







1.背景
1.1 功能模型
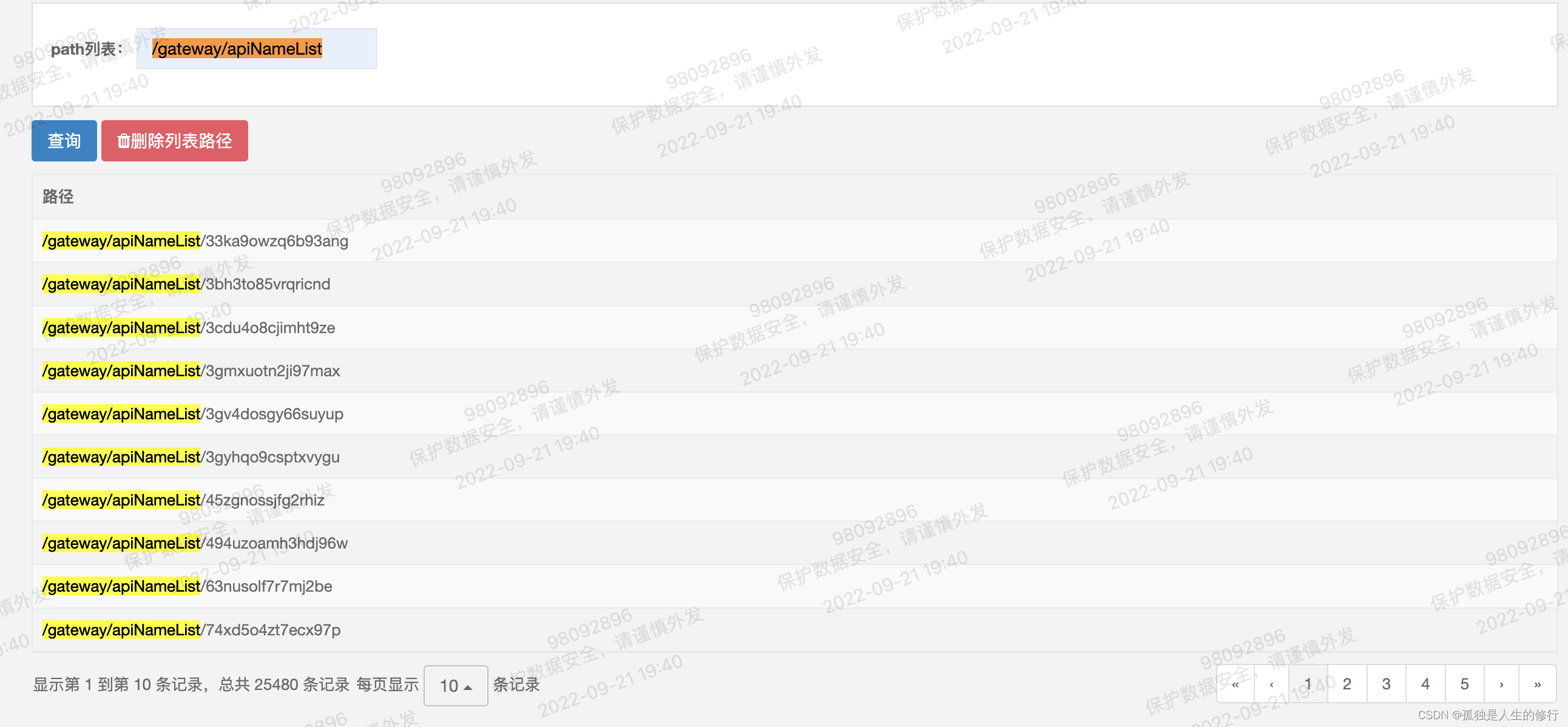
如下图所示,输入zookeeper path前缀,将匹配查询以此为前缀的zookeeper的所有path。
2.优化前
2.1 代码设计
由于zk并没有提供原生的api,能够根据前缀查询出所有路径。所以我们只能根据某个路径前缀,查询其子节点。若不能找到,则将其加入到结果集中。否则遍历所有的子节点,拼接上父路径,然后递归调用方法本身。如下代码所示:
private void lsr(String path, ZooKeeper zookeeper, List result){
List<String> list = null;
try {
list = ZKPaths.getSortedChildren(zookeeper, path);
} catch (InterruptedException e) {
e.printStackTrace();
} catch (KeeperException e) {
e.printStackTrace();
}
//判断是否有子节点
if(list == null || list.isEmpty()){
result.add(path);
return;
}
for(String s : list){
//判断是否为根目录
if(path.equals("/")){
lsr(path + s, zookeeper, result);
}else {
lsr(path +"/" + s, zookeeper, result);
}
}
}
2.2 代码性能评估
由于是单线程,通过递归的方式进行查询。在数据量大的时候,会导致查询次数过多,查询速度急速下降。经本地测试,500条数据,需要7秒钟才能查询出结果。
3.优化后
3.1 代码设计
上述单线程查询效率低下,所以我们想到通过多线程并行执行的方式,加快查询速度。由此我们便引入了ForkJoin框架。
ZkPath查询工具类:
import org.apache.curator.utils.ZKPaths;
import org.apache.zookeeper.ZooKeeper;
import java.util.ArrayList;
import java.util.List;
import java.util.concurrent.RecursiveTask;
public class ZkPathTask extends RecursiveTask<List<String>> {
List<String> pathName;
ZooKeeper zookeeper;
public ZkPathTask(List<String> pathName, ZooKeeper zookeeper) {
this.pathName = pathName;
this.zookeeper = zookeeper;
}
@Override
protected List<String> compute() {
//数据集大小小于等于50的时候,直接进行查询,不再进行拆分
if (pathName.size() <= 50) {
return sumRecord(pathName);
} else {
int mid = pathName.size() / 2;
//将数据平摊,并分配给两个子任务
List<String> subLeft = pathName.subList(0, mid);
List<String> subRight = pathName.subList(mid, pathName.size());
ZkPathTask left = new ZkPathTask(subLeft, zookeeper);
ZkPathTask right = new ZkPathTask(subRight, zookeeper);
invokeAll(left, right);
List<String> result = new ArrayList<>();
try {
//查询结果汇总
result.addAll(left.get());
result.addAll(right.get());
} catch (Exception e) {
e.printStackTrace();
}
return result;
}
}
public List<String> sumRecord(List<String> list) {
List<String> result = new ArrayList<>();
List<String> tempEndResult = new ArrayList<>();
List<String> tempSubResult = new ArrayList<>();
for (String path : list) {
List<String> temp = null;
try {
temp = ZKPaths.getSortedChildren(zookeeper, path);
} catch (Exception e) {
e.printStackTrace();
}
//判断是否有子节点,没有的话,将其加到结果集,否则交给子任务进行下一轮处理
if (temp == null || temp.isEmpty()) {
tempEndResult.add(path);
} else {
for (String strPath : temp) {
tempSubResult.add(path + "/" + strPath);
}
}
}
result.addAll(tempEndResult);
if (tempSubResult != null && tempSubResult.size() > 0) {
//生成新的子任务
ZkPathTask tempSub = new ZkPathTask(tempSubResult, zookeeper);
invokeAll(tempSub);
try {
//加入到结果集
result.addAll(tempSub.get());
} catch (Exception e) {
e.printStackTrace();
}
}
return result;
}
}
调用部分
ZooKeeper zookeeper = zkClient.getClient().getZookeeperClient().getZooKeeper();
List<String> result = new ArrayList<>();
ForkJoinPool pool = new ForkJoinPool(Runtime.getRuntime().availableProcessors() * 2);
List<String> tempList = new ArrayList<>();
//path前缀
tempList.add(pathName);
ZkPathTask zkPathTask = new ZkPathTask(tempList, zookeeper);
//发起调用
pool.invoke(zkPathTask);
//获得结果
result = zkPathTask.get();
String str = new String(zkClient.find(pathName));
//pathName会被放到结果集,当其只是路径的前缀,并非完整的路径时,需要将其移除。
if(StringUtil.isNullStr(str)){
result.remove(pathName);
}
3.2 代码性能评估
多线程并行执行,采用分治算法以及工作窃取(假设有A、B两个线程执行一个任务,A比较快,把活儿干完了,这时候A可以把B的一部分活接过来。这样总体来说会加快任务执行速度)的工作模式,将大任务拆分为多个子任务,子任务可以继续往下分解。多个不同的子任务都执行完成后,将它们各自的结果合并汇总成一个大结果,大大加快了查询速度。本地测试,500条数据,不用1秒即可查出。
the end~
















 1070
1070











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









