最大化的同时进行更有效的模型更新。
参考:Bridging the Gap Between Value and Policy论文阅读笔记 - 知乎
论文:Bridging the Gap Between Value and Policy Based Reinforcement Learning
Efficient (Soft) Q-Learning for Text Generation with Limited Good Data 这篇论文将soft Q-learning算法和文本生成任务联系了起来,论文中提到当前的基于强化学习的文本生成方法会有一个问题:生成文本用到的词表太大(比如5W这样的规模),当用强化学习逐个生成文字时,会导致代理的动作空间很大。但采样更新代理的时候,每生成一句话只能涉及到几个单词,也就导致生成模型的更新会很慢,效率会很低。
所以这篇论文引入了PCL,说是能够每次都更新所有单词。但我了解完了PCL后,还是不懂怎么解决了更新效率的问题。先浅记一下目前对PCL的理解。
首先PCL在强化学习中引入了熵,也就是在代理每一次决定执行的动作时,即要考虑奖励最大化,也要考虑当前步的熵要最大,也就是的分布要更随机一点,这样就能提高模型采样的随机性。
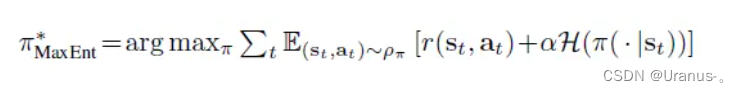
比如这个公式,r表示奖励,H表示熵,这样策略pi就能同时考虑到奖励和熵。
引入熵之后,论文就开始求解最优的策略pi和Q函数、V函数,从而涉及损失函数。
这是最优的Q函数满足的递归形式:
这是最优的V函数满足的递归形式:
这是最优的策略pi:
这是在满足熵和奖励最大化情况下值函数的一个很重要的性质temporal consistency

这个性质是单步的,它也可以推到多步:

基于这个性质,论文定义了损失函数,步数为d的一条轨迹样本能带来的损失:
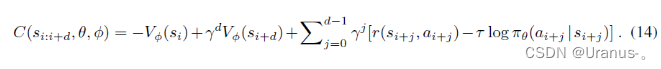

其实就是把上面那个多步等式移到一边,希望两边相减越小越好。以上几个公式中的这一项可以简单理解为单步的熵。
具体推导看上面那个zhihu帖子,目前对PCL的理解,就是引入熵满足了随机性,从而在采样的时候能尽量充分的探索动作空间。















 976
976











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









