






本文介绍森林图的Python matplotlib实现。
什么是森林图?
森林图,也被称为回归系数图(coefplots)、系数图(coefficient plots)、荟萃分析图(meta-analysis plots)、点须图(dot-and-whisker plots)、泡泡图(blobbograms)、边际图(margins plots)、回归图(regression plots)和绳梯图(ropeladder plots),在医学和健康科学领域被广泛使用。它通常用于展示来自不同研究的结果,尤其是作为荟萃分析(meta-analysis)的一部分。
森林图用于展示和比较多个研究或模型的效应估计及其不确定性,并通过水平线(即置信区间)显示估计值的可信度。每个标记代表一个效应值,标记中心对应估计的效应大小,水平线则表示该效应值的置信区间。较短的置信区间表示估计值较为精确,较长的置信区间则表明估计值的不确定性较大。
matplotlib制作森林图
利用Python matplotlib结合forestplot ,可轻松绘制森林。使用“3.2.13 forestplot数据集”,展示分组森林图。
- 数据准备
# 23.1_01
# -*- encoding: utf-8 -*-
'''
未经过允许禁止转载!
@Author : 公众号: pythonic生物人
@Desc : 23.1 分组森林图
'''
# 数据准备
forestplot = pd.read_csv("matplotlib_data/forestplot.csv").query(
"model=='all' | model=='young kids'")
def format_value(val):
try:
val = float(val)
if val < 0.001:
return f"{val:.3f}***"
elif val < 0.01:
return f"{val:.3f}**"
elif val < 0.05:
return f"{val:.3f}*"
else:
return f"{val:.3f}"
except ValueError:
return str(val)
forestplot["pval"] = forestplot["pval"].astype(float).apply(
format_value) # 格式化p值列
forestplot["CI"] = forestplot.apply(
lambda row: f"{row['coef']:.2f} ({row['ll']:.2f},{row['hl']:.2f})",
axis=1) # 格式化置信区间列
- 绘图
fp.mforestplot(
dataframe=forestplot, # 数据源,指定为包含绘图所需信息的 DataFrame
estimate="coef", # 用于绘制估计值(点估计)的列
ll="ll", # 用于绘制置信区间的下限列
hl="hl", # 用于绘制置信区间的上限列
varlabel="label", # 每个变量的标签列,显示在图表的左侧
capitalize="capitalize", # 用于分组标题的列
model_col="model", # 不同模型的分类列,用于区分多条线
color_alt_rows=True, # 交替改变行的背景颜色
groupvar="group", # 用于分组的列,根据此列合并相关变量
table=True, # 添加表格
rightannote=["CI", "pval"], # 右侧注释列,这里为置信区间和 P 值
right_annoteheaders=["Est.(95% Conf. Int.)", "P-value"], # 右侧注释列的标题
xlabel="Coefficient (95% CI)", # X 轴标签
modellabels=["Have young kids", "Full sample"], # 模型标签,用于图例中区分不同模型
xticks=[-1200, -600, 0, 600], # 自定义 X 轴刻度
mcolor=['#b1283a', '#006a8e'], # 不同模型的颜色列表
**{
"markersize": 30, # 点的大小
"offset": 0.40, # 模型线条之间的垂直偏移
"xlinestyle": "--", # X 轴参考线线型
"xlinecolor": "gray", # X 轴参考线的颜色,灰色
},
)
plt.show()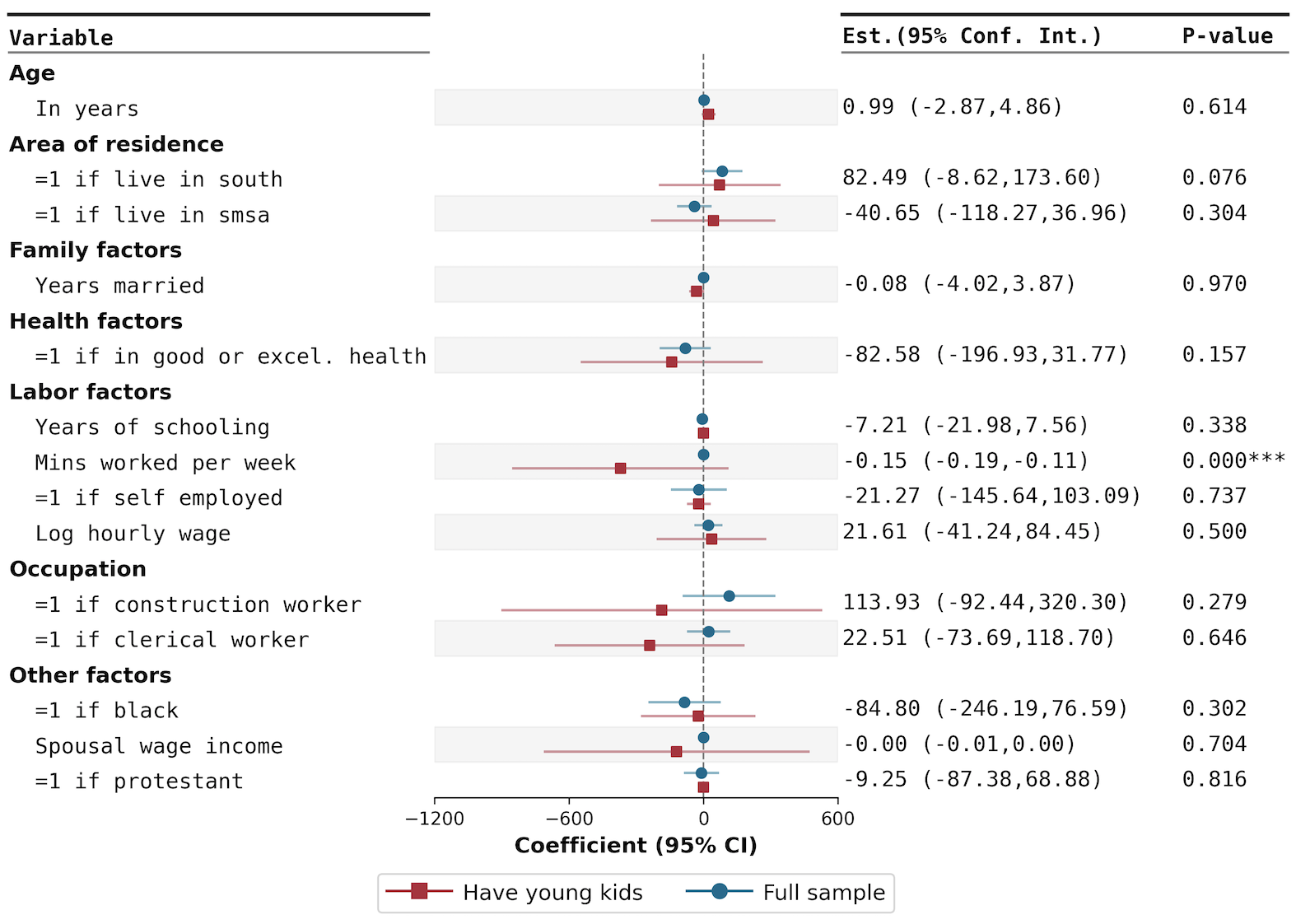
这个森林图的作用是展示不同模型中每个变量的估计值及其置信区间(图中的不同颜色和标签分别代表不同的模型,红色代表“Have young kids”模型,蓝色代表“Full sample”模型)。同时,图中还标注了相关的统计信息(例如,p值)。通过比较不同模型中变量的估计值和置信区间,研究人员可以了解各个模型下变量的稳定性和效应大小。
推荐阅读:




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











