







本文并非博主原创,是由博主翻译,并删减部分类容。
原文信息如下:
Mining User Similarity Based on Location History
Quannan Li1,2, Yu Zheng2, Xing Xie2,Yukun Chen2, Wenyu Liu1, Wei-Ying Ma2
1Dept. Electronics and Information Engineering, Huazhong University of Science and Technology,
Wuhan, 430074, P.R. China
2Microsoft Research Asia
4F, Sigma Building, No.49 Zhichun Road, Haidian District, Beijing 100190, P. R. China
1liuwy@mail.hust.edu.cn
2{v-quali, yuzheng, xingx, v-yukche, wyma}@microsoft.com
Permission to make digital or hard copies of all or part of this work for
personal or classroom use is granted without fee provided that copies are
not made or distributed for profit or commercial advantage, and that
copies bear this notice and the full citation on the first page. To copy
otherwise, to republish, to post on servers or to redistribute to lists,
requires prior specific permission and/or a fee.
ACM GIS '08, November 5-7, 2008. Irvine, CA, USA
© 2008 ACM ISBN 978-1-60558-323-5/08/11…$5.00"
原文下载链接:https://download.csdn.net/download/qq_21768483/10660098
1.概述
定位获取技术发展(GPS,GSM网络等)使人们可以方便地记录他们用时空数据访问的位置历史。收集大量与个人的轨迹有关地理信息,也给我们从这些轨迹中发现有价值的知识带来了我们机遇和挑战。在本文中,我们目的是基于他们的轨迹挖掘相似性用户之间。这样的用户相似性对于个人,社区和企业通过帮助他们有效地检索相关性高的信息。我们提出了一种基于层次图的相似度度量(HGSM,hierarchical-graph based similarity measurement)框架地理信息系统一致地建模每个个体并对个体的轨迹进行了有效的相似性度量。在这个框架中,我们同时考虑了人的运动行为的序列性质和地理空间的层次属性。我们评估这个框架使用GPS数据收集65名志愿者在6个月的时间。因此,HGSM优于相关的相似性度量,如余弦相似性和皮尔森相似性度量。
2.整体框架结构
2.1预定义
GPS日志和GPS轨迹: 基本上,如下图所示,图1中的GPS日志是GPS点P={p1, p2,…,pn }。每个GPS点pi P包含纬度(pi. lat)、经度(pi.Lngt)和时间戳(pi.T)。如图1所示,在二维平面上,我们可以连接这些GPS根据时间序列指向GPS轨迹(Traj)。
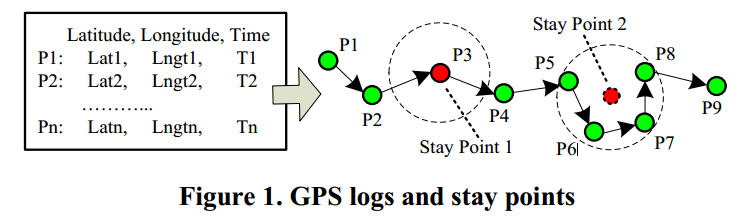
** 停留点: **停留点S代表一个地理区域用户呆了一会儿。与原始GPS点相比,每一个点停留点具有特定的语义含义,如地点
我们工作/生活,我们参观的餐厅和我们旅行的地点,等等。图1展示了两类停留点。在一个情况,比如停留点1,停留点发生在P3个体在超过阈值的一段时间内保持静止。
使用图2所示的算法,这些停留点可以是自动检测从用户的GPS轨迹通过寻找用户花费超过a的时间的空间区域一定的阈值。例如,在我们的实验中,如果一个人在200米的距离内花了30多分钟检测区域作为停留点。我们提取每一个停留点包含关于平均坐标、到达时间(S.arvT)的信息离开时间(S.levT)。
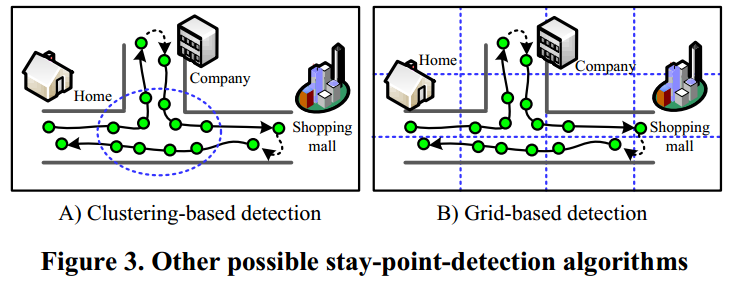
我们用这种方法检测停留点的原因有两方面。一方面,如果我们直接对它们进行聚类,如图3-A所示,我们将会错过个人GPS日志一些重要的地方,如家庭和购物中心。随着全球定位系统(GPS)在室内,设备会丢失卫星信号,GPS点也会很少
在这些地方生成(如图1所示,停留点1)。因此,记录到的点的密度不能满足形成集群的条件。相反,一些地区,就像道路交叉口,用户反复通过但不携带有意义的信息反而会被提取。此外,计算由于GPS点的数量,聚类的数量与停留点相比是相当大的。另一方面,如图3-B)所示,如果基于网格划分方法的边界问题也可能导致漏掉重要的地方。

** 位置历史: **位置历史是一个位置的记录。在一段时间内在地理空间访问的实体。给定停留点轨迹,一个人的位置历史可以表示为他们访问过的一系列地方和相应的到达时间和离开时间。然而,不同人的停留点轨迹是不一致的,所以不能直接比较停留点轨迹的相似性。直接测量两个停留点之间的距离来作为相似度度量的手段是片面的。此外,用户相似性不是二进制的值,即不能相同和不同来表示。
** 层次图: **为了解决这个问题,我们提出了一种层次图的概念。见图4,我们将所有用户的停留点分层地以空间区域(集群)的方式分裂成更小的空间区域。因此,相似的停留点不同的用户将被分配到不同的集群层。在层次结构的每一层上,有个人停留点轨迹,每个用户可以建立一个有向图,其中,图中节点是用户的停留点所在层次图的空间区域(集群)的编号和图的边代表层次图的空间区域(集群)序列。因此,用户的等级图(HG)可以表示为构建在其上的一组图,不同的地理空间尺度。每个图Gi HG包含一组顶点和边,Gi=(V, E),而V={C}是一组簇它包含用户的停留点。
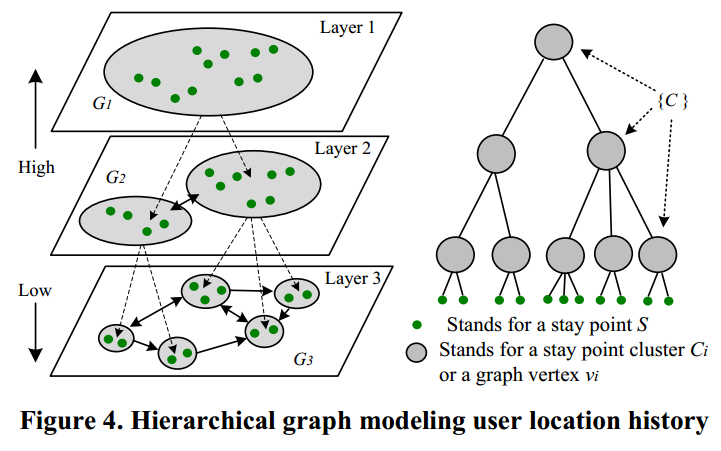
人的轨迹表现为高度的时空轨迹规律性。每个人的特征可以描述成是时间无关行程距离和少数高频出现的位置。相比之下使用预先定义的网格或行政区域的方法构建层次结构并非数据驱动的方式而是包含了认为的定义,而我们使用层次图对用户生成的停留点进行聚类是一种datadriven(数据驱动)方法,它可以描述用户的分布。时空数据,可以发现富含意义区域和富含意义不规则的结构。
使用这个层次图,我们可以一致的建模个人的位置历史并用它来度量用户不同地理空间尺度的相似性。层次结构从上到下在,集群的空间尺度减小,地理区域的粒度从粗到细因此层次图对于度量不通用和的相似性来书是必要的,用层次图建模后的用轨迹,其所在的层次图中越靠下的层次起相似性越高。
2.2 基于层次图的相似度度量的整体架构图
图5给出了HGSM体系结构的概述包括三个过程:位置历史展示,用户相似性探索和朋友和位置推荐。在
本文主要研究用户相似度的探索,将在第3节详细介绍。
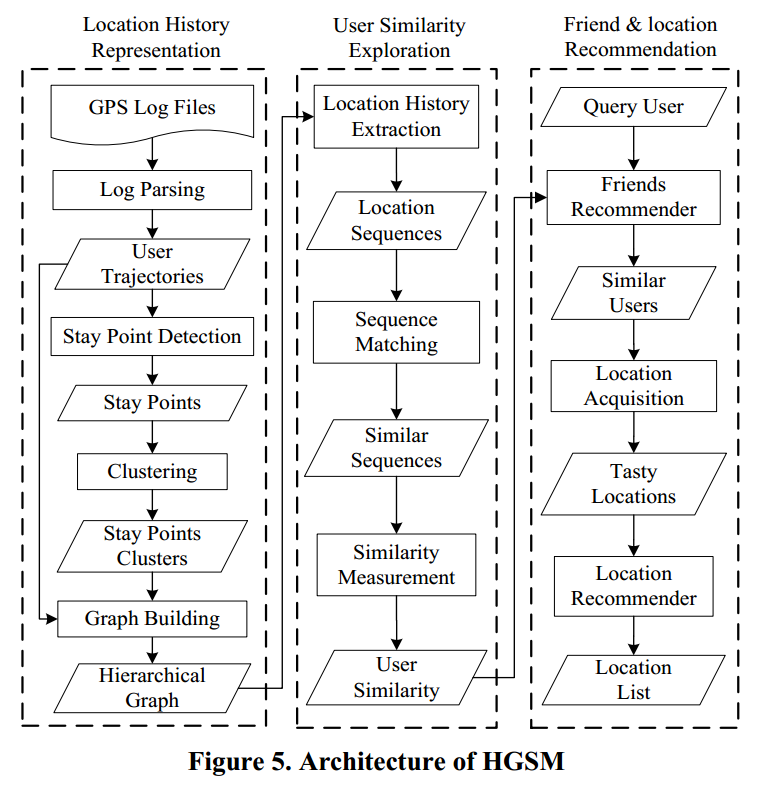
2.2.1轨迹表示
如左图所示,给定一组GPS日志首先,我们对时空数据进行解析并进行表述每个用户的轨迹。其次,我们提取停留点
每个人的轨迹使用的算法描述如图2,然后把这些停留点放在一起放到数据集中,我们将数据集以空间区域(集群)的方式分裂成更小的空间区域。下层集群是从上层集群划分出来的。聚类完成后的空间区域(集群)中用户的停留点提供了一种不同个体停留点的相似性测量的方法。在换句话说,每个用户在单独一个分层内部都会有一条基于共享层次图框架的停留点簇的轨迹。
2.2.2用户相似性的探索
图5的中间框显示了用户相似度的过程,它可以离线执行的探索。首先,给定两个用户位置历史用同一层层次图中的节点来表示,我们会得到一个该层层次图节点的序列,然后我们搜索两个序列中相同的节点。在层次图中的没一层都会得到一个序列。然后根据用户离开上一个序列时间和到达序列的时间,可以推算出两个节点之间的时间间隔。然后可以基于序列和序列节点之间的时间间隔来分析相似性。分析时有一下两个原则:
- 层次图中,同层节点所得相似序列越长的两个用户相似性越高。
- 不同层次中,越靠近过下层的相似序列的两个用户相似性越高。
计算时不同长度的相似序列被赋予不同的权重,相似序列越长权重越大,越靠近层次图下层的权重越大。将两个用户在各层的计算结果累加,和越大的用户月相似。
2.2.3 相似的人和位置推荐
给定一个用户作为查询,我们可以对社区中的人进行排名。根据他们与用户得分的相似性。然后是一组得分相对较高的人可以被视为有潜力的人为人交朋友。此外,使用它们朋友的位置历史,个人变得更有方便的发现一些,符合他/她的口味的地理区域,如购物中心,餐馆和公园,等。稍后,可以采用任何现有的基于内存的协同推荐算法在这里测量用户对这些位置的兴趣。因此,在本文中,我们更关注用户相似度的测量而不是描述推荐算法的细节。
3. 用户相似探索
在本节中,我们将详细介绍用户相似度的过程勘探,包括区位历史提取、序列提取匹配和相似性度量。
##3.1位置历史提取
层次图提供了一种有效的方式来表示用户的位置历史,他可以表示用户的在不同尺度地理空间的运动行为。在每一层它们的层次图我们首先找到两个用户相同的图节点,然后根据这些节点成一个序列。序列更好的测量两个用户之间的相似性,之后,可以把测量两个用户之间的相似性转化为序列匹配问题。
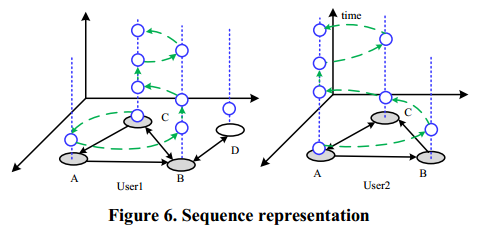
使用两个用户层次图的一层作为案例,图6演示如何从个人历史位置提取序列。在每层图节点上,都有一个蓝色的点(用户历史位置),这些点下方的圆圈表示归属于这个层中层次图的节点。节点的先后顺序由用户到达的先后时间确定。可以看到,用户1和用户2相同的图节点A, B和C,不同的节点D被抛弃。用绿色曲线,我们可以依次按照时间序列将蓝色节点连接到这些图节点上。因此,用户1生成的序列< C, A, B, B, C, C, B, C >。用户2创建序列< A, B, C, A, A, C, A >。为了简单起见,我们将这些序列表示为 < C(1),A(1),B(2),C(2),B(1),C(1)>和< A(1),B(1),C(1),A(2),C(1),A(1)>;图节点后面的数字表示用户连续经过这个节点的次数。给定每个用户的到达时间(S.arvT)和在每个集群上留下时间(S.levT),我们可以计算这些序列中两个项目之间的时间间隔。因此,两个序列可以表示为:
我们可以抽象出一种结构(序列)来重新定义用户历史位置:
a
i
a_i
ai是层次图中的节点,
k
i
k_i
ki是经过节点的次数。
δ
t
i
\delta t_i
δti是
a
i
a_i
ai到
a
i
+
1
a_{i+1}
ai+1的时间间隔。
时间间隔的具体计算方法为:
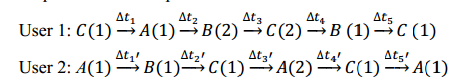
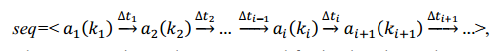
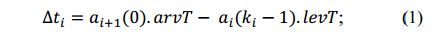
3.2序列匹配
3.2.1相似序列的定义
**相似序列:**满足以下条件的的序列成功为相似序列:
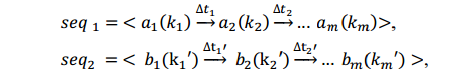
- a i = b i a_i =b_i ai=bi
- ∣ δ t i − δ t i ‘ ∣ < t t h |\delta t_i - \delta t_i^`|< t_th ∣δti−δti‘∣<tth, t t h t_th tth是人为设置合适的时间间隔阈值。
提取出的相似序列如下:
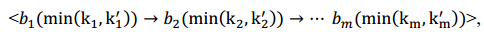
**m长度相似序列:**如果相似序列节点数是m,我们称这个序列为m长度相似序列。
3.2.2相似序列匹配
图8显示了我们为检测给定两个序列中序列相似度而实现的算法。算法包含两个操作:序列扩展和序列修剪。在扩展操作中,我们的目标是将每个mlength相似的序列扩展为(m+1)-length序列。这个操作从找到一个长度为1的相似序列开始。随后,在在修剪操作中,我们挑选出最大长度相似的由扩展生成的候选序列操作并除去其余部分。基本上,扩展和修剪操作将交替实现和迭代直到扫描完序列中的每个节点。然而,它搜索相似序列很长时,这个过程非常耗时。我们观察到相似序列越长它出现的概率越低。因此,为了提高序列匹配的效率,我们设置了一个参数maxLength,用于在相似序列的长度增加到一定的值时停止扩展操作。
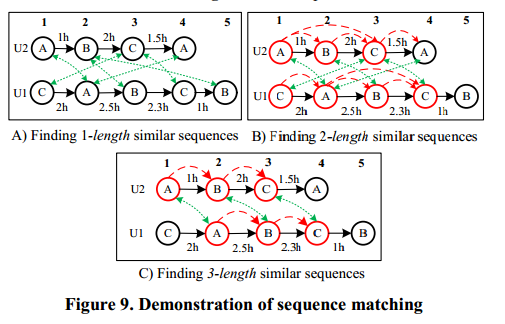
图9展示了上述算法。在这里,每个方框顶部的数字表示在一个序列每个节点的位置。首先,如图9 A所示,我们检测1长度的相似序列如下< A12>, < B23>, < B25 >, < C31>,< C34> 和< A42>,其中每个字符的下标表示每个序列中匹配节点的位置。例如,< A12>表示序列1的第一个节点与序列2的第二个节点,共享相同的节点节点A。第二,图9 B)描述了扩展操作基于第一步的结果。如果我们将时间限制t_th设置为2小时,将会得到4个2长度相似序列包括 < A12, B23>, < A12, C34>, < B23, C34> 和 < C31,A42> 。然后,在剪枝操作中,所有的1-长度序列将从相似序列集中删除(SeqenceSet)因为它们包含在两个长度的序列中。第三,基于2长度序列,一个3长度 < A12, B23, C34> 相似可以被检测到。随后,在修剪操作,除外,其余为2长类似的序列将SeqenceSet中删除。

3.2.3相似度度量
检索到的相似序列用于计算总体序列每个用户对的相似度得分。在计算分数时,我们考虑两个因素:一个相似序列的长度和找到序列的层。首先,我们计算两个用户在某一层发现的每个相似的序列的得分加起来。然后,每一层的分数都将被加权和,总结成最终的分数。
m长的相识序列的相似性度量方法:
a
(
m
)
a_{(m)}
a(m)相关系数随着长度m的增加而增加,例如,在实验中,我们取
a
(
m
)
=
2
m
a_{(m)}=2^m
a(m)=2m
同层中的相相似性:
如式(3)所示,相似度两个用户之间在他们的层次图的某一层的最大长度相似序列来测量的。这里n是两个用户在给定层相似序列的个数。
S
i
S_i
Si是i长相似序列的分数,可根据方程计算(2).,
N
1
N_1
N1和
N
2
N_2
N2分别为两个用户的总序列长度。
相似度除以因子(
N
1
∗
N
2
N_1 * N_2
N1∗N2)是由于用户数据不平衡问题。直观地,用户会产生不同数量的 GPS logs。因此,如果我们不考虑数据的规模,拥有大量数据的个人更有可能更加相似相比于少的那些用户。
总相似度计算:
如式(4)所示,总相似度为用户多层相似度计算为加权和
这里H表示层次图的总层数。
β
i
\beta_i
βi是一个层相关系数,表示支持第l层序列的相似性权重。层级越低的相似序列,权重越高。在我们的实验中,
β
=
2
(
l
−
1
)
。
\beta =2 ^ {(l-1)}。
β=2(l−1)。
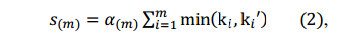
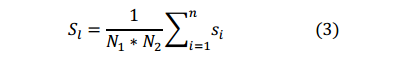
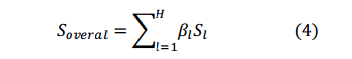















 3867
3867











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









