









Hodoop1.x 到 Hadoop2.x
1、Hadoop 1.x 存在的问题:
– HDFS存在的问题
• NameNode单点故障,难以应用于在线场景
• NameNode压力过大,且内存受限,影响系统扩展性
– MapReduce存在的问题
• JobTracker访问压力大,影响系统扩展性
•难以支持除MapReduce之外的计算框架,比如Spark、Storm等
2、Hadoop 1.x与Hadoop 2.x
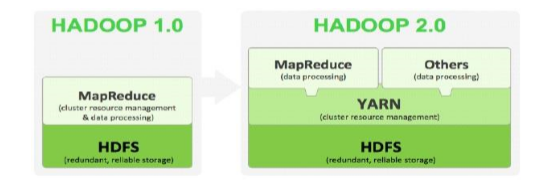
– Hadoop2.x由HDFS、MapReduce和YARN三个分支构成;
• HDFS:NNFederation、HA;
• MapReduce:运行在YARN上的MR;
• YARN:资源管理系统
3、Hadoop 2.x
– 解决HDFS1.0中单点故障和内存受限问题。
– 解决单点故障
• HDFSHA:通过主备NameNode解决
•如果主NameNode发生故障,则切换到备NameNode上
– 解决内存受限问题
•HDFSFederation(联邦)
• 水平扩展,支持多个NameNode;
• 每个NameNode分管一部分目录;
• 所有NameNode共享所有DataNode存储资
– 2.x仅是架构上发生了变化,使用方式不变
– 对HDFS使用者透明
– HDFS1.x中的命令和API仍可以使用
Hadoop 2.x HA
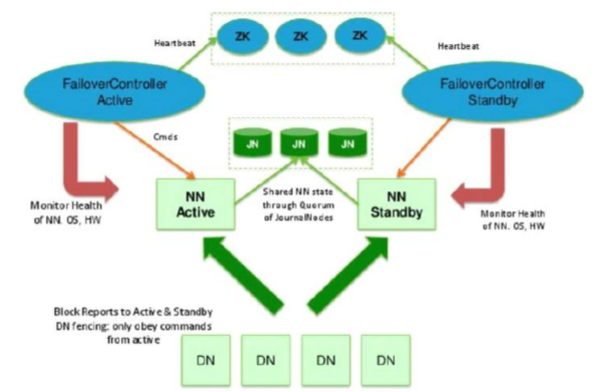
1、HDFS 2.0 HA
– 主备NameNode
– 解决单点故障
• 主NameNode对外提供服务,备NameNode同步主NameNode元数据, 以待切换
• 所有DataNode同时向两个NameNode汇报数据块信息
– 两种切换选择
• 手动切换:通过命令实现主备之间的切换,可以用HDFS升级等场合
• 自动切换:基于Zookeeper实现
– 基于Zookeeper自动切换方案
•ZookeeperFailoverController:监控NameNode健康状态,
• 并向Zookeeper注册NameNode
• NameNode挂掉后,ZKFC为NameNode竞争锁,获得ZKFC锁
• 的NameNode变为active
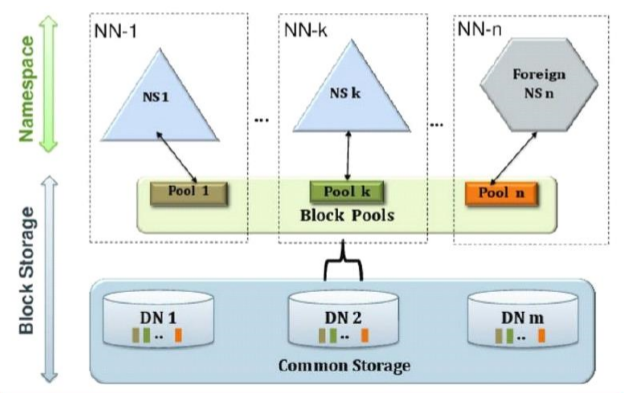
2、HDFS 2.x Federation
– 通过多个namenode/namespace把元数据的存储和管理分散到多个 节点中,使到namenode/namespace可以通过增加机器来进行水平 扩展。
– 能把单个namenode的负载分散到多个节点中,在HDFS数据规模较大 的时候不会也降低HDFS的性能。可以通过多个namespace来隔离不 同类型的应用,把不同类型应用的HDFS元数据的存储和管理分派到不 同的namenode中。
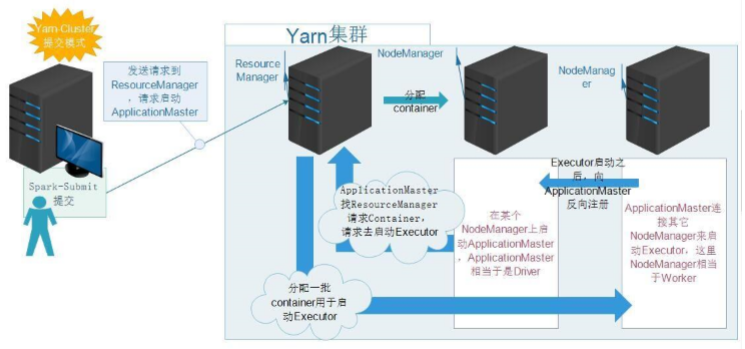
3、yarn
– YARN:YetAnotherResourceNegotiator;
– Hadoop2.0新引入的资源管理系统,直接从MRv1演化而来的;
• 核心思想:将MRv1中JobTracker的资源管理和任务调度两个功能分开, 分别由ResourceManager和ApplicationMaster进程实现
•ResourceManager:负责整个集群的资源管理和调度
•ApplicationMaster:负责应用程序相关的事务,比如任务调度、任务监控和容错等
– YARN的引入,使得多个计算框架可运行在一个集群中
• 每个应用程序对应一个ApplicationMaster
• 目前多个计算框架可以运行在YARN上,比如MapReduce、Spark、 Storm等
4、MapReduce On YARN
–MapReduceOnYARN:MRv2
– 将MapReduce作业直接运行在YARN上,而不是由JobTracker和TaskTracker构建的 MRv1系统中
– 基本功能模块
• YARN:负责资源管理和调度
• MRAppMaster:负责任务切分、任务调度、任务监控和容错等
•MapTask/ReduceTask:任务驱动引擎,与MRv1一致
– 每个MapRduce作业对应一个MRAppMaster
• MRAppMaster任务调度
• YARN将资源分配给MRAppMaster
• MRAppMaster进一步将资源分配给内部的任务
– MRAppMaster容错
• 失败后,由YARN重新启动
• 任务失败后,MRAppMaster重新申请资源
5、实现HA的本质:
1> fsimage (active NameNode格式化之后将fsimage复制给standbyNameNode)
2> edits (通过journalNode同步)
6、先决条件:zookeeper集群
1>作用
1> 监控NN 状态并汇报给Zookeeper
2> 将 standby 转换为 active
2> 搭建
|
| NN | DN | JN | ZK | ZKFC zookeeper failover controller |
| Node3 | 1 |
|
| 1 | 1 |
| Node4 | 1 | 1 | 1 | 1 | 1 |
| Node5 |
| 1 | 1 | 1 |
|
| Node6 |
| 1 | 1 |
|
|
如上,node3、node4和node5安装Zookeeper
步骤:a.解压tar包:tar -zxvf zookeeper-3.4.6.tar.gz
b.修改zoo.conf文件(在conf目录下将zoo_sample.cfg重命名或者新建)
tickTime=2000
dataDir=/opt/zookeeper/data #(目录需要手动创建,myid文件放该目录下)
dataLogDir=/opt/zookeeper/dataLog #(此条可以不写)
clientPort=2181
initLimit=5
syncLimit=2
server.1=node3:2888:3888 #需要添加
server.2=node4:2888:3888
server.3=node5:2888:3888
myid的内容依据zoo.conf,如node3的myid内容为数字1,node4的为2
c.同步三台机器的zoo.conf配置文件
将Zookeeper配置到系统环境中:
vi ~/.bash_profile (添加以下两行)
exportZOOKEEPER=/usr/hadoopsoft/zookeeper-3.4.6
export PATH=$PATH:$ZOOKEEPER/bin
source ~/.bash_profile
启动命令:
zkServer.sh start
7、搭建
|
| NN | DN | JN | ZK | ZKFC zookeeper failover controller |
| Node3 | 1 |
|
| 1 | 1 |
| Node4 | 1 | 1 | 1 | 1 | 1 |
| Node5 |
| 1 | 1 | 1 |
|
| Node6 |
| 1 | 1 |
|
|
搭建步骤:
1、 主机,修改hosts,网络 – 网络连接、关闭防火墙
2、 时间同步
3、 Jdk配置环境变量
4、 下载tar 解压
5、etc/hadoop/hadoop-env.sh
修改export JAVA_HOME=/usr/java/ jdk1.7.0_79
6、 免密钥配置
$ ssh-keygen -t dsa -P '' -f ~/.ssh/id_dsa
$ cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys
Node3 与Node4
Node3 、Node4分别与其他几个节点
7、 修改配置文件
!!!masters配置文件必须删除所有节点!!!
slaves 配置的是DN(DataNode)

core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name> HDFS命名空间名称
<value>hdfs://sxt</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/hadoop</value>
</property>
</configuration>
以下按照官方文档修改、添加
HDFS High Availability Using the Quorum JournalManager
hdfs-site.xml
<property>
<name>dfs.nameservices</name> 命名空间名称
<value>sxt</value>
</property>
<property>
<name>dfs.ha.namenodes.sxt</name> 两台NN别名
<value>nn1,nn2</value>
</property>
<property>
<name>dfs.namenode.rpc-address.sxt.nn1</name> NN RPC访问端口
<value>node1:8020</value>
</property>
<property>
<name>dfs.namenode.rpc-address.sxt.nn2</name>
<value>node2:8020</value>
</property>
<property>
<name>dfs.namenode.http-address.sxt.nn1</name> NN HTTP访问端口
<value>node1:50070</value>
</property>
<property>
<name>dfs.namenode.http-address.sxt.nn2</name>
<value>node2:50070</value>
</property>
<property>
<name>dfs.namenode.shared.edits.dir</name> 执行JN集群 <value>qjournal://node4:8485;node5:8485;node6:8485/sxt</value>
</property>
<property>
<name>dfs.client.failover.proxy.provider.sxt </name> NN自动切换 <value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<property>
<name>dfs.ha.fencing.methods</name> 指定ssh认证以及私钥文件
<value>sshfence</value>
</property>
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/root/.ssh/id_dsa</value> 要配置为自己主机私钥文件(ssh加密方式不同需要修改id_dsa)
</property>
<property>
<name>dfs.journalnode.edits.dir</name> JN节点上edits文件存放目录
<value>/opt/journal/data</value>
</property>
注:以上配置中的红色“sxt”为hdfs命名空间名称,可全部替换为自己的命名
vi ~/.bash_profile (将hadoop配置到环境中)
export JAVA_HOME=/usr/java/jdk1.7.0_79
export PATH=$PATH:$JAVA_HOME/bin
exportCLASSPATH=.:/lib/dt.jar:/lib/tools.jar
exportHADOOP_HOME=/usr/hadoopsoft/hadoop-2.5.1
exportPATH=$PATH:$HADOOP_HOME/bin
exportPATH=$PATH:$HADOOP_HOME/sbin
exportZOOKEEPER=/usr/hadoopsoft/zookeeper-3.4.6
export PATH=$PATH:$ZOOKEEPER/binsource ~/.bash_profile
source ~/.bash_profile
同步配置文件!!
检查目录是否存在/opt/hadoop 全部删除
操作::
首先启动所有的JN hadoop-daemon.sh start journalnode
然后选一台NN 执行格式化命令 hdfs namenode -format
接着启动 这台NN hadoop-daemon.sh start namenode
最后在另外一台NN 执行同步命令 hdfs namenode -bootstrapStandby
配置HDFS中关于ZK的内容
修改hdfs-site.xml
<property>
<name>dfs.ha.automatic-failover.enabled</name> 启动自动切换设置为true
<value>true</value>
</property>
修改core-site.xml
<property>
<name>ha.zookeeper.quorum</name> 指定zk集群
<value>node3:2181,node4:2181,node5:2181</value>
</property>
操作:
启动zk,同时一起启动三台
zkServer.sh start
在其中一台NN上执行格式化zk命令 hdfs zkfc -formatZK
停止之前启动的节点
启动dfsstart-dfs.sh
HDFS HA搭建完成以后
重启时,首先需要启动zk 再执行hdfs启动脚本
MR—Hadoop核心组件
– Hadoop 分布式计算框架(MapReduce)
1、MapReduce设计理念
–何为分布式计算。
–移动计算,而不是移动数据。
2、计算框架MR
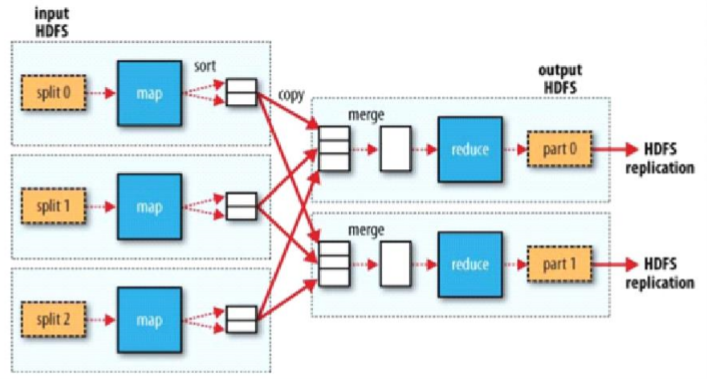

3、MapReduce的 Split大小
– max.split(100M)
– min.split(10M)
– block(64M)
– max(min.split,min(max.split,block))
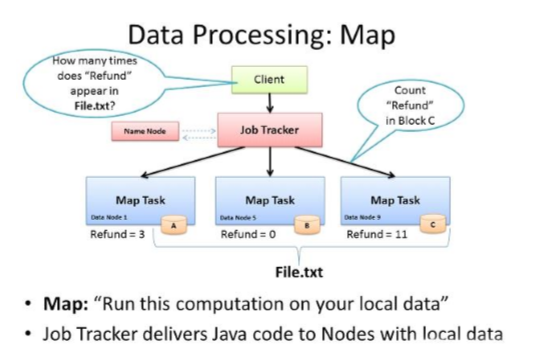
4、Mapper
– Map-reduce的思想就是“分而治之”
• Mapper负责“分”,即把复杂的任务分解为若干个“简单的任务”执行
–“简单的任务”有几个含义:
• 数据或计算规模相对于原任务要大大缩小;
• 就近计算,即会被分配到存放了所需数据的节点进行计算;
• 这些小任务可以并行计算,彼此间几乎没有依赖关系
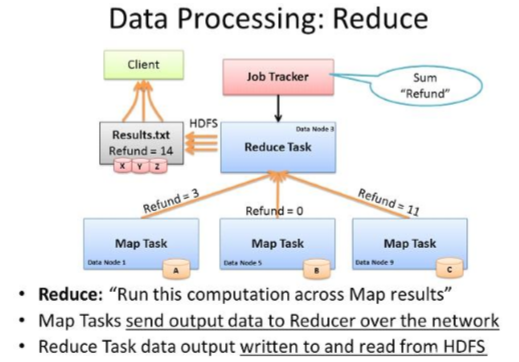
5、Hadoop计算框架Reducer
–对map阶段的结果进行汇总。
– Reducer的数目由mapred-site.xml配置文件里的项目mapred.reduce.tasks 决定。缺省值为1,用户可以覆盖之
6、Hadoop计算框架Shuffler
–在mapper和reducer中间的一个步骤
–可以把mapper的输出按照某种key值重新切分和组合成n份,把key值符合某种范围的输出送到特定的reducer那里去处理
–可以简化reducer过程
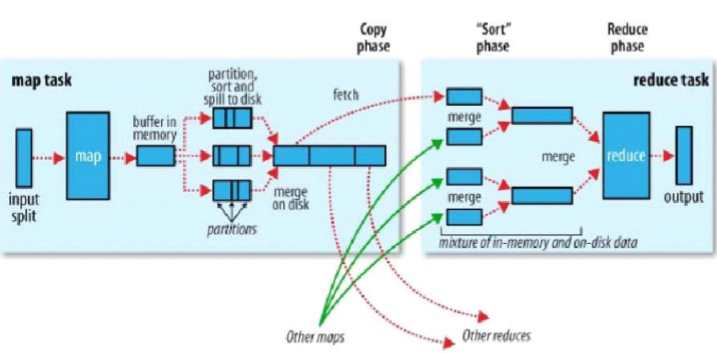
Hadoop计算框架shuffle过程详解
– 每个map task都有一个内存缓冲区(默认是100MB),存储着map的输出结果
– 当缓冲区快满的时候需要将缓冲区的数据 以一个临时文件的方式存放到磁盘(Spill)
– 溢写是由单独线程来完成,不影响往缓冲 区写map结果的线程(spill.percent,默认是 0.8)
– 当溢写线程启动后,需要对这80MB空间内 的key做排序(Sort)
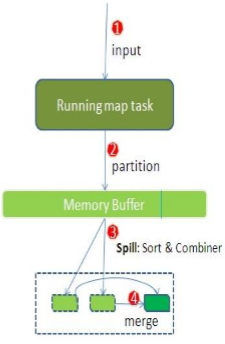
–假如client设置过Combiner,那么现在就是使用Combiner的时候了。将有相同key的key/value对的value加起来,减少溢写到磁盘的数据量。( reduce1,word1,[8])。
–当整个map task结束后再对磁盘中这个map task产生的所有临时文件做合并(Merge),对于“word1”就是像这样的:{“word1”, [5, 8, 2, …]},假如有Combiner,{word1 [15]},最终产生一个文件。
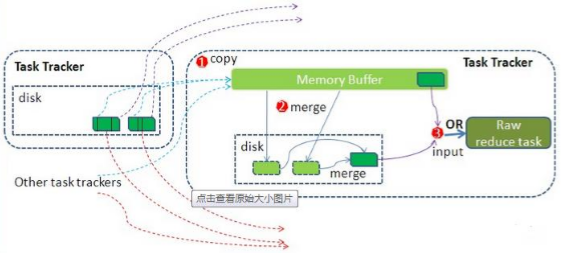
– reduce 从tasktrackercopy数据
– copy过来的数据会先放入内存缓冲区中,这里的缓冲区大小要比map端的更为灵活,它基于JVM的heap size设置
– merge有三种形式:1)内存到内存 2)内存到磁盘 3)磁盘到磁盘。merge 从不同tasktracker上拿到的数据,{word1 [15,17,2]}
–参考博客http://langyu.iteye.com/blog/992916?page=3#comments
7、MapReduce的架构
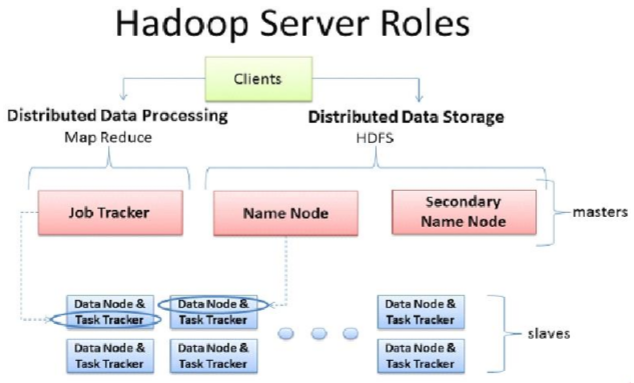
–一主多从架构
–主 JobTracker: ResourceManager
• 负责调度分配每一个子任务task运行于TaskTracker上,如果发现有失败的task就重新分配其任务到其他节点。每一个hadoop集群中只一个JobTracker, 一般它运行在Master节点上。
–从TaskTracker:NodeManager
• TaskTracker主动与JobTracker通信,接收作业,并负责直接执行每一个任务 ,为了减少网络带宽TaskTracker最好运行在HDFS的DataNode上
MR搭建、HA
|
| NN | DN | JN | ZK | ZKFC zookeeper failover controller | RS |
| Node1 | 1 |
|
| 1 | 1 |
|
| Node2 | 1 | 1 | 1 | 1 | 1 |
|
| Node3 |
| 1 | 1 | 1 |
| 1 |
| Node4 |
| 1 | 1 |
|
| 1 |
停掉HA集群
stop-dfs.sh
修改配置文件:
mapred-site.xml:
<configuration>
<property>
<name>mapreduce.framework.name</name> mr框架运行在yarn上,通过yarn做资源管理
<value>yarn</value>
</property>
</configuration>
yarn-site.xml:
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
ResourceManager NodeManager主从结构
RS存在单点故障问题 所以要对他做HA 通过zk
修改yarn-site.xml配置文件
<property>
<name>yarn.resourcemanager.ha.enabled</name> 启用ha 设置为true
<value>true</value>
</property>
<property>
<name>yarn.resourcemanager.cluster-id</name> 名称要与之前namespace不同(之前我设置了“sxt”)
<value>cluster1</value>
</property>
<property>
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>rm1,rm2</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm1</name> 分别指定两台rm
<value>node5</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm2</name>
<value>node6</value>
</property>
<property>
<name>yarn.resourcemanager.zk-address</name> 指定zk集群
<value>node3:2181,node4:2181,node5:2181</value>
</property>
操作
停止之前的hdfs ha集群
stop-dfs.sh
启动Zookeeper集群:zkServer.sh start (在zk每一台机器上执行)
启动集群:start-all.sh(在一台机器上执行)
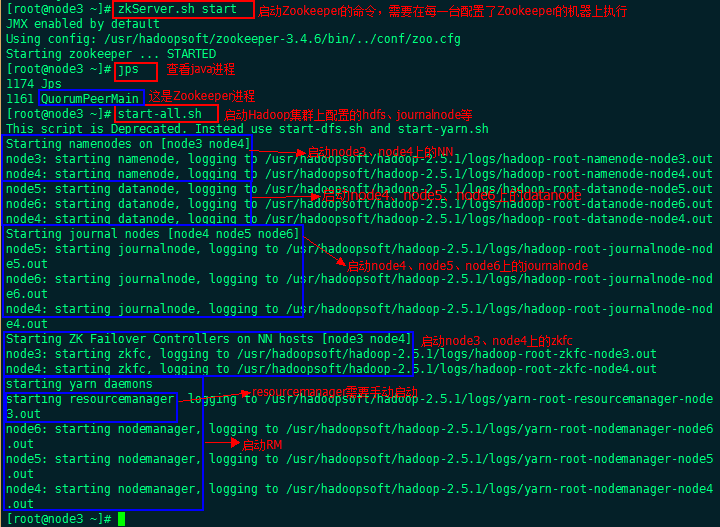
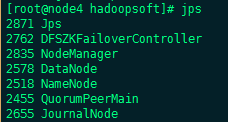
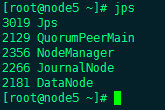
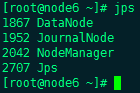
Rs会在你运行启动命令的节点 启动
Rs需要手动来启动,两台分别执行一下命令
yarn-daemon.sh start resourcemanager
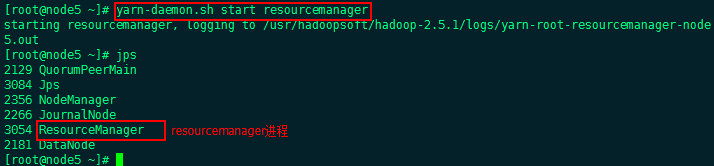
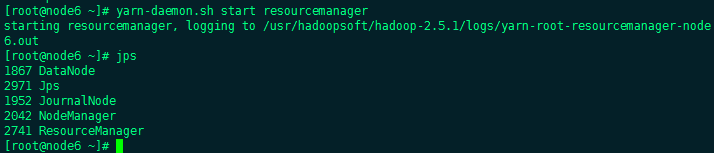
Hadoop集群搭建完成
启动
启动Zookeeper集群,每台机器执行命令: zkServer.sh start
start-all.sh
手动启动RS,两台配置了resourcemanager的机器:yarn-daemon.sh start resourcemanager
浏览器访问node3:50070
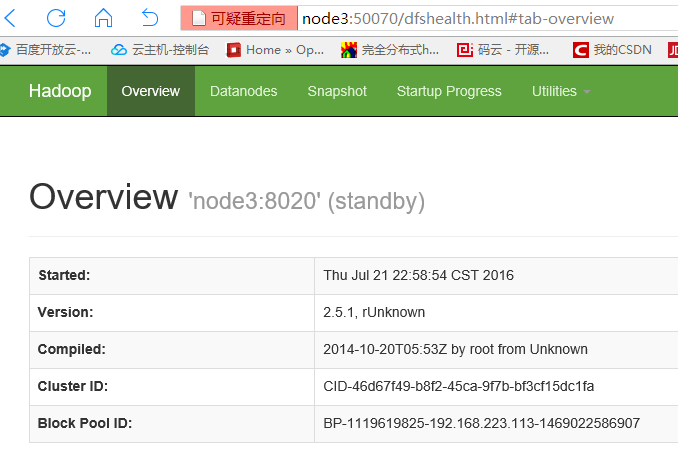
访问node4:50070
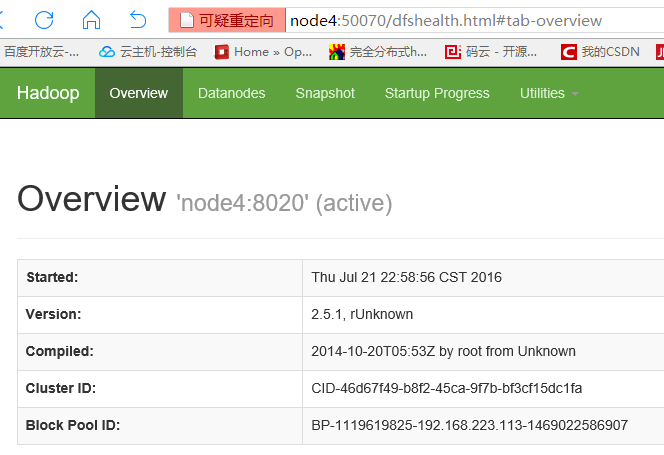
可以手动停止处于active状态的node4的NN进程:hadoop-daemons.shstop namenode
启动:hadoop-daemons.shstart namenode
再次浏览器访问node3和node4的50070端口查看状态
访问node5:8088(RM)

如图,此时node5的RM处于standby状态将自动重定向到active状态的node6
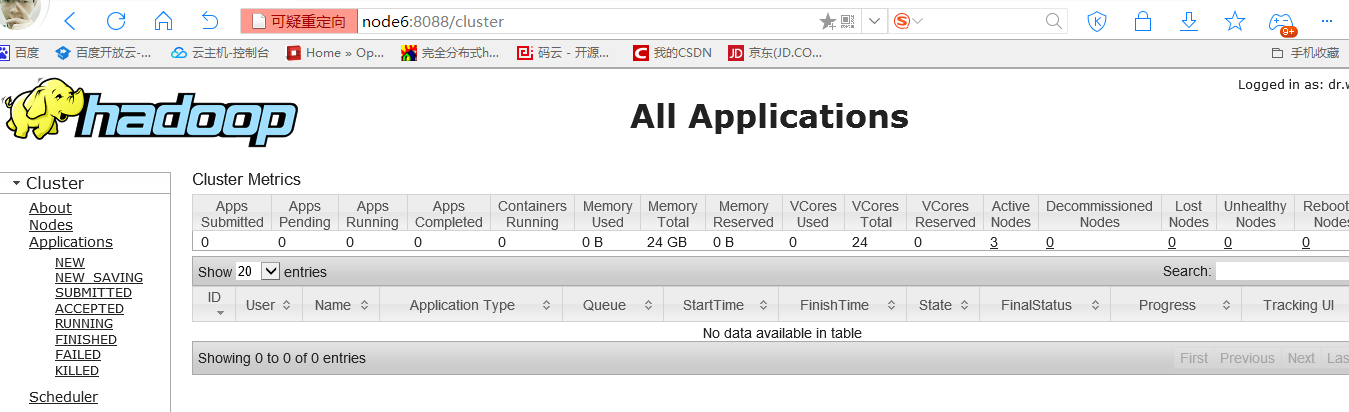
手动停止node6的RM进程:yarn-deamon.sh stop resourcemanager
启动命令:yarn-deamon.sh start resourcemanager
再次访问node5和node6的8088端口,可以看出active状态的机器已经改变
至此,HDFS HA与MR HA已经搭建完成
停止
stop-all.sh
zkServer.sh stop















 907
907

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









