







注:此篇文章,基于前Google工程师王争编写的著作《数据结构与算法之美》,加以自身理解,编写而成。
一.排序算法详解
1.1 时间复杂度为O(n^2)的算法
1.1.1 冒泡排序
1.1.1.1 图解

1.1.1.2 代码实现
private static void bubbleSort(int[] arr) {
int len = arr.length;
if (len <= 1) {
return;
}
for (int i = 0; i < len; i++) {
boolean flag = false;
for (int j = 0; j < len - i - 1; j++) {
if (arr[j] > arr[j + 1]) {
int temp = arr[j + 1];
arr[j + 1] = arr[j];
arr[j] = temp;
flag = true;
}
}
if (!flag) {
return;
}
}
}
1.1.1.3 排序思想
冒泡排序的思想:整个冒泡排序会包含多次冒泡操作,第一次会遍历第1到第n-1个元素,然后依次对数组中相邻元素进行大小比较,对于不满足大小关系要求的元素,进行位置互换。第一次遍历完后,便将最大值放到了最后面。第二次遍历便对第1到第n-2个元素进行类似的操作,直到进行了n-1次冒泡操作后,整个数组就是有序的了。
1.1.1.4 补充说明
1.上述冒泡排序,是经优化之后的实现。在某次遍历之后,若没有发现有元素需要交换,则说明所有元素已经是有序的了,便可以终止
后续的冒泡操作。
2.冒泡排序是稳定排序算法。因为对于两个值相等的元素,我们不会对其进行交换。
1.1.2 插入排序
1.1.2.1 图解

1.1.2.2 代码实现
private static void insertionSort(int[] array) {
int len = array.length;
if (len <= 1) {
return;
}
for (int i = 1; i < len; i++) {
int value = array[i];
int j = i - 1;
for (; j >= 0; j--) {
if (array[j] > value) {
array[j + 1] = array[j];
}else{
break;
}
}
array[j + 1] = value;
}
}
1.1.2.3 排序思想
插入排序的思想:将原数组分为前半部分有序和后半部分无效的两部分。遍历的时候,从第2个元素开始,一直到最后一个元素。外层循环遍历n - 1次。每次以当前元素为基准,从有序元素中,从后往前找到该元素的该存放的位置。并将该位置后面的元素,后移一位,空出来的位置,用来存放该元素。总的时间复杂度为O(n^2)
1.1.2.4 补充说明
1.插入排序是稳定排序算法。因为如果以某个元素为基准,在有序的前半部分,找到与它值相等的几个元素,它总是被插在那些元素的后面,这样就保证了值相等的几个元素的相对顺序,保持不变。
2.我们更倾向于使用插入排序而不是冒泡排序,因为对于交换操作,前者需要1个赋值语句,而后者需要3个。因此,前者更快。如下图所示:
冒泡排序:
if (arr[j] > arr[j + 1]) {
int temp = arr[j + 1];
arr[j + 1] = arr[j];
arr[j] = temp;
flag = true;
}
插入排序:
if (array[j] > value) {
array[j + 1] = array[j];
}else{
break;
}
1.1.3 选择排序
1.1.3.1 图解

1.1.3.2 代码实现
private static void selectionSort(int[] arr) {
int len = arr.length;
if (len <= 1) {
return;
}
for (int i = 0; i < len - 1; i++) {
int min = i;
for (int j = i; j < len; j++) {
if (arr[j] < arr[min]) {
min = j;
}
}
int temp = arr[i];
arr[i] = arr[min];
arr[min] = temp;
}
}
1.1.3.3 排序思想
选择排序的思想:数组分为两部分,前半段为已排序,后半段为未排序。每次从未排序的区间内选择最小的元素,然后放到已排序区间的末尾。
1.1.3.4 补充说明
1.选择排序的空间复杂度是O(1),是一种原地排序算法。选择排序的最好时间复杂度、最坏时间复杂度、平均时间复杂度都是O(n^2)。
2.选择排序不是稳定的排序算法。比如5,3,5,2,9这串数字,第一次遍历的时候找出最小值2,会与第一个5交换位置,这样导致两个5的相对顺序就变了。
1.2 时间复杂度为O(nlogn)的算法
上述3种排序算法,由于时间复杂度比价高,更适合于小规模数据的排序。此小节将介绍两种时间复杂度为O(nlogn)的排序算法:归并排序和快速排序。这两种排序算法,性能更好,更常用,更适合大规模的数据排序。归并排序和快速排序都用到了分治算法思想。
1.2.1 归并排序
1.2.1.1 图解
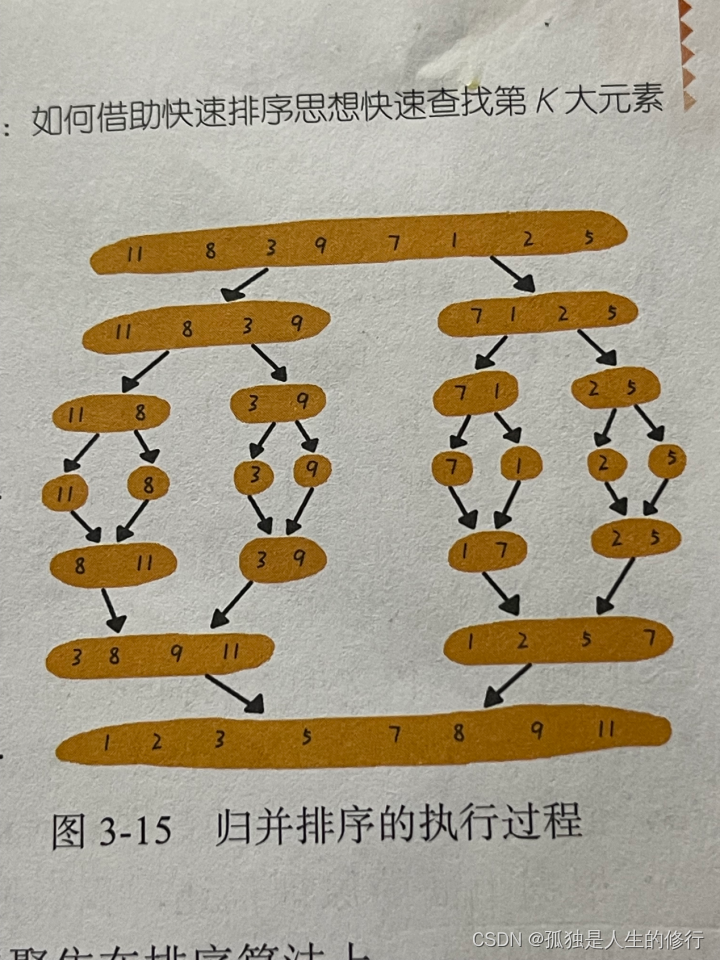
1.2.1.2 代码实现
static int[] temp;
private static void merge(int[] array) {
temp = new int[array.length];
sort(array, 0, array.length - 1);
}
private static void sort(int[] array, int start, int end) {
if (start >= end) {
return;
}
int mid = (end + start) / 2;
sort(array, start, mid);
sort(array, mid + 1, end);
merge(array, start, mid, mid + 1, end);
}
private static void merge(int[] array, int firstStart, int firstend, int secondStart, int secondEnd) {
int size = secondEnd - firstStart + 1;
int start = 0;
int i = firstStart;
int j = secondStart;
while (i <= firstend && j <= secondEnd) {
if (array[i] <= array[j]) {
temp[start++] = array[i ++];
} else {
temp[start++] = array[j ++];
}
}
int tempStart = i;
int tempEnd = firstend;
if (j <= secondEnd) {
tempStart = j;
tempEnd = secondEnd;
}
while (tempStart <= tempEnd) {
temp[start++] = array[tempStart++];
}
for (int k = 0; k < size; k++) {
array[firstStart++] = temp[k];
}
}
1.2.1.3 排序思想
归并排序的思想:归并排序使用的是分治算法思想。简而言之,分而治之,将一个大问题分解成小的子问题并逐个解决。首先将一个数组均匀拆分成前后两部分,这两部分继续进行拆分,直到剩下一个元素为止。然后再进行两两合并,合并后的数组均是有序的,最终合并成我们想要的结果。分治算法一般是用递归来实现的。分治是一种解决问题的处理思想,递归是一种编程技巧。
1.2.1.4 补充说明
1.由于归并排序能保证合并前后,值相同的两个元素的相对位置,顺序不变,所以归并排序是稳定排序算法。
2.归并排序的执行效率非常稳定,和原数组的有序程度无关。无论是最好,最差,还是平均情况,其时间复杂度都是O(nlogn)。即使是快速排序,也无法达到像归并排序一样的性能表现。在最坏的情况下,快速排序的时间复杂度也要达到O(n^2)。但为什么归并排序,并没有像快速排序一样,被广泛应用呢?那是因为归并排序并不是原地排序算法,它需要借助额外的临时数组temp。每次合并,需要将temp里的内容,赋值给原数组,所以空间复杂度是O(n),即使每次合并的时候,我们都去申明一个临时数组,其空间复杂度应取其峰值,仍然是O(n)(因为每次方法调用完后,临时数组占用的空间就被释放了)。由于递归调用的深度为O(log₂n),且每次方法调用,临时数组并不会入栈。所以总的空间复杂度是O(n + logn),省略低阶部分,也就是O(n)。
1.2.2 快速排序
1.2.2.1 图解
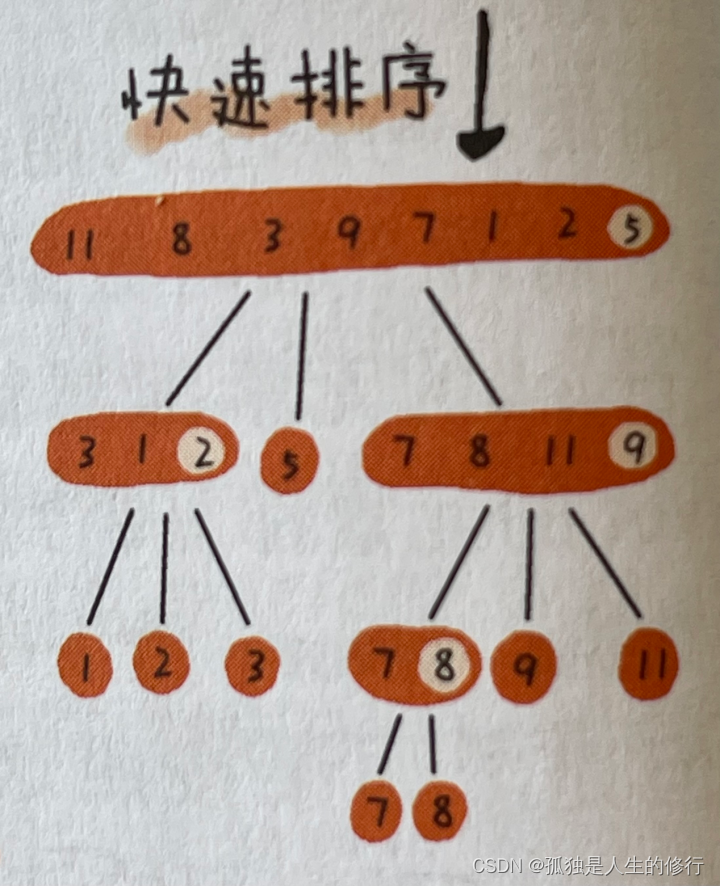
1.2.2.2 代码实现
private static void quickSort(int[] array) {
int len = array.length;
quickSort(array, 0, len - 1);
}
private static void quickSort(int[] array, int start, int end) {
if (start >= end) {
return;
}
//随机选出一个数字作为标的
int randomIndex = start + new Random().nextInt(end - start + 1);
int index = dealArray(array, start, end, randomIndex);
quickSort(array, start, index - 1);
quickSort(array, index + 1, end);
}
private static int dealArray(int[] array, int start, int end, int randomIndex) {
int number = array[randomIndex];
//先把标的数字放到最后
swap(array, randomIndex, end);
int startIndex = start;
for (int i = start; i < end; i++) {
//小于等于标的数字的放其左边
if(array[i] <= number){
swap(array, startIndex, i);
startIndex ++;
}
}
//把标的数字放到正确的位置
swap(array, startIndex, end);
return startIndex;
}
private static void swap(int[] array, int origin, int target) {
int temp = array[origin];
array[origin] = array[target];
array[target] = temp;
}
1.2.2.3 排序思想
快速排序的思想:快速排序也利用了分治算法思想。从一个数组中,随机找出一个元素作为标的,将小于等于标的元素的放其左边,大于标的元素的放其右边。然后以标的元素的左右两部分为基准,继续重复刚刚的操作,直到某部分的元素个数,小于等于1时,不再继续拆分。
1.2.2.4 补充说明
1.快速排序并不是稳定排序算法,比如一组数字:6,8,7,6,3,5,9,4在首轮以4为基准数字时,第一个6会和3进行位置交换,那原来的两个6,顺序就颠倒了。
2.快速排序通过巧妙的设计实现了原地分区函数,解决了归并排序太耗内存的问题。
3.快速排序在极端情况下,比如原数组就是有序的:1,2,3,4,5,6,7。每次选基准数字的时候,都选择最后面那个,那这样的话,分区次数将达到n次,单次遍历的平均扫描元素次数是n/2。那总的时间复杂度将由O(nlogn)退化成了O(n^2)。
4.快速排序也是由递归来实现的。在分区点选择比较恰当的情况下,每次都将大区间均匀的一分为二,因此递归的最大深度为O(log₂n),总的空间复杂度是O(logn)。在分区点选择极其不均衡的情况下,空间复杂度将达到O(n)。在平均情况下,递归深度也是对数级别的。
5.归并排序和快速排序是稍微复杂一点的排序算法。但归并没有快排应用广泛,因为它不是原地排序算法,空间复杂度比较高,达到了O(n)。虽然快速排序在最坏的情况下,时间复杂度将达到O(n^2),但这种概率其实很小,我们可以通过选择合理的基准数字,来避免这种情况。
1.2.3 堆排序
1.2.3.1 图解
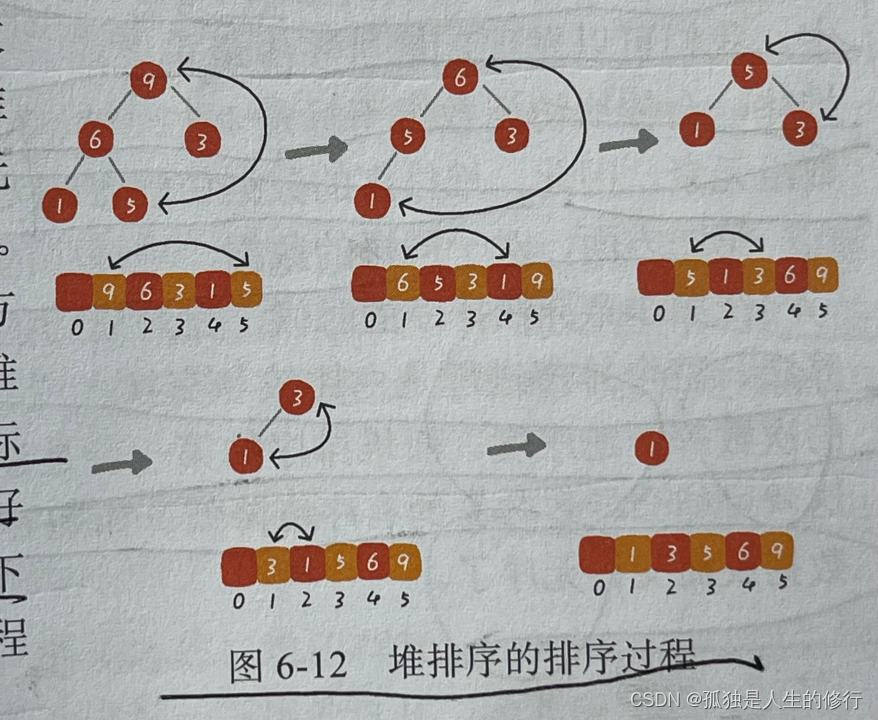
1.2.3.2 代码实现
通过底层类库PriorityQueue实现:
public static int[] heapSort(int[] arr) {
int length = arr.length;
if(length <= 1){
return arr;
}
PriorityQueue<Integer> queue = new PriorityQueue<>(new Comparator<Integer>() {
@Override
public int compare(Integer o1, Integer o2) {
return o1 - o2;
}
});
for (int i = 0; i < length; i++) {
queue.offer(arr[i]);
}
int index = 0;
while (!queue.isEmpty()) {
arr[index ++] = queue.poll();
}
return arr;
}
手写堆排实现:
public static int[] heapSort(int[] array) {
int len = array.length;
if (len <= 1) {
return array;
}
int maxIndex = len - 1;
//建立大顶堆(每个结点的值都大于或等于其左右孩子节点的值)
buildMaxArray(array, maxIndex);
//最大值和首部元素互换位置,则最大值将放至数组末尾
swapArray(array, 0, maxIndex);
//i的最小值为1(至少2个元素,才有排序的必要)
for (int i = maxIndex - 1; i >= 1; i--) {
//从索引0到i,调整堆结构,使首部元素仍然最大
buildArray(array, 0, i);
//索引0到i中最大值和位置i处元素互换位置
swapArray(array, 0, i);
}
return array;
}
private static void buildMaxArray(int[] array, int maxIndex) {
//从maxIndex / 2 索引处开始,则可以将树的所有节点覆盖
for (int i = maxIndex / 2; i >= 0; i--) {
buildArray(array, i, maxIndex);
}
}
//从上至下,调整堆结构
private static void buildArray(int[] array, int root, int maxIndex) {
int left = 2 * root + 1;
int right = 2 * root + 2;
int max = root;
if (left <= maxIndex && array[left] > array[root]) {
max = left;
}
if (right <= maxIndex && array[right] > array[max]) {
max = right;
}
if (max != root) {
swapArray(array, max, root);
buildArray(array, max, maxIndex);
}
}
private static void swapArray(int[] array, int max, int root) {
int temp = array[max];
array[max] = array[root];
array[root] = temp;
}
1.2.3.3 排序思想
堆排序的思想:堆排序分为两大步骤,建堆和排序。建堆的过程,我们的实现思路是从后往前处理数组,并且对每个数据执行自上而下的堆化。建堆完成后,数组的第1个元素就是最大值,然后与数组的第n个元素进行位置交换,这样最大值就放到了数组末尾,交换之后的堆顶元素,我们需要通过自上而下的堆化方式,将其移动到合适的位置。在堆化完成之后,堆中只剩下n-1个元素。我们再取堆顶元素,与第n-1个元素互换位置,这样第2大的元素就确定了位置,一直重复这个过程,直到堆中只剩下一个元素,排序工作就完成了。
1.2.3.4 补充说明
1.堆排序是一种原地的,时间复杂度是O(nlogn)的排序算法。
2.堆排序不是稳定的排序算法,因为在排序的过程中,存在将最后一个节点与堆顶节点互换的操作,这就有可能改变两个值相等元素的原有先后顺序。
3.快速排序的性能要比堆排序好。对于快速排序,数据是顺序访问的。而对于堆排序,数据是随机访问的。堆排序中最重要的一个操作就是堆化。堆化的过程,并非像快速排序那样,按照下标连续访问数组元素,因此,堆排序的数据访问方式无法利用cpu缓存预读数据。另外一个方面,对于同样的数据,堆排序的数据交换次数要多于快速排序。快速排序中数据交换的次数等于逆序度。而堆排序的第一步是建堆,建堆的过程会打乱数据原有的相对先后顺序,这就可能会导致数据的有序度降低。
1.3 应用
1.3.1 查找无序数组中的第k大元素
我们可以借助排序算法的处理思想来解决一些非排序相关的问题,例如:如何在O(n) 的时间复杂度内查找一个无序数组中的第k大元素?
1.堆排序(利用java封装好的PriorityQueue,时间复杂度是O(nlogk))
public static int findKthLargest(int[] nums, int k) {
PriorityQueue<Integer> queue = new PriorityQueue<>(new Comparator<Integer>() {
@Override
public int compare(Integer o1, Integer o2) {
return o1 - o2;
}
});
for (int i = 0; i < k; i++) {
queue.offer(nums[i]);
}
for (int i = k; i < nums.length; i++) {
queue.offer(nums[i]);
if(queue.size() > k){
queue.poll();
}
}
return queue.peek();
}
2.快排思想(时间复杂度是O(n))
private int len;
public int findKthLargest(int[] nums, int k) {
len = nums.length;
return getKthNum(nums, 0, len - 1, k);
}
private int getKthNum(int[] nums, int left, int right, int k) {
int index = dealArray(nums, left, right);
int num = index - left + 1;
if (num == k) {
return nums[index];
} else if (num > k) {
return getKthNum(nums, left, index - 1, k);
} else {
return getKthNum(nums, index + 1, right, k - num);
}
}
private int dealArray(int[] nums, int left, int right) {
int index = getRandomIndex(left, right);
swap(nums, index, right);
int temp = nums[right];
int startIndex = left;
for (int i = left; i < right; i++) {
if(nums[i] >= temp){
swap(nums, i, startIndex);
startIndex ++;
}
}
swap(nums, startIndex, right);
return startIndex;
}
private int getRandomIndex(int left, int right) {
int num = right - left + 1;
return new Random().nextInt(num) + left;
}
private void swap(int[] nums, int left, int right) {
int temp = nums[left];
nums[left] = nums[right];
nums[right] = temp;
}
1.3.2 内存空间有限的情况下,如何对大量的数据排序
按照设定条件:文本文件存有100 亿数据量,但是机器内存空间有限,不能一次性加载完全,如何排序?
- 数据库排序
将存储着 100 亿数据的文本文件一条一条导入到数据库中,然后根据某个字段建立索引,数据库进行索引排序操作后我们就可以依次提取出数据追加到结果集中。这种方法的特点就是操作简单, 运算速度较慢,对数据库设备要求较高。
- 分治法
1.将大文件,按照哈希或者直接平均分成1000个小文件。
2.每个独立的小文件,放到内存中排序,可以用快速、归并、堆排序等。
3.每个文件排好序后。建立一个小顶堆,容纳1000个元素。
4.取1000个文件的第一个数字加文件号的组合(数字相同的时候,按照文件号排序)放到堆中。
5.放了1000个元素后,弹出堆顶元素,将其放入最后的结果文件中,并取得对应的文件号,去对应的文件寻找下一个元素。并放入堆中。
6.不断重复步骤5,直到遍历完所有的文件,最后把堆中的元素依次弹出。
放入结果文件中,则得到了最后的结果。
二.排序算法比较
2.1 9种排序算法的比较
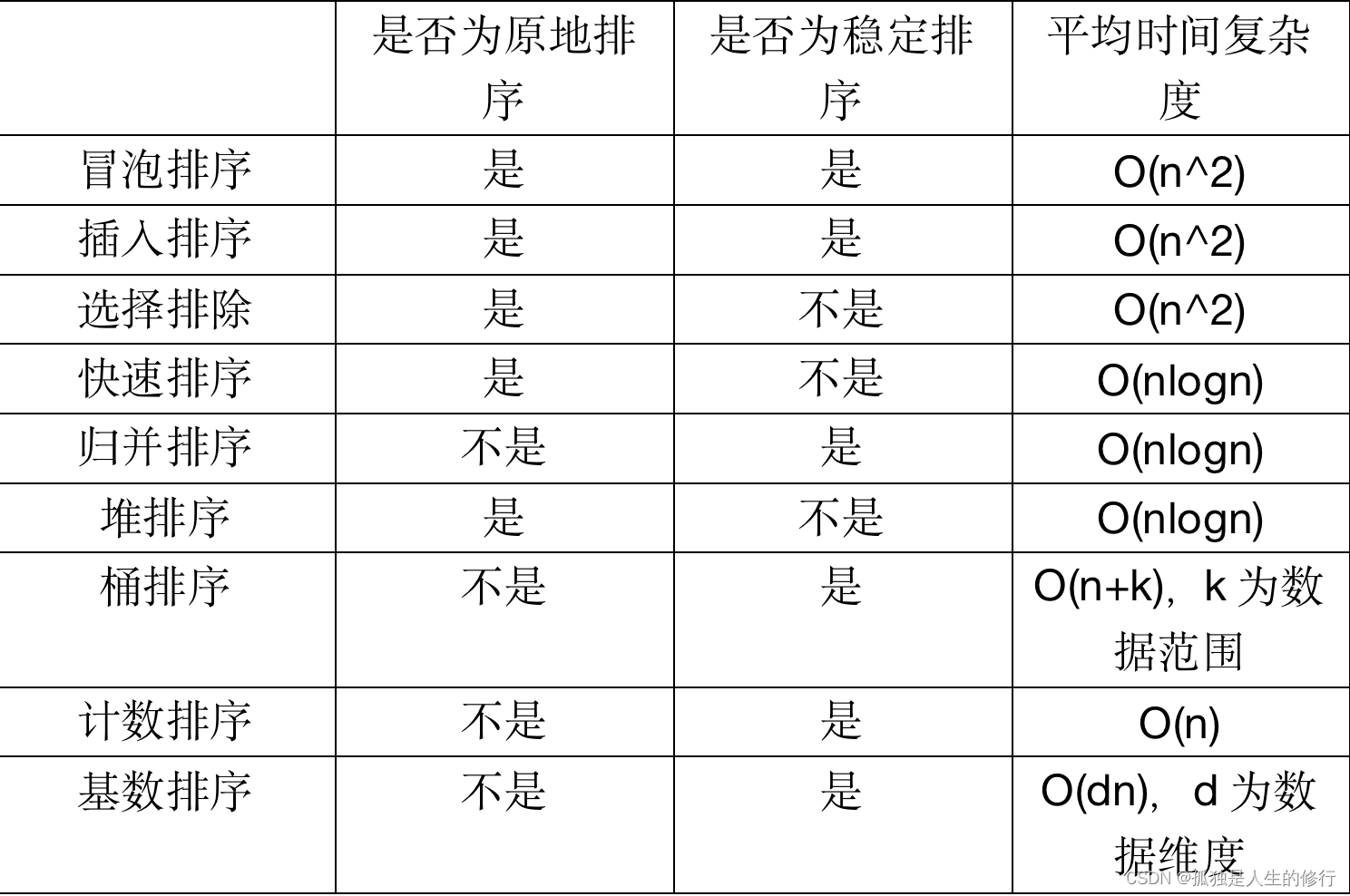
2.2 补充说明
1.冒泡排序和选择排序在实际开发过程中,应用的其实并不多,我们学习他们的目的,其实是为了扩展自己的思维。但插入排序的作用还是挺大的。
2.对小规模数据进行排序,我们可以选择时间复杂度是O(n^2)的算法,对大规模数据进行排序,我们会选择更高效的时间复杂度是O(nlogn) 的排序算法。因此,为了兼顾任意数据量的排序,一般首选时间复杂度是O(nlogn) 的排序算法。包括归并排序,快速排序以及堆排序。其中,快速排序和堆排序都有比较多的应用,但是归并排序使用的场景并不多,主要原因是归并排序并不是原地排序算法。如果要排序100m大小的数据,除数据本身外,还需要额外占用100m的内存空间。内存耗费翻倍,因此在实际的软件开发中,排序算法是否是原地排序算法是一个非常重要的选择标准。
3.快速排序是用递归来实现的。要警惕递归堆栈溢出。对于如何避免快速排序递归层次过深而导致的堆栈溢出,我们有两种方法:第一种是限制递归深度,一旦递归过深,超过了我们事先设定的阈值,就停止递归,改为其他排序算法,如堆排序,插入排序;第二种是我们模拟实现一个函数调用栈,手动模拟递归压栈、出栈的过程,这样就避开了系统栈大小的限制。














 524
524











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









