







 本文介绍如何使用Spark的Structured JDBC方式连接到远程高可用的HIVE集群。在配置过程中,遇到了由于缺少IP配置导致的错误,通过在不同机器上设置域名与IP的映射关系,最终成功解决问题。
本文介绍如何使用Spark的Structured JDBC方式连接到远程高可用的HIVE集群。在配置过程中,遇到了由于缺少IP配置导致的错误,通过在不同机器上设置域名与IP的映射关系,最终成功解决问题。
1. 背景

Spark: Structured JDBC 方式访问远程的高可用HA的HIVE,hive是看高可用的,连接信息如下
jdbc:hive2://xx.cdh1.test.dtwave.internal:2181,xxx.cdh1.test.dtwave.internal:2181,xxx.cdh1.test.dtwave.internal:2181/lb_test;serviceDiscoveryMode=zooKeeper;zooKeeperNamespace=hiveserver2_zk
用户名:hive
密码:hive
然后集群是这样的
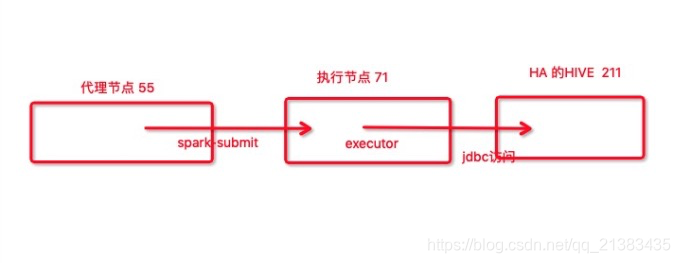
然后我在55机器上配置了域名与ip对应关系
121.196.xx.xx xx.cdh1.test.dtwave.internal
121.199.xx.xx xx.cdh1.test.dtwave.internal
然后执行报错
DD.iterator(RDD.scala:288)
at org.apache.spark.rdd.MapPartitio
 订阅专栏 解锁全文
订阅专栏 解锁全文


















 841
841

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











