






文章目录
基于TensorFlow.NET实现Transformer基本模型
TensorFlow.NET简介
Tensorflow.NET是AI框架TensorFlow在.NET平台上的实现,支持C#和F#,可以用来搭建深度学习模型并进行训练和推理,并内置了Numpy API,可以用来进行其它科学计算。
Tensorflow.NET并非对于Python的简单封装,而是基于C API的pure C#实现,因此使用时无需额外的环境,可以很方便地用NuGet直接安装使用。并且dotnet团队提供的ML.NET也依赖于Tensorflow.NET,支持调用Tensorflow.NET进行训练和推理,可以很方便地融入.NET生态。
与tensorflow相同,Tensorflow.NET也内置了Keras这一高级API,只要在安装Tensorflow.NET的同时安装Tensorflow.Keras就可以使用,Keras支持以模块化的方式调用模型,给模型的搭建提供了极大的便利。
Transformer实现
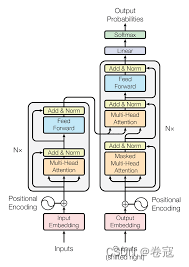
Transformer模型是一种深度学习架构,于2017年由Vaswani等人提出,革命性地改变了自然语言处理(NLP)领域。它摒弃了传统的循环神经网络(RNN)和卷积神经网络(CNN),采用自注意力机制(Self-Attention)来捕捉序列中的依赖关系。这使得模型能够并行处理序列中的所有元素,提高了计算效率。Transformer由编码器(encoder)和解码器(decoder)组成。编码器接收输入序列,通过自注意力层和前馈神经网络层堆叠而成;解码器则生成输出序列,结构与编码器相似,多了一个编码器-解码器注意力层。它们共同实现了序列到序列(Seq2Seq)的映射。Transformer通过位置编码(Positional Encoding)引入位置信息,增强模型对顺序的敏感性。扩展的应用包括:BERT、GPT等预训练模型,为NLP领域带来了显著的性能提升。本项目是基于TensorFlow.NET进行Transformer的模型架构实现, 利用Keras API从零开始构建模型。最终需要在GPU上完成模型训练,性能测试和模型保存和推理,并与Keras官方实现的Text classification with Transformer对齐预测性能。
依赖项
TensorFlow.Keras
SciSharp.TensorFlow.Redist
参数定义
using System;
using System.Collections.Generic;
using System.Text;
using Newtonsoft.Json;
namespace Tensorflow.Keras.ArgsDefinition
{
public class TokenAndPositionEmbeddingArgs : AutoSerializeLayerArgs
{
[JsonProperty("max_len")]
public int Maxlen { get; set; }
[JsonProperty("vocab_sise")]
public int VocabSize { get; set; }
[JsonProperty("embed_dim")]
public int EmbedDim { get; set; }
[JsonProperty("activity_regularizer")]
public override IRegularizer ActivityRegularizer { get => base.ActivityRegularizer; set => base.ActivityRegularizer = value; }
}
public class TransformerBlockArgs : AutoSerializeLayerArgs
{
[JsonProperty("embed_dim")]
public int EmbedDim { get; set; }
[JsonProperty("num_heads")]
public int NumHeads { get; set; }
[JsonProperty("ff_dim")]
public int FfDim { get; set; }
[JsonProperty("dropout_rate")]
public float DropoutRate { get; set; } = 0.1f;
[JsonProperty("activity_regularizer")]
public override IRegularizer ActivityRegularizer { get => base.ActivityRegularizer; set => base.ActivityRegularizer = value; }
}
public class TransformerClassificationArgs : AutoSerializeLayerArgs
{
[JsonProperty("max_len")]
public int Maxlen { get; set; }
[JsonProperty("vocab_sise")]
public int VocabSize { get; set; }
[JsonProperty("embed_dim")]
public int EmbedDim { get; set; }
[JsonProperty("num_heads")]
public int NumHeads { get; set; }
[JsonProperty("ff_dim")]
public int FfDim { get; set; }
[JsonProperty("dropout_rate")]
public float DropoutRate { get; set; } = 0.1f;
[JsonProperty("dense_dim")]
public int DenseDim { get; set; }
[JsonProperty("activity_regularizer")]
public override IRegularizer ActivityRegularizer { get => base.ActivityRegularizer; set => base.ActivityRegularizer = value; }
}
}
Transformer Block
每个Transformer块包含一个多头自注意力机制和一个前馈神经网络。自注意力机制允许模型在处理每个单词时关注其他单词的上下文信息,而前馈神经网络则有助于捕获单词之间的复杂关系。这个块的重复堆叠允许模型从不同抽象层次对文本信息进行编码。
全局平均池化层和Dropout层:经过Transformer块后,利用全局平均池化获得固定长度的向量表示,有助于将不同长度的输入序列映射到固定维度。此外,为减少过拟合,应用了Dropout层。
全连接层:最终,经过处理的向量传递给全连接层,用于文本分类。具体而言,对于IMDB情感两类分类任务,模型使用具有两个输出节点的全连接层,并使用softmax激活函数获得每个类别的概率,以判断对应是输入评论是积极的还是消极的。
using System;
using System.Collections.Generic;
using System.IO;
using System.Text;
using Tensorflow;
using Tensorflow.Common.Types;
using Tensorflow.Keras;
using Tensorflow.Keras.ArgsDefinition;
using Tensorflow.Keras.Engine;
using Tensorflow.Keras.Saving;
using static Tensorflow.KerasApi;
namespace Tensorflow.Keras.Layers
{
public class TransformerBlock : Layer
{
TransformerBlockArgs args;
ILayer att;
ILayer dropout1;
ILayer layernorm1;
ILayer ffn1;
ILayer ffn2;
ILayer dropout2;
ILayer layernorm2;
public TransformerBlock(TransformerBlockArgs args) : base(args)
{
this.args = args;
}
public override void build(KerasShapesWrapper input_shape)
{
_buildInputShape = input_shape;
att = keras.layers.MultiHeadAttention(args.NumHeads, args.EmbedDim);
dropout1 = keras.layers.Dropout(args.DropoutRate);
layernorm1 = keras.layers.LayerNormalization(axis: -1, epsilon: 1e-6f);
ffn1 = keras.layers.Dense(args.FfDim, activation: "relu");
ffn2 = keras.layers.Dense(args.EmbedDim);
dropout2 = keras.layers.Dropout(args.DropoutRate);
layernorm2 = keras.layers.LayerNormalization(axis: -1, epsilon: 1e-6f);
StackLayers(att, dropout1, layernorm1, ffn1, ffn2, dropout2, layernorm2);
built = true;
}
protected override Tensors Call(Tensors inputs, Tensors state = null, bool? training = null, IOptionalArgs? optional_args = null)
{
var att_output = att.Apply(new Tensors(inputs, inputs), state, training, optional_args);
att_output = dropout1.Apply(att_output, state, training, optional_args);
var out1 = layernorm1.Apply((Tensor)inputs + (Tensor)att_output, state, training, optional_args);
var ffn_output = ffn1.Apply(out1, state, training, optional_args);
ffn_output = ffn2.Apply(ffn_output, state, training, optional_args);
ffn_output = dropout2.Apply(ffn_output, state, training, optional_args);
var output = layernorm2.Apply((Tensor)out1 + (Tensor)ffn_output, state, training, optional_args);
return output;
}
}
}
Embedding
首先将输入的词向量转化为高维向量表示。为此,我们使用了两个嵌入层:一个是token嵌入层,另一个是position嵌入层。token嵌入层将输入映射为具有更高维度的向量,而position嵌入层为每个单词的位置分配了一个向量表示。这两个表示相加后,生成了一个embedding向量,捕捉了单词和其位置的信息。
using Serilog.Debugging;
using System;
using System.Collections.Generic;
using System.Text;
using Tensorflow;
using Tensorflow.Common.Types;
using Tensorflow.Keras;
using Tensorflow.Keras.ArgsDefinition;
using Tensorflow.Keras.Engine;
using Tensorflow.Keras.Saving;
using static Tensorflow.Binding;
using static Tensorflow.KerasApi;
namespace Tensorflow.Keras.Layers
{
public class TokenAndPositionEmbedding : Layer
{
TokenAndPositionEmbeddingArgs args;
ILayer token_emb;
IVariableV1 position_embeddings;
public TokenAndPositionEmbedding(TokenAndPositionEmbeddingArgs args) : base(args)
{
this.args = args;
}
public override void build(KerasShapesWrapper input_shape)
{
_buildInputShape = input_shape;
token_emb = keras.layers.Embedding(input_dim: args.VocabSize, output_dim: args.EmbedDim);
tf_with(ops.name_scope("position_embeddings"), scope =>
{
position_embeddings = add_weight(name: "position_embedding", shape: (args.Maxlen, args.EmbedDim));
});
StackLayers(token_emb);
built = true;
}
protected override Tensors Call(Tensors inputs, Tensors state = null, bool? training = null, IOptionalArgs? optional_args = null)
{
var embedding = token_emb.Apply(inputs, state, training, optional_args);
var maxlen = inputs.shape[-1];
var position_ids = tf.range(start: 0, limit: maxlen, delta: 1);
var positions = tf.gather(position_embeddings.AsTensor(), indices: position_ids);
return (Tensor)embedding + (Tensor)positions;
}
}
}
Data Loader
项目使用IMDB(Internet Movie Database)数据集完成文本分类任务。数据集包含了50000条偏向明显的评论,其中25000条作为训练集,25000作为测试集,标签为1(positive)和0(negative),数据集中的各条评论已经被预处理为了词向量。从网站中下载得到IMDB的npz文件,其中的词向量数据是一个不规则列表的pickle文件,需要使用pad_sequences对词向量进行预处理,将各个句子填充到相同长度。我们设定词汇表大小为20000,每一个词向量的最大长度为200,将数据集加载到x_train,y_train,x_val,y_val这四个numpy数组中。
using System;
using System.Collections.Generic;
using System.IO;
using System.Linq;
using System.Security.Cryptography;
using System.Text;
using Tensorflow;
using Tensorflow.NumPy;
using static Tensorflow.Binding;
using static Tensorflow.KerasApi;
namespace SciSharp.Models.Transformer
{
public class IMDbDataset
{
TransformerClassificationConfig cfg;
public IMDbDataset()
{
cfg = new TransformerClassificationConfig();
}
public IMDbDataset(TransformerClassificationConfig cfg)
{
this.cfg = cfg;
}
public IMDbDataset(int vocab_size, int maxlen)
{
cfg = new TransformerClassificationConfig();
cfg.DatasetCfg.vocab_size = vocab_size;
cfg.DatasetCfg.maxlen = maxlen;
}
public Tensor[] GetData()
{
var dataset = keras.datasets.imdb.load_data(num_words: cfg.DatasetCfg.vocab_size);
var x_train = dataset.Train.Item1;
var y_train = dataset.Train.Item2;
var x_val = dataset.Test.Item1;
var y_val = dataset.Test.Item2;
x_train = keras.preprocessing.sequence.pad_sequences(RemoveZeros(x_train), maxlen: cfg.DatasetCfg.maxlen);
x_val = keras.preprocessing.sequence.pad_sequences(RemoveZeros(x_val), maxlen: cfg.DatasetCfg.maxlen);
print(len(x_train) + " Training sequences");
print(len(x_val) + " Validation sequences");
return new[] { x_train.astype(np.float32), y_train.astype(np.float32), x_val.astype(np.float32), y_val.astype(np.float32) };
}
IEnumerable<int[]> RemoveZeros(NDArray data)
{
var data_array = (int[,])data.ToMultiDimArray<int>();
List<int[]> new_data = new List<int[]>();
for (var i = 0; i < data_array.GetLength(0); i++)
{
List<int> new_array = new List<int>();
for (var j = 0; j < data_array.GetLength(1); j++)
{
if (data_array[i, j] == 0)
break;
else
new_array.Add(data_array[i, j]);
}
new_data.Add(new_array.ToArray());
}
return new_data;
}
}
}
Hyper-parameters Config
-
DatasetConfig定义与用于训练和评估Transformer分类模型的数据集相关的参数。-
vocab_size:整数,表示词汇表的大小。它确定在标记化和嵌入期间考虑的唯一标记数量。默认值为 20,000。 -
maxlen:整数,指定输入序列的最大长度。长度超过此值的序列将被截断,而较短的序列将被填充。默认值为 200。 -
path:字符串,表示数据集的路径。这是存储训练和评估数据集的位置。默认使用项目工程内提供的demo IMDB数据集,它是IMDB完整数据集的前1000条training数据, 前200条testing数据构成的子集。
-
-
ModelConfig部分定义确定Transformer模型的架构和特性的参数。embed_dim:整数,指定标记嵌入的维度。该值表示嵌入后的标记向量的大小。默认值为 32。num_heads:整数,表示Transformer中多头自注意力机制的注意头数量。默认值为 2。ff_dim:整数,指定Transformer中前馈神经网络部分的隐藏层维度。默认值为 32。dropout_rate:浮点数,表示应用于模型各部分的丢弃率,有助于防止过拟合。默认值为 0.1。dense_dim:整数,指定模型分类头部中密集层的维度。该层用于处理Transformer的输出以进行分类。默认值为 20。
-
TrainConfig部分定义与模型训练过程相关的参数。batch_size:整数,指定每个批次中的训练样本数量。默认值为 32。epochs:整数,表示训练周期的数量。每个周期代表对整个训练数据集的完整遍历。默认值为 10。
using System;
using System.Collections.Generic;
using System.IO;
using System.Text;
namespace SciSharp.Models.Transformer
{
public class TransformerClassificationConfig
{
public DatasetConfig DatasetCfg;
public ModelConfig ModelCfg;
public TrainConfig TrainCfg;
public TransformerClassificationConfig()
{
DatasetCfg = new DatasetConfig();
ModelCfg = new ModelConfig();
TrainCfg = new TrainConfig();
}
public class DatasetConfig
{
public int vocab_size = 20000; // Only consider the top 20k words
public int maxlen = 200; // Only consider the first 200 words of each movie review
public string path = null; // Dataset Path
}
public class ModelConfig
{
public int embed_dim = 32; // Embedding size for each token
public int num_heads = 2; // Number of attention heads
public int ff_dim = 32; // Hidden layer size in feed forward network inside transformer
public float dropout_rate = 0.1f; // Dropout rate
public int dense_dim = 20;
}
public class TrainConfig
{
public int batch_size = 32;
public int epochs = 10;
}
}
}
Transformer
定义优化器与损失函数
在模型构建后,通过以下方式配置优化器和损失函数来指导训练过程中参数的调整:
- 优化器:选择Adam优化器,一种常用的自适应学习率优化算法。它基于参数的梯度和一些调整项来自适应地调整学习率,以实现更快的收敛和稳定的训练。
- 损失函数:考虑到任务是文本分类,使用稀疏分类交叉熵损失函数。该损失函数在多类别分类问题中效果显著,帮助模型根据实际标签调整参数,以更好地匹配标签分布。
定义模型用例
模型训练
定义 Train 函数,用于训练模型。以下是训练模型的步骤:
- 创建
IMDbDataset实例,负责加载和处理IMDb数据集。 - 从数据集中获取训练和验证数据。
- 构建模型,通过调用
Build函数。 - 使用
model.summary()打印模型的摘要信息,包括每一层的结构和参数数量。 - 使用
compile方法配置模型的优化器、损失函数和评估指标。 - 使用
fit方法来训练模型,传入训练数据、批次大小、迭代次数和验证数据。
保存模型
定义 Save 函数,用于将已训练的模型参数保存到指定路径。这个函数接受一个模型对象和保存路径作为参数。模型将以h5格式保存参数到指定路径中。
加载模型
定义 Load 函数,用于从指定路径加载已保存的模型参数。这个函数接受一个路径参数和一个可选的模型配置,并返回加载参数的模型。
模型推理
训练完成后使用 Predict 函数来进行推理/预测。这个函数接受Transformer模型和输入张量,并返回模型对输入数据的预测输出。
模型评估
定义了 Evaluate 函数,用于评估模型在验证集上的性能。具体步骤如下:
- 创建一个新的
TransformerClassificationConfig实例。 - 使用数据加载器加载IMDb数据集。
- 从数据集中获取验证数据。
- 使用
compile方法配置模型的优化器、损失函数和评估指标。评估指标为准确率。 - 使用
evaluate方法计算模型在验证数据上的损失和指标。 - 打印评估结果。
using System;
using SciSharp.Models.Transformer;
using Tensorflow.NumPy;
using Tensorflow.Common.Types;
using Tensorflow.Keras.ArgsDefinition;
using Tensorflow.Keras.Engine;
using Tensorflow.Keras.Saving;
using static Tensorflow.KerasApi;
using System.IO;
namespace Tensorflow.Keras.Layers;
public class TransformerClassification : Layer
{
TransformerClassificationArgs args;
ILayer embedding_layer;
ILayer transformer_block;
ILayer pooling;
ILayer dropout1;
ILayer dense;
ILayer dropout2;
ILayer output;
public TransformerClassification(TransformerClassificationArgs args) : base(args)
{
this.args = args;
}
public override void build(KerasShapesWrapper input_shape)
{
_buildInputShape = input_shape;
embedding_layer = new TokenAndPositionEmbedding(new TokenAndPositionEmbeddingArgs { Maxlen = args.Maxlen, VocabSize = args.VocabSize, EmbedDim = args.EmbedDim });
transformer_block = new TransformerBlock(new TransformerBlockArgs { EmbedDim = args.EmbedDim, NumHeads = args.NumHeads, FfDim = args.FfDim });
pooling = keras.layers.GlobalAveragePooling1D();
dropout1 = keras.layers.Dropout(args.DropoutRate);
dense = keras.layers.Dense(args.DenseDim, activation: "relu");
dropout2 = keras.layers.Dropout(args.DropoutRate);
output = keras.layers.Dense(2, activation: "softmax");
StackLayers(embedding_layer, transformer_block, pooling, dropout1, dense, dropout2, output);
built = true;
}
protected override Tensors Call(Tensors inputs, Tensors state = null, bool? training = null, IOptionalArgs? optional_args = null)
{
var embeddings = embedding_layer.Apply(inputs, state, training, optional_args);
var outputs = transformer_block.Apply(embeddings, state, training, optional_args);
outputs = pooling.Apply(outputs, state, training, optional_args);
outputs = dropout1.Apply(outputs, state, training, optional_args);
outputs = dense.Apply(outputs, state, training, optional_args);
outputs = dropout2.Apply(outputs, state, training, optional_args);
outputs = output.Apply(outputs, state, training, optional_args);
return outputs;
}
public IModel Build(TransformerClassificationConfig cfg)
{
var inputs = keras.layers.Input(shape: new[] { cfg.DatasetCfg.maxlen });
var transformer = new TransformerClassification(
new TransformerClassificationArgs
{
Maxlen = cfg.DatasetCfg.maxlen,
VocabSize = cfg.DatasetCfg.vocab_size,
EmbedDim = cfg.ModelCfg.embed_dim,
NumHeads = cfg.ModelCfg.num_heads,
FfDim = cfg.ModelCfg.ff_dim,
DropoutRate = cfg.ModelCfg.dropout_rate,
DenseDim = cfg.ModelCfg.dense_dim
});
var outputs = transformer.Apply(inputs);
return keras.Model(inputs: inputs, outputs: outputs);
}
public IModel Train(TransformerClassificationConfig? cfg = null)
{
cfg = cfg ?? new TransformerClassificationConfig();
var dataloader = new IMDbDataset(cfg); //the dataset is initially downloaded at TEMP dir, e.g., C:\Users\{user name}\AppData\Local\Temp\imdb\imdb.npz
var dataset = dataloader.GetData();
var (x_train, y_train) = (dataset[0], dataset[1]);
var (x_val, y_val) = (dataset[2], dataset[3]);
var model = Build(cfg);
model.summary();
model.compile(optimizer: keras.optimizers.Adam(learning_rate: 0.01f), loss: keras.losses.SparseCategoricalCrossentropy(), metrics: new string[] { "accuracy" });
model.fit((NDArray)x_train, (NDArray)y_train, batch_size: cfg.TrainCfg.batch_size, epochs: cfg.TrainCfg.epochs, validation_data: ((NDArray val_x, NDArray val_y))(x_val, y_val));
return model;
}
public void Save(IModel model, string path)
{
path = Path.Combine(path, "weights.h5");
model.save_weights(path);
}
public IModel Load(string path, TransformerClassificationConfig? cfg = null)
{
cfg = cfg ?? new TransformerClassificationConfig();
var model = Build(cfg);
model.load_weights(Path.Combine(path, "weights.h5"));
return model;
}
public Tensors Predict(IModel model, Tensors inputs)
{
var outputs = model.predict(inputs);
return outputs;
}
public void Evaluate(IModel model)
{
var cfg = new TransformerClassificationConfig();
var dataloader = new IMDbDataset(cfg); //the dataset is initially downloaded at TEMP dir, e.g., C:\Users\{user name}\AppData\Local\Temp\imdb\imdb.npz
var dataset = dataloader.GetData();
var (x_val, y_val) = (dataset[2], dataset[3]);
model.compile(optimizer: keras.optimizers.Adam(learning_rate: 0.01f), loss: keras.losses.SparseCategoricalCrossentropy(), metrics: new string[] { "accuracy" });
model.evaluate((NDArray)x_val, (NDArray)y_val);
Console.WriteLine();
}
}
使用方法
训练并保存
示例函数
public void TextClassificationTrainAndSave()
{
var config = new TransformerClassificationConfig();
var transformer = new TransformerClassification(new TransformerClassificationArgs
{
});
IModel model = transformer.Train(config);
model.summary();
string save_path = @"C:\Users\{user name}\AppData\Local\Temp\imdb\model";
transformer.Save(model, save_path);
}
训练日志
2023-08-24 22:07:38.055694: I tensorflow/core/platform/cpu_feature_guard.cc:193] This TensorFlow binary is optimized with oneAPI Deep Neural Network Library (oneDNN) to use the following CPU instructions in performance-critical operations: AVX2
To enable them in other operations, rebuild TensorFlow with the appropriate compiler flags.
2023-08-24 22:07:39.093278: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1616] Created device /job:localhost/replica:0/task:0/device:GPU:0 with 1334 MB memory: -> device: 0, name: NVIDIA GeForce MX150, pci bus id: 0000:01:00.0, compute capability: 6.1
2023-08-24 22:07:39.146982: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1616] Created device /job:localhost/replica:0/task:0/device:GPU:0 with 1334 MB memory: -> device: 0, name: NVIDIA GeForce MX150, pci bus id: 0000:01:00.0, compute capability: 6.1
25000Training sequences
25000Validation sequences
Model: model
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_1 (InputLayer) (None, 200) 0
_________________________________________________________________
transformer_classification (T (None, 2) 649374
=================================================================
Total params: 649374
Trainable params: 649374
Non-trainable params: 0
_________________________________________________________________
Epoch: 001/010
0782/0782 [=============================] - 35ms/step - loss: 0.399411 - accuracy: 0.804040 - val_loss: 0.336456 - val_accuracy: 0.854680
Epoch: 002/010
0782/0782 [=============================] - 38ms/step - loss: 0.191934 - accuracy: 0.925360 - val_loss: 0.349837 - val_accuracy: 0.860960
Epoch: 003/010
0782/0782 [=============================] - 38ms/step - loss: 0.117543 - accuracy: 0.957600 - val_loss: 0.483040 - val_accuracy: 0.842240
Epoch: 004/010
0782/0782 [=============================] - 40ms/step - loss: 0.072301 - accuracy: 0.975040 - val_loss: 0.500140 - val_accuracy: 0.847560
Epoch: 005/010
0782/0782 [=============================] - 38ms/step - loss: 0.049823 - accuracy: 0.982840 - val_loss: 0.623955 - val_accuracy: 0.840840
Epoch: 006/010
0782/0782 [=============================] - 39ms/step - loss: 0.036376 - accuracy: 0.987880 - val_loss: 0.666135 - val_accuracy: 0.840640
Epoch: 007/010
0782/0782 [=============================] - 40ms/step - loss: 0.022145 - accuracy: 0.992160 - val_loss: 0.672841 - val_accuracy: 0.836680
Epoch: 008/010
0782/0782 [=============================] - 44ms/step - loss: 0.021390 - accuracy: 0.993160 - val_loss: 0.828898 - val_accuracy: 0.836400
Epoch: 009/010
0782/0782 [=============================] - 46ms/step - loss: 0.016587 - accuracy: 0.994160 - val_loss: 0.974426 - val_accuracy: 0.824280
Epoch: 010/010
0782/0782 [=============================] - 45ms/step - loss: 0.018890 - accuracy: 0.993720 - val_loss: 0.910295 - val_accuracy: 0.831920
Elapsed time: 471.4702801 seconds
结果对比
| 训练平台 | 训练集准确率 | 验证集准确率 | 训练时长(秒) |
|---|---|---|---|
| Transformer (Python Keras) | 0.995 | 0.835 | 768.91 |
| Transformer (Tensorflow.NET) | 0.994 | 0.832 | 471.47 |
结果显示,这两个平台的模型在训练和验证集上取得了相似的准确率,表明基于TensorFlow.NET实现Transformer基本模型在预测性能上对齐了Keras官方实现Text classification with Transformer。此外,Tensorflow.NET在训练时长方面表现更佳,仅需471.47秒,而Python Keras则需要768.91秒。这表明Tensorflow.NET相较于python平台的优越性。
加载与推理
调用IModel的load_weights方法:model.load_weights(path + @"\weights.h5");即可完成模型参数加载。
示例函数
public void TextClassificationLoadAndPredictAndEval()
{
var transformer = new TransformerClassification(new TransformerClassificationArgs
{
});
string save_path = @"C:\Users\{user name}\AppData\Local\Temp\imdb\model";
IModel model = transformer.Load(save_path);
model.summary();
var cfg = new TransformerClassificationConfig();
var dataloader = new IMDbDataset(cfg); //the dataset is initially downloaded at TEMP dir, e.g., C:\Users\{user name}\AppData\Local\Temp\imdb\imdb.npz
var dataset = dataloader.GetData();
var x_train = dataset[0].slice(new Tensorflow.Slice(0,5));
Console.WriteLine("Predict Input:" + x_train);
var output = transformer.Predict(model, x_train);
Console.WriteLine("Predict Output:" + output);
transformer.Evaluate(model);
}
推理结果
加载已经训练好的模型后,使用预测用例,进行模型推理,结果如下:
| Comment (Input Data) | Label | Inference (Negative/Positive) |
|---|---|---|
| this film was just brilliant casting location scenery story direction everyone’s really suited the part they played and you could just imagine being there robert is an amazing actor and now the same being director father came from the same scottish island as myself so i loved the fact there was a real connection with this film the witty remarks throughout the film were great it was just brilliant so much that i bought the film as soon as it was released for retail and would recommend it to everyone to watch and the fly fishing was amazing really cried at the end it was so sad and you know what they say if you cry at a film it must have been good and this definitely was also congratulations to the two little boy’s that played the of norman and paul they were just brilliant children are often left out of the praising list i think because the stars that play them all grown up are such a big profile for the whole film but these children are amazing and should be praised for what they have done don’t you think the whole story was so lovely because it was true and was someone’s life after all that was shared with us all | Positive | Positive [0.012264262, 0.9877358] |
| big hair big boobs bad music and a giant safety pin these are the words to best describe this terrible movie i love cheesy horror movies and i’ve seen hundreds but this had got to be on of the worst ever made the plot is paper thin and ridiculous the acting is an abomination the script is completely laughable the best is the end showdown with the cop and how he worked out who the killer is it’s just so damn terribly written the clothes are sickening and funny in equal measures the hair is big lots of boobs bounce men wear those cut tee shirts that show off their sickening that men actually wore them and the music is just trash that plays over and over again in almost every scene there is trashy music boobs and taking away bodies and the gym still doesn’t close for all joking aside this is a truly bad film whose only charm is to look back on the disaster that was the 80’s and have a good old laugh at how bad everything was back then | Negative | Negative [0.9114965, 0.08850345] |
| this has to be one of the worst films of the 1990s when my friends i were watching this film being the target audience it was aimed at we just sat watched the first half an hour with our jaws touching the floor at how bad it really was the rest of the time everyone else in the theatre just started talking to each other leaving or generally crying into their popcorn that they actually paid money they had working to watch this feeble excuse for a film it must have looked like a great idea on paper but on film it looks like no one in the film has a clue what is going on crap acting crap costumes i can’t get across how this is to watch save yourself an hour a bit of your life | Negative | Negative [0.98951495, 0.010485013] |
| the scots excel at storytelling the traditional sort many years after the event i can still see in my mind’s eye an elderly lady my friend’s mother retelling the battle of she makes the characters come alive her passion is that of an eye witness one to the events on the heath a mile or so from where she lives br br of course it happened many years before she was born but you wouldn’t guess from the way she tells it the same story is told in bars the length and of scotland as i discussed it with a friend one night in a local cut in to give his version the discussion continued to closing time br br stories passed down like this become part of our being who doesn’t remember the stories our parents told us when we were children they become our invisible world and as we grow older they maybe still serve as inspiration or as an emotional reservoir fact and fiction blend with role models warning stories magic and mystery br br my name is like my grandfather and his grandfather before him our protagonist introduces himself to us and also introduces the story that stretches back through generations it produces stories within stories stories that evoke the impenetrable wonder of scotland its rugged mountains shrouded in the stuff of legend yet is rooted in reality this is what gives it its special charm it has a rough beauty and authenticity tempered with some of the finest gaelic singing you will ever hear br br angus visits his grandfather in hospital shortly before his death he burns with frustration part of him yearns to be in the twenty first century to hang out in but he is raised on the western among a gaelic speaking community br br yet there is a deeper conflict within him he yearns to know the truth the truth behind his ancient stories where does fiction end and he wants to know the truth behind the death of his parents br br he is pulled to make a last fateful journey to the of one of most mountains can the truth be told or is it all in stories br br in this story about stories we revisit bloody battles poisoned lovers the folklore of old and the sometimes more treacherous folklore of accepted truth in doing so we each connect with angus as he lives the story of his own life br br the pinnacle is probably the most honest unpretentious and genuinely beautiful film of scotland ever made like angus i got slightly annoyed with the pretext of hanging stories on more stories but also like angus i this once i saw the picture ’ forget the box office pastiche of braveheart and its like you might even the justly famous of the wicker man to see a film that is true to scotland this one is probably unique if you maybe on it deeply enough you might even re evaluate the power of storytelling and the age old question of whether there are some truths that cannot be told but only experienced | Positive | Positive [0.023468638, 0.97653145] |
| worst mistake of my life br br i picked this movie up at target for 5 because i figured hey it’s sandler i can get some cheap laughs i was wrong completely wrong mid way through the film all three of my friends were asleep and i was still suffering worst plot worst script worst movie i have ever seen i wanted to hit my head up against a wall for an hour then i’d stop and you know why because it felt damn good upon bashing my head in i stuck that damn movie in the and watched it burn and that felt better than anything else i’ve ever done it took american psycho army of darkness and kill bill just to get over that crap i hate you sandler for actually going through with this and ruining a whole day of my life | Negative | Negative [0.9743731, 0.025626888] |
可见经过训练后,模型可以很好的完成推理任务。对测试的5条电影评论的情感推断全部正确。
评估结果
加载已经训练好的模型后,使用评估用例,进行模型评估,输入数据为IMDB验证集,前5个batch的评估结果如下:
0001/0782 - 92ms/step - loss: 0.453511 - accuracy: 0.843750
0002/0782 - 78ms/step - loss: 0.337446 - accuracy: 0.875000
0003/0782 - 110ms/step - loss: 0.327551 - accuracy: 0.885417
0004/0782 - 77ms/step - loss: 0.326336 - accuracy: 0.882812
0005/0782 - 52ms/step - loss: 0.328271 - accuracy: 0.881250
ess and kill bill just to get over that crap i hate you sandler for actually going through with this and ruining a whole day of my life | Negative | Negative
[0.9743731, 0.025626888] |
可见经过训练后,模型可以很好的完成推理任务。对测试的5条电影评论的情感推断全部正确。
评估结果
加载已经训练好的模型后,使用评估用例,进行模型评估,输入数据为IMDB验证集,前5个batch的评估结果如下:
0001/0782 - 92ms/step - loss: 0.453511 - accuracy: 0.843750
0002/0782 - 78ms/step - loss: 0.337446 - accuracy: 0.875000
0003/0782 - 110ms/step - loss: 0.327551 - accuracy: 0.885417
0004/0782 - 77ms/step - loss: 0.326336 - accuracy: 0.882812
0005/0782 - 52ms/step - loss: 0.328271 - accuracy: 0.881250
可见,对加载模型的评估结果与训练结果相近,验证了模型保存加载的正确性与模型在文本分类问题上的有效性。















 7126
7126











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









