







一 背景
大抵是去年底吧,收到了几个公众号读者的信息,希望能写几篇介绍下Attention以及Transformer相关的算法的文章,当时的我也是满口答应了,但是确实最后耽误到了现在也没有写。
前一阵打算写这方面的文章,不过发现一个问题,就是如果要介绍Transformer,则必须先介绍Self Attention,亦必须介绍下Attention,以及Encoder-Decoder框架,以及GRU、LSTM、RNN和CNN,所以开始漫长的写作之旅。
截止目前,已经完成几篇文章的输出
- 《白话机器学习-卷积神经网络CNN》
- 《白话机器学习-循环神经网络RNN》
- 《白话机器学习-长短期记忆网络LSTM》
- 《白话机器学习-循环神经网络概述从RNN到LSTM再到GRU》
- 《白话机器学习-Encoder-Decoder框架》
那么接下来,需要把Attention机制、Self Attention以及Transformer一一介绍了。
本文主要介绍Attention机制。
那么为何要引入Attention呢,个人认为主要有几点:
- 更长时间的依赖,尽管LSTM与GRU也可以解决这个问题,但是有一定的缺陷
- LSTM与GRU是顺序串行计算的模式,计算的性能有所限制
- Attention可以实现不同时序数据间的关联,同时由于网络结构可以实现并行矩阵计算。
所以从计算性能和模型性能的综合考量,在工业界,Attention被大量使用,“Attention is all your need!”。
二 Self Attention简介
最近几年,在深度学习领域,NLP可以说是相当的SOTA。比如BERT、RoBERTa、ALBERT、SpanBERT、distilebert、SesameBERT、SemBERT、SciBERT、bibert、MobileBERT、TinyBERT和CamemBERT,相关模型层出不穷,他们有什么共同之处呢?哈哈,从字面意义看,最大的相同之处就是都有BERT。
真正的答案是:Self Attention。不仅仅是名称为“BERT”的架构,更准确地说,是基于transformer的架构,基本就是基于Self Attention来构建的,正所谓Attention is all you need。基于转换器的架构主要用于语言理解任务的建模,避免了神经网络的递归,而是完全信任自我注意机制来刻画输入和输出之间的全局依赖关系。但这背后的原理是什么?
这就是我们今天要探讨的问题。这篇文章的主要内容是引导你完成Self Attention网络中涉及的数学运算。到本文结束时,您应该能够从头编写或编写Self Attention了。
如果你认为自我关注是类似的,答案是肯定的!它们在本质上具有相同的概念和许多共同的数学运算。
一个自我关注模块接受n个输入并返回n个输出。这个模块中发生了什么?用外行人的话来说,自我注意机制允许输入相互作用(“自我”),并发现他们应该更关注谁(“注意”)。这些输出是这些交互作用和注意力分数的总和。
Self Attention的本质其实可以这么理解,就是互相寻找相似的过程。
- 一个Self Attention模型接受N个输入,并且返回N个输出,输入之间互相作用,探索互相内部之间的影响机制。
- 一个Self Attention模型具备三个类型的参数矩阵Q、K、V。
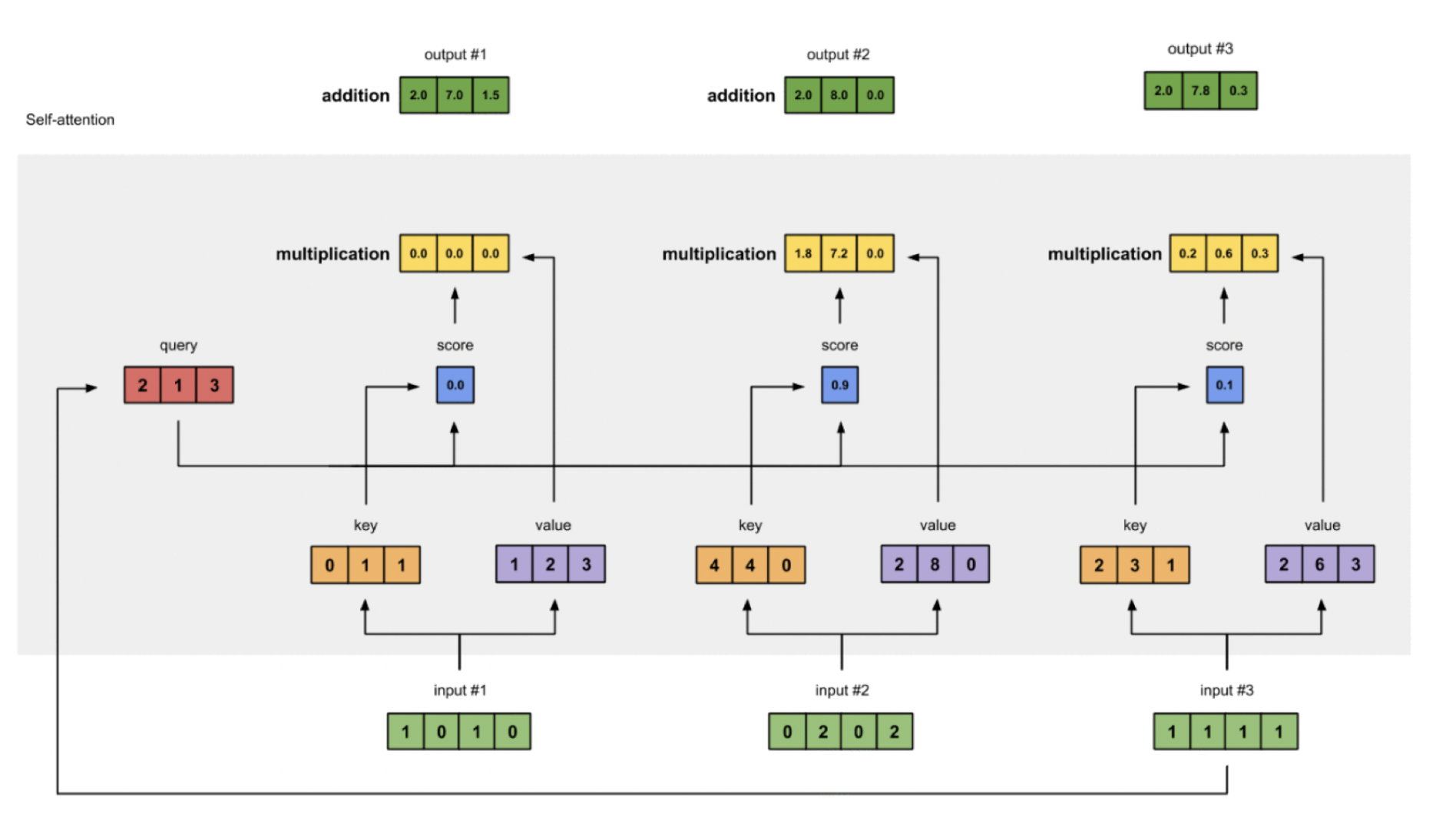
- 针对每个输入Input,分别计算经过Q、K、V参数矩阵之后的向量我们称之为Q表达、K表达与V表达。然后依次使用每个输入的Q表达与每个输入的K表达计算初始分数,然后进行Softmax归一分数,计算权重,然后将权重作用于V表达生成加权向量组,并且加权向量组进行融合,进行输出表征。
(注在后续经过Q、K、V计算后的向量和矩阵统称为Q、K、V表达)
三 Self Attention计算过程
在本篇文章中,我们将通过8个步骤的计算,逐步细致推导Self Attention的计算过程,大致步骤如下:
-
准备输入向量
-
初始化Q、K、V参数矩阵
-
计算Q、K、V表达
-
计算Attention的初始Score
-
计算Attention的Softmax归一分数
-
计算对齐向量
-
累加加权值计算Output 1
-
重复4-7的流程生成Output 2和Output 3
需要注意的是,在真正实践中,数学运算是向量化的,即所有的输入一起进行数学运算。我们将在后面的代码部分中看到这一点。
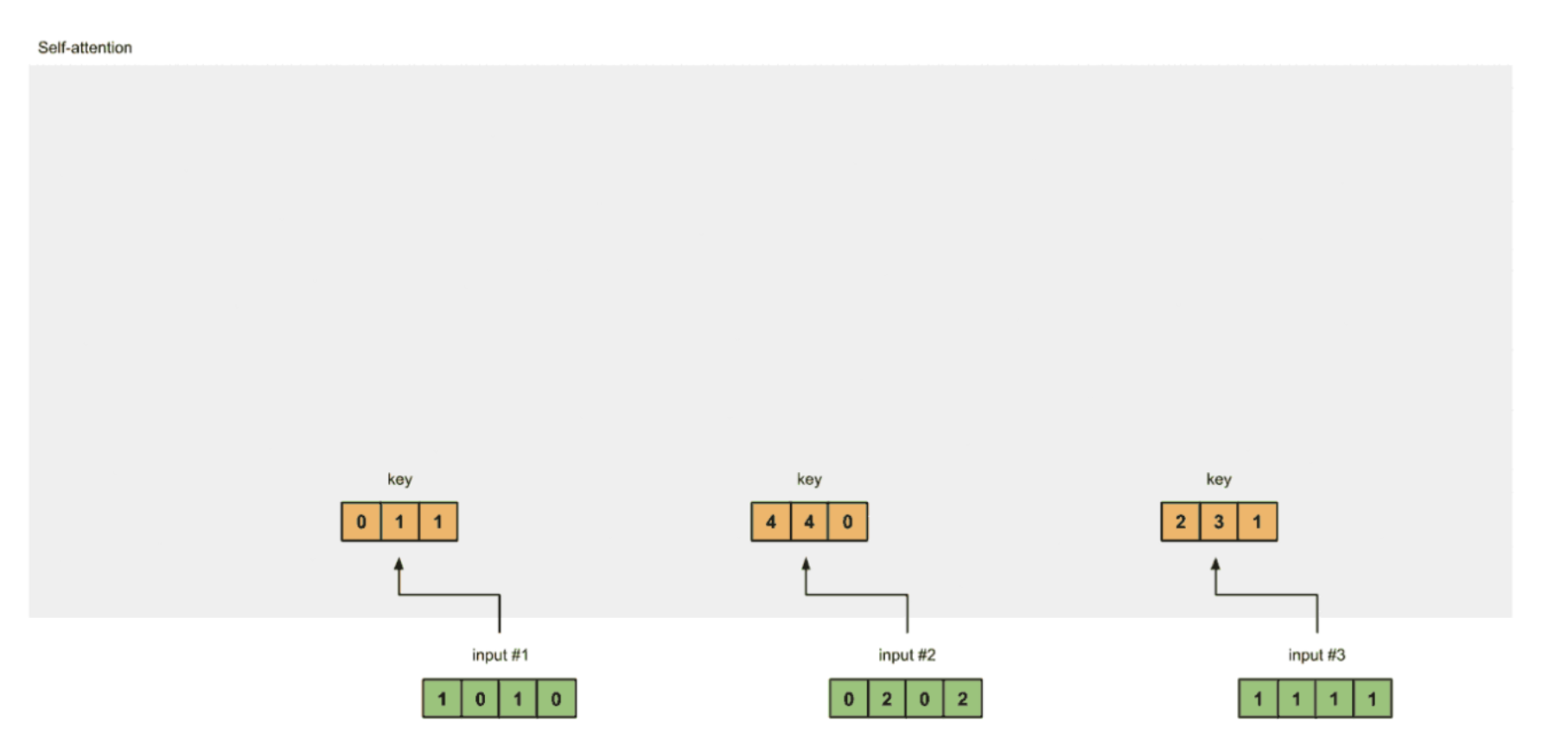
1 准备输入向量
假设Self Attention网络的输入是3个向量,每个向量的维度是4维,那么如图下所示。

- 输入向量如下:
Input 1: [1, 0, 1, 0]
Input 2: [0, 2, 0, 2]
Input 3: [1, 1, 1, 1]
2 初始化Q、K、V参数矩阵
Self Attention网络通过对同一个输入,经过与Q、K、V(有时候K、V矩阵是一个),分别计算三个向量。假设输入为A、B、C三个,那么A的Q矩阵计算出的向量与A、B、C通过K参数矩阵计算的向量进行Score计算(对于Score计算不熟悉同学请看我商品介绍Attention的文章)。然后进行Softmax归一化,最后将归一化数据应用到A、B、C通过V参数矩阵计算的向量上,与A经过Q参数矩阵计算的向量进行融合 (比如按位加)。
经过Q、K、V参数矩阵,每个输入会有三种表示(见下图)。这些表示称为K-键(橙色)、Q-查询(红色)和V-值(紫色)(K与V有时候是一个表达)。在这个例子中,我们假设我们想要这些表示的维数是3。因为每个输入的维度都是4,所以每个权重集的形状都必须是4×3。(注在后续经过Q、K、V计算后的向量和矩阵统称为Q、K、V表达)

为了计算输入向量基于Q、K、V的表达,我们需要定义三个特征矩阵(Q、K、V),所以我们初始化Q、K、V矩阵如下:
- Q矩阵
[[0, 0, 1],
[1, 1, 0],
[0, 1, 0],
[1, 1, 0]]
- K矩阵
[[1, 0, 1],
[1, 0, 0],
[0, 0, 1],
[0, 1, 1]]
- V矩阵
[[0, 2, 0],
[0, 3, 0],
[1, 0, 3],
[1, 1, 0]]
在神经网络设置中,这些权重通常是小数字,使用适当的随机分布(如高斯分布、Xavier分布和Kaiming分布)随机初始化。这个初始化在训练之前完成一次。
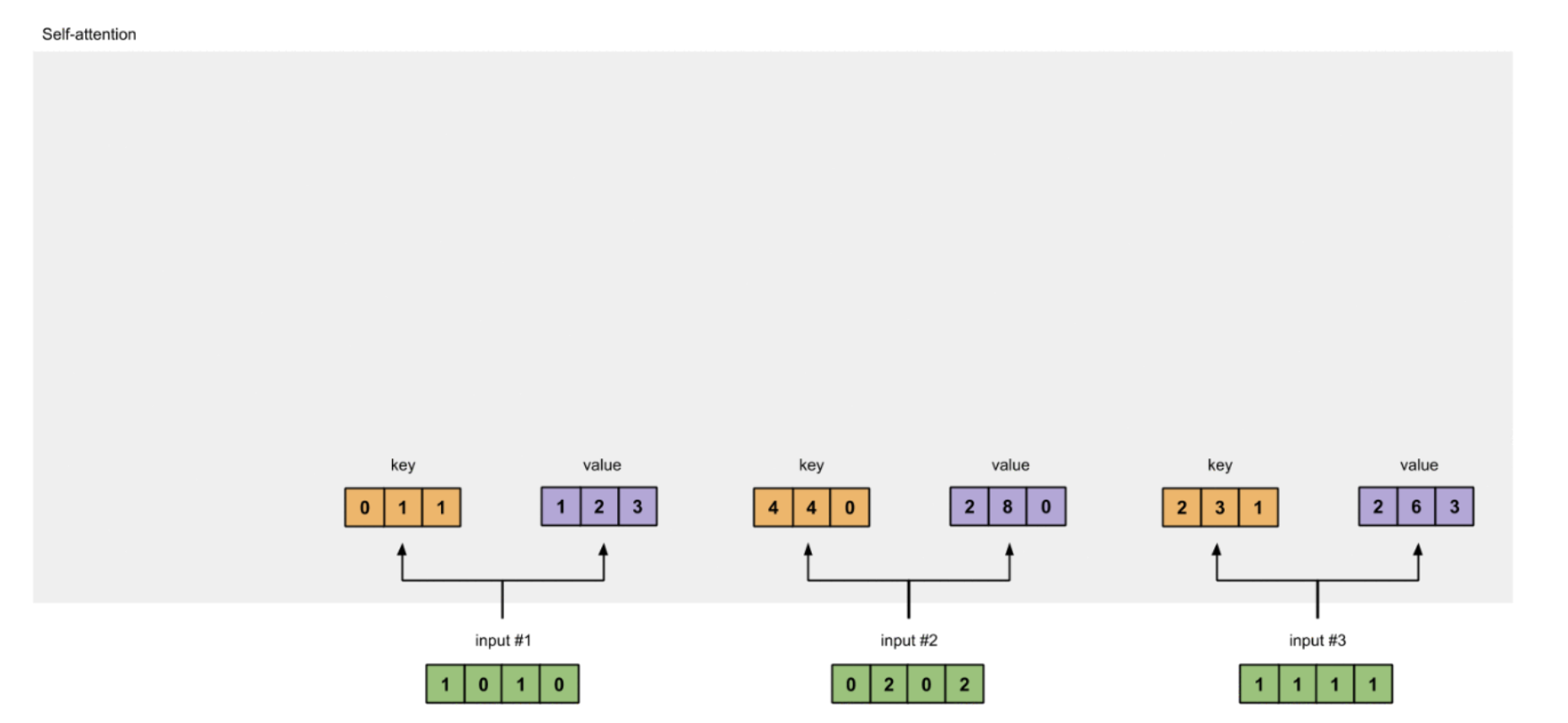
3 计算Q、K、V表达
到本步骤,目前已经拥有三个输入向量,三个参数矩阵(Q、K、V),那么我们需要分别计算这三个输入向量基于三个参数矩阵的Q、K、V表达。
3.1 K表达
- 针对输入一,计算如下:
[0, 0, 1]
[1, 0, 1, 0] x [1, 1, 0] = [0, 1, 1]
[0, 1, 0]
[1, 1, 0]
- 同理,针对输入二,计算如下
[0, 0, 1]
[0, 2, 0, 2] x [1, 1, 0] = [4, 4, 0]
[0, 1, 0]
[1, 1, 0]
- 同理,针对输入三,计算如下
[0, 0, 1]
[1, 1, 1, 1] x [1, 1, 0] = [2, 3, 1]
[0, 1, 0]
[1, 1, 0]
- 上面仅仅是为了演示如何进行向量计算,实际中算法框架是通过矩阵运算实现的,如下所示
[0, 0, 1]
[1, 0, 1, 0] [1, 1, 0] [0, 1, 1]
[0, 2, 0, 2] x [0, 1, 0] = [4, 4, 0]
[1, 1, 1, 1] [1, 1, 0] [2, 3, 1]
3.2 K表达
我们使用同样的方法计算每个输入向量的K表达。
[0, 2, 0]
[1, 0, 1, 0] [0, 3, 0] [1, 2, 3]
[0, 2, 0, 2] x [1, 0, 3] = [2, 8, 0]
[1, 1, 1, 1] [1, 1, 0] [2, 6, 3]
3.3 V表达
我们使用同样的方法计算每个输入向量的V表达。

[1, 0, 1]
[1, 0, 1, 0] [1, 0, 0] [1, 0, 2]
[0, 2, 0, 2] x [0, 0, 1] = [2, 2, 2]
[1, 1, 1, 1] [0, 1, 1] [2, 1, 3]
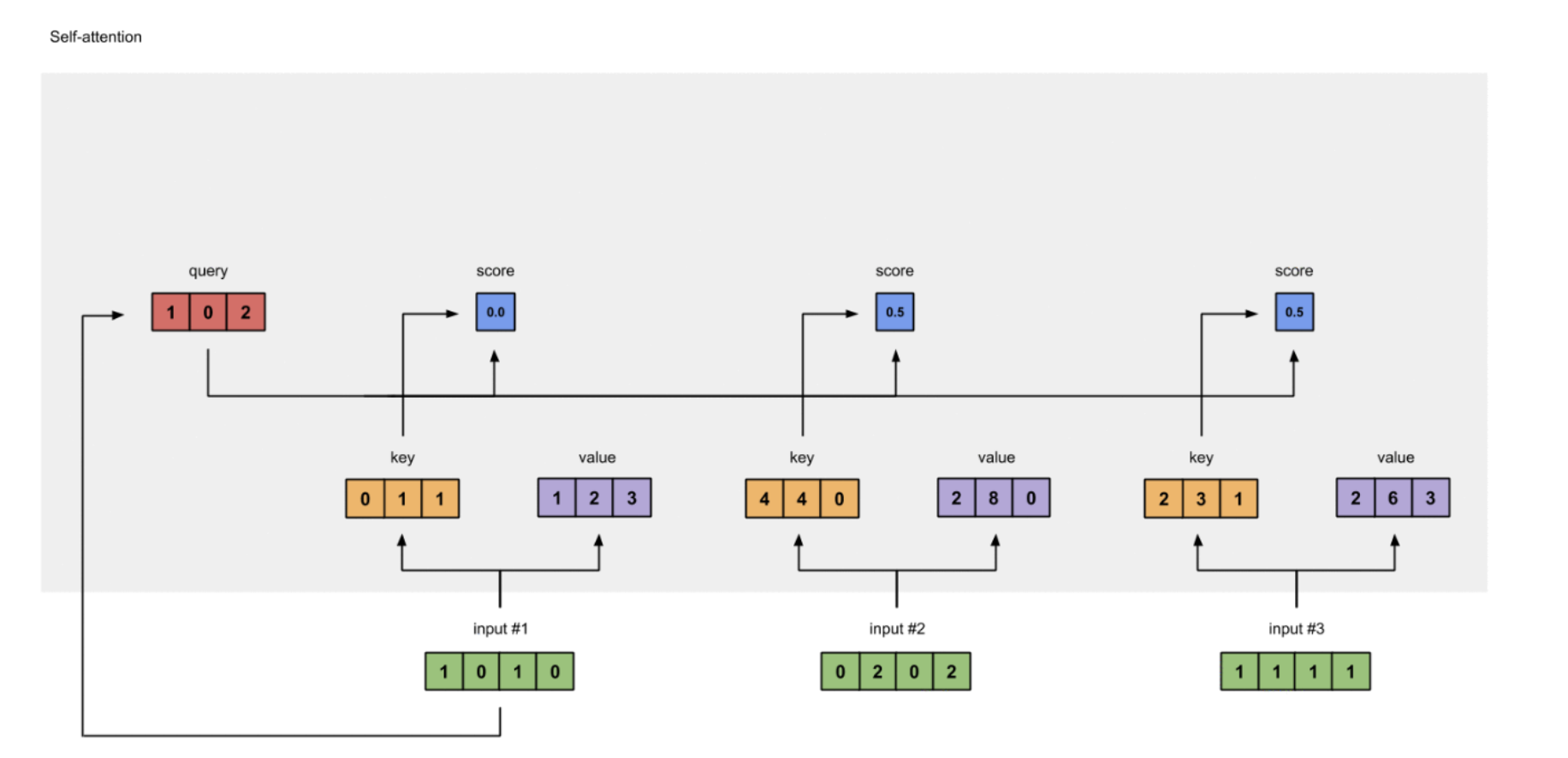
4 计算Attention初始Score
本步骤的功能主要是,通过自身Softmax归一化分数score^与自身向量数乘,得到对齐向量组。

为了获得初始注意力分数,我们首先取Input 1的查询(红色)-Q表达,计算与所有输入键(橙色)- K表达的点积(包括它自己)。因为有3个键表示(因为我们有3个输入),我们得到3个初始注意力分数(蓝色)。
[0, 4, 2]
[1, 0, 2] x [1, 4, 3] = [2, 4, 4]
[1, 0, 1]
注意,这里仅仅计算了来自Input 1的注意力分数。稍后,我们将对其他Input重复相同的步骤。
5 计算Attention的Softmax归一分数
本步骤的功能主要是,通过Softmax函数将上面计算的Score进行归一化操作计算归一化的分数。
- 计算过程
softmax([2, 4, 4]) = [0.0, 0.5, 0.5]
请注意,为了便于阅读,我们将其四舍五入到小数点后一位。
6 计算对齐向量
本步骤的功能主要是,通过自身Softmax归一化分数score与自身向量数乘,得到对齐向量组。
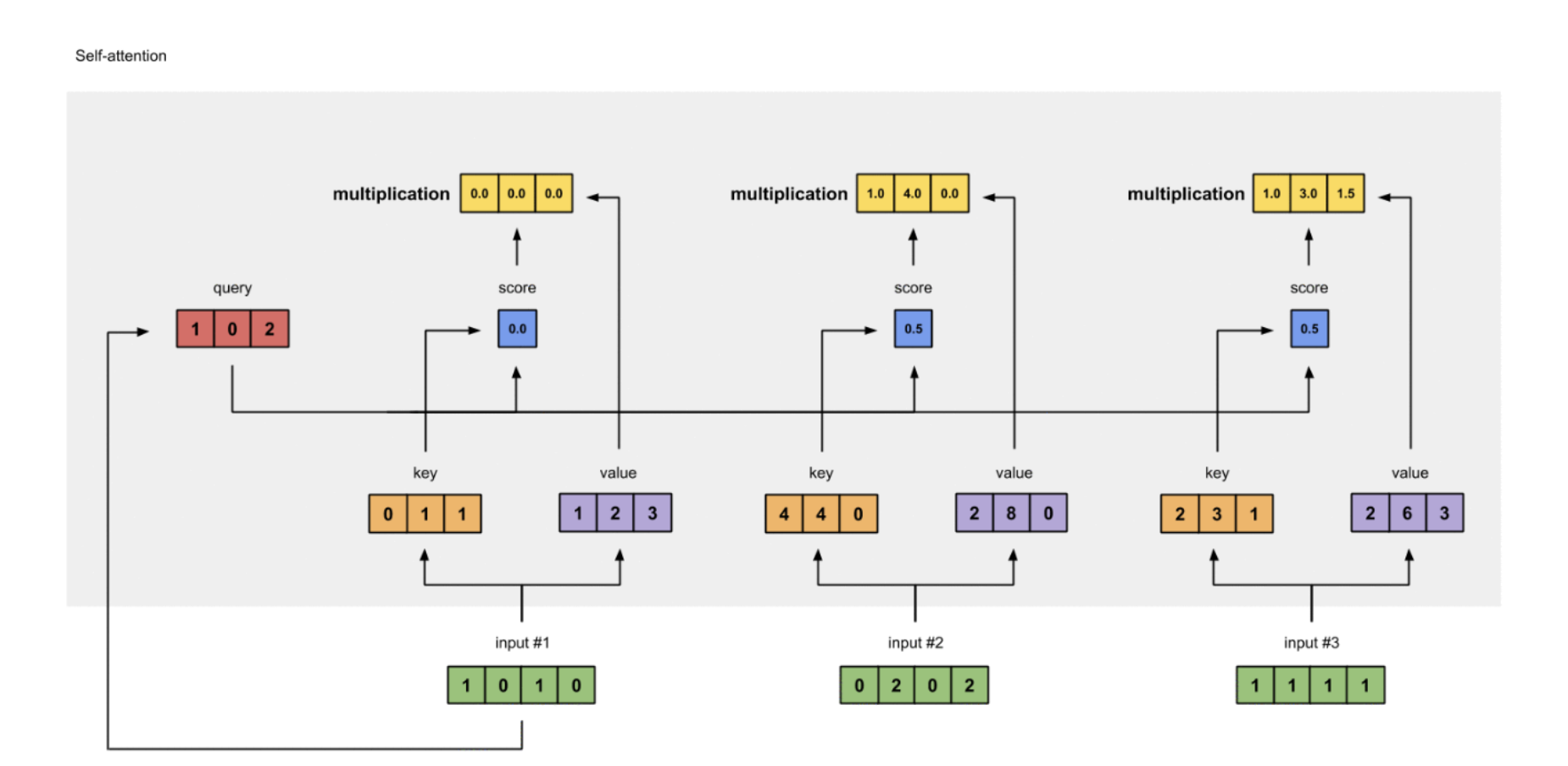
每个输入的Softmax归一分数(蓝色)乘以相应的V表达(紫色)。生成3个对齐向量(黄色)。我们将把它们称为加权值。
1: 0.0 * [1, 2, 3] = [0.0, 0.0, 0.0]
2: 0.5 * [2, 8, 0] = [1.0, 4.0, 0.0]
3: 0.5 * [2, 6, 3] = [1.0, 3.0, 1.5]
7 累加加权值计算Output 1
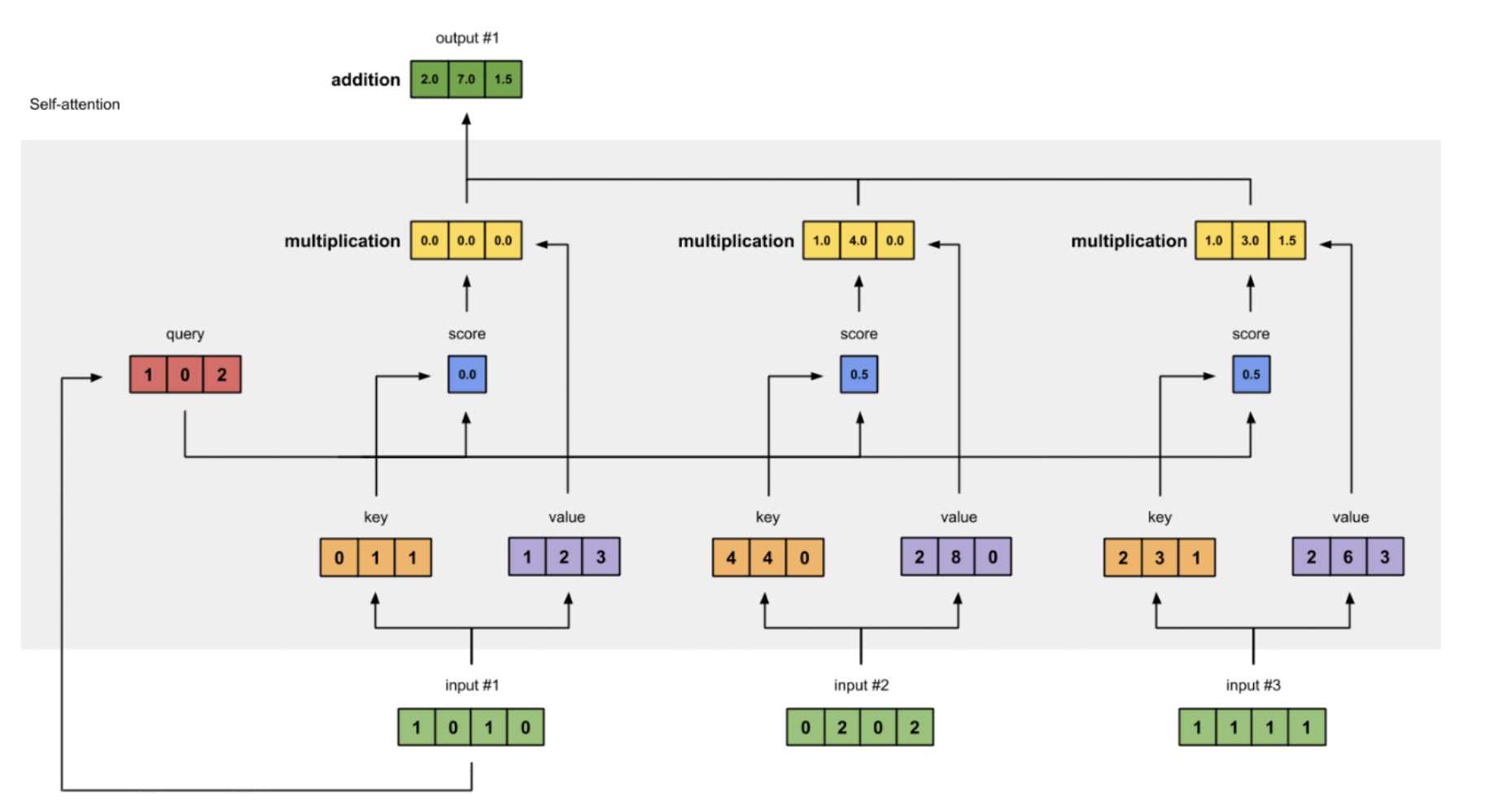
- 计算过程
将所有加权值(黄色)并按元素求和,计算最终的输入Output 1:
[0.0, 0.0, 0.0]
+ [1.0, 4.0, 0.0]
+ [1.0, 3.0, 1.5]
-----------------
= [2.0, 7.0, 1.5]
向量[2.0,7.0,1.5](深绿色)是Output 1,它既拥有Input 1的信息也通过了Self Attention机制获得了其他两个输入的信息。
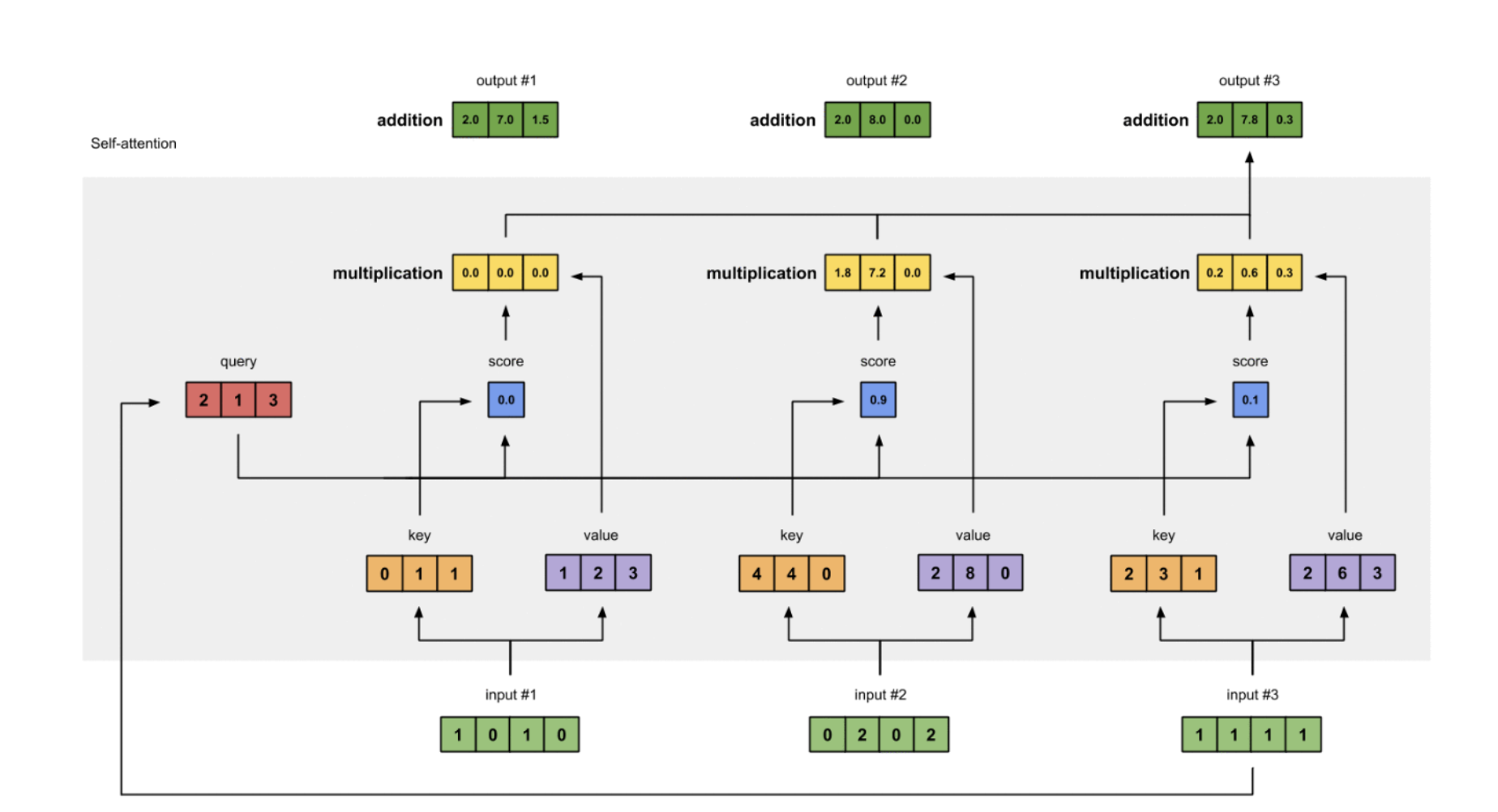
8 重复4-7的流程生成Output 2和Output 3
现在我们已经完成了输出1,我们对输出2和输出3重复步骤4到7。
四 参考资料
-
Attention Is All You Need (arxiv.org)
-
The Illustrated Transformer (jalammar.github.io)
-
Attn: Illustrated Attention (towardsdatascience.com)https://towardsdatascience.com/illustrated-self-attention-2d627e33b20a)
五 番外篇
介绍:杜宝坤,互联网行业从业者,十五年老兵。精通搜广推架构与算法,并且从0到1带领团队构建了京东的联邦学习解决方案9N-FL,同时主导了联邦学习框架与联邦开门红业务。
个人比较喜欢学习新东西,乐于钻研技术。基于从全链路思考与决策技术规划的考量,研究的领域比较多,从工程架构、大数据到机器学习算法与算法框架、隐私计算均有涉及。欢迎喜欢技术的同学和我交流,邮箱:baokun06@163.com
六 公众号导读
自己撰写博客已经很长一段时间了,由于个人涉猎的技术领域比较多,所以对高并发与高性能、分布式、传统机器学习算法与框架、深度学习算法与框架、密码安全、隐私计算、联邦学习、大数据等都有涉及。主导过多个大项目包括零售的联邦学习,社区做过多次分享,另外自己坚持写原创博客,多篇文章有过万的阅读。公众号秃顶的码农大家可以按照话题进行连续阅读,里面的章节我都做过按照学习路线的排序,话题就是公众号里面下面的标红的这个,大家点击去就可以看本话题下的多篇文章了,比如下图(话题分为:一、隐私计算 二、联邦学习 三、机器学习框架 四、机器学习算法 五、高性能计算 六、广告算法 七、程序人生),知乎号同理关注专利即可。

一切有为法,如梦幻泡影,如露亦如电,应作如是观。















 2563
2563











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









