






目录
一、python文本分析概念
文本分析中第一个概念是停用词,这种词有三个特点:(1)语料中大量出现;(2)没啥用;(3)留着没用。比如符号(!@#)、语气词(啊、一个、一下)等。这类词找出来之后就可以剔除。

同时也引申针对不同语言有些特别的处理方法,英语得去除时态、大小写转换等:
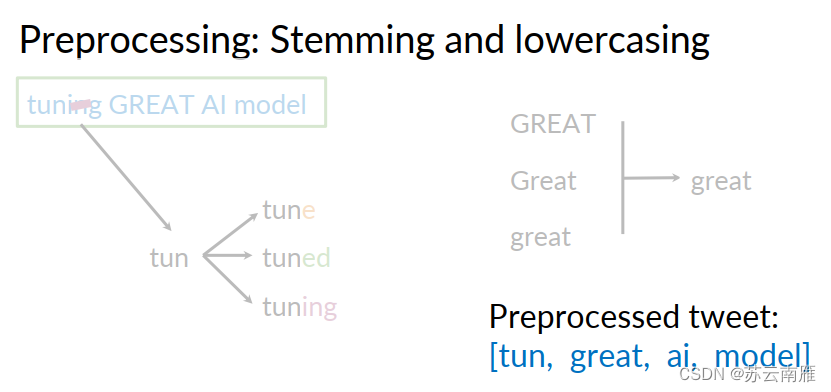
实际上在英文的文本处理有三个主要过程:(1)Removing stopwords, punctuation, handles and URLs,指删掉停用词、标点符号、句柄(@后那一段)、url;(2)Stemming,词性的统一;(3)Lowercasing,变成小写。
第二个概念是TF-IDF(用来做关键词提取),TF指词频(Term Frequency),IDF(Inverse Document Frequency)指“逆文档频率”,如果某个词比较少见,但是它在这篇文章中多次出现,那么它很可能就反映了这篇文章的特性正是我们所需要的关键词。
区分TF和IDF关注一个特点:词频TF是在分析的文章中、逆文档频率IDF是假定找到全量文本后的分析,全量文档数可以用诸如的搜到的文档来估算。TF-IDF=TF×IDF,两者相乘就得到了这个词的重要程度!这个算法也很聪明。
第三个概念是相似度,一般用的比较多的是余弦相似度,如下图所示。这种相似度取决于先将词、句子向量化,找到足够的特征之后用余弦的映射概念比较两者之间的相关程度,向量化的也有自监督和标注的方式,自监督也是目前词嵌入里很棒的方法,总之有了词向量之后就有了NLP的基础。

第四个概念便是LDA(Linear Discriminant Analysis) :主题模型。LDA算法是一种有监督的机器学习算法,和PCA有点像,也是能做降维的,主要用在展示侧,要想看到图的效果,采用这个算法还不错,如果在训练中想减少维度就用PCA。
二、贝叶斯方法
贝叶斯想解决的问题,是逆向概率。正向概率是指,一个袋里有M个黑球、N个白球,那么我取出黑球的概率是多少,比较直观、好算。相较而言,逆向概率逻辑复杂一点,我们不知道有多少个白球、黑球,摸出来一个或几个黑球,我们对黑、白球比例做推测。
贝叶斯方法的数学逻辑很有意思,反映一种现实世界的不确定性,人类的观察能力是有局限性的,只能看到表面的结果,深层次的逻辑还需要推测。当然量子的世界也是概率性的,很适合这种数学逻辑。
贝叶斯公式:
公式很好记,实际应用中,比如单词纠错中有些变形的点。比如输错了一个单词thaw,实际上可能是that,用户实际输入的单词记为D(即为观测数据),猜测统一为P(h | D) 变形P(h) * P(D | h) / P(D),D是常数,不影响,看上面这一部分P(h) * P(D | h)就行。
对于P(h) * P(D | h)这部分的处理,用到三个概念,一是事件间的独立性,假定事件间相互独立,贝叶斯算法变成朴素贝叶斯,猜测变得更纯粹简单,当然牺牲了事件的真实性,这种牺牲在LSTM、Transformer中就不必要了,只要数据更大;二是最大似然,用来求P(D | h),最符合观测数据的估计最优优势;三是奥卡姆剃刀,指模型或者思维能用简单的更好,如果模型既可以用多种多项式表示,越是高阶的多项式越是不常见,采用P(h)较大的模型,我们如果看到h出现,那么就可以认为P(h)=1。
补充对数似然估计,对数似然估计在计算朴素贝叶斯(事件间相互对立)有较好效果,比如先将积极、消极方面的概率进行比例计算:

然后采用log对数方式变形:
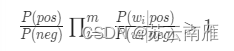
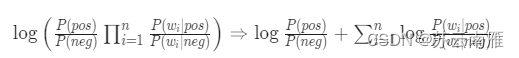
这样通过比率就可以很方便判断属于哪个类别。
总结:贝叶斯算法在逻辑上很有趣,但在判断中准确率不高,可作为baseline,后续逐步被深度学习算法融合、取代。
三、代码实例
采用jupyter notebook(适合做分析,pycharm适合做开发)看示例
先导包:
import pandas as pd
import jieba导入数据,数据源:搜狗搜索引擎 - 上网从搜狗开始
pd.read_table中names表示列名,dropna表示剔除空值
df_news = pd.read_table('./data/val.txt',names=['category','theme','URL','content'],encoding='utf-8')
df_news = df_news.dropna()
df_news.head()看看数据的维度是(5000, 4),包括用jieba进行分词等步骤省略,最后得到。
df_news.shape去除停用词代码如下,contents即为昨晚各类处理后的文本,stopwords为停用词,选好停用词做剔除即可。
def drop_stopwords(contents,stopwords):
contents_clean = []
all_words = []
for line in contents:
line_clean = []
for word in line:
if word in stopwords:
continue
line_clean.append(word)
all_words.append(str(word))
contents_clean.append(line_clean)
return contents_clean,all_wordsTF-IDF 提取关键词,调用jieba.analyse即可:
import jieba.analyse
index = 2400
print (df_news['content'][index])
content_S_str = "".join(content_S[index])
print (" ".join(jieba.analyse.extract_tags(content_S_str, topK=5, withWeight=False)))lda模型的调用,提取主题:
lda = gensim.models.ldamodel.LdaModel(corpus=corpus, id2word=dictionary, num_topics=20)
print (lda.print_topic(1, topn=5))贝叶斯分类代码:
from nltk import NaiveBayesClassifier
nb_classifier = NaiveBayesClassifier.train(train_set)
nb_classifier.classify(gender_features('Gary'))四、贝叶斯可视化(置信椭圆)
补充一个示例,通过confidence ellipse来看看朴素贝叶斯的效果,下图两个主要椭圆分别表示3σ、2σ的范围,3σ有99.7%数据落在里面,2σ有95%数据落在里面,这样可以直观地看到数据的范围和特点。
# Plot the samples using columns 1 and 2 of the matrix
fig, ax = plt.subplots(figsize = (8, 8))
colors = ['red', 'green'] # Define a color palete
sentiments = ['negative', 'positive']
index = data.index
# Color base on sentiment
for sentiment in data.sentiment.unique():
ix = index[data.sentiment == sentiment]
ax.scatter(data.iloc[ix].positive, data.iloc[ix].negative, c=colors[int(sentiment)], s=0.1, marker='*', label=sentiments[int(sentiment)])
# Custom limits for this chart
plt.xlim(-200,40)
plt.ylim(-200,40)
plt.xlabel("Positive") # x-axis label
plt.ylabel("Negative") # y-axis label
data_pos = data[data.sentiment == 1] # Filter only the positive samples
data_neg = data[data.sentiment == 0] # Filter only the negative samples
# Print confidence ellipses of 2 std
confidence_ellipse(data_pos.positive, data_pos.negative, ax, n_std=2, edgecolor='black', label=r'$2\sigma$' )
confidence_ellipse(data_neg.positive, data_neg.negative, ax, n_std=2, edgecolor='orange')
# Print confidence ellipses of 3 std
confidence_ellipse(data_pos.positive, data_pos.negative, ax, n_std=3, edgecolor='black', linestyle=':', label=r'$3\sigma$')
confidence_ellipse(data_neg.positive, data_neg.negative, ax, n_std=3, edgecolor='orange', linestyle=':')
ax.legend(loc='lower right')
plt.show()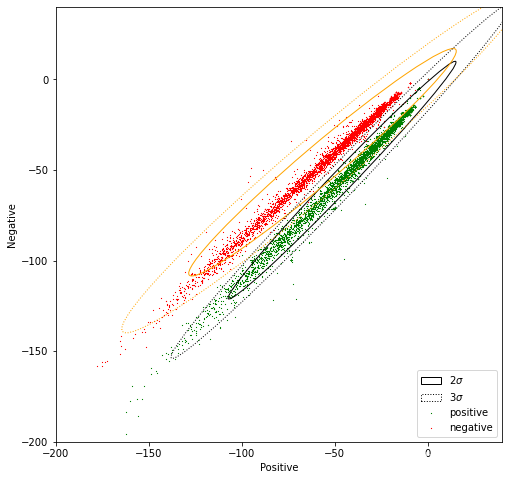
总结:python里面封装了大量包,很好用,不用重复造轮子,理解就行,根据需求再来找例子、挑着学、完成自己项目就行。















 247
247

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









