









数据结构-图的表示邻接矩阵与邻接表-Go语言
图的概念
到底什么是图?图是由一系列顶点和若干连结顶点集合内两个顶点的边组成的数据结构。数学意义上的图,指的是由一系列点与边构成的集合,这里我们只考虑有限集。通常我们用G = (V,E)表示一个图结构,其中V表示点集,E表示边集。
对于连接点之间的边根据其有无方向性分为:有向边和无向边。
图的分类:
邻接矩阵
- 邻接矩阵存储结构就是用矩阵表示图中各顶点之间的邻接关系。
- 对于有n个顶点的图 G = (V,E) 来说,我们可以用一个 n*n 的矩阵A来描述 G 中的各顶点间的相邻关系。如果vi与vj之间存在边(或弧),则
A[i][j]=1,否则a[i][j]=0。无向图的邻接矩阵是一个对称矩阵。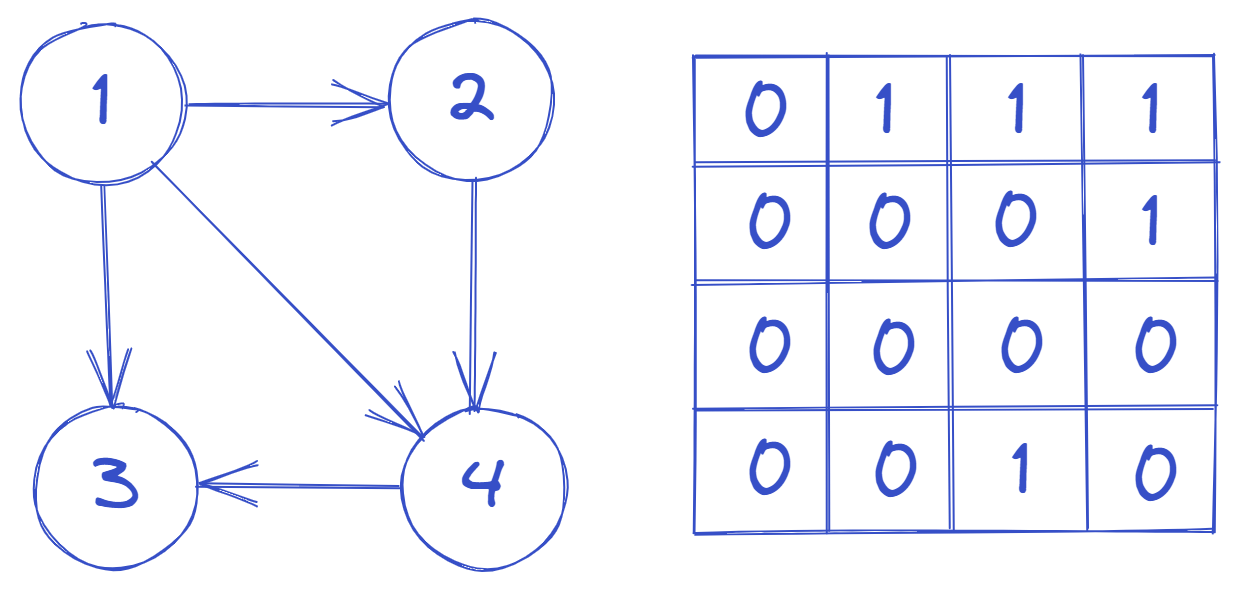
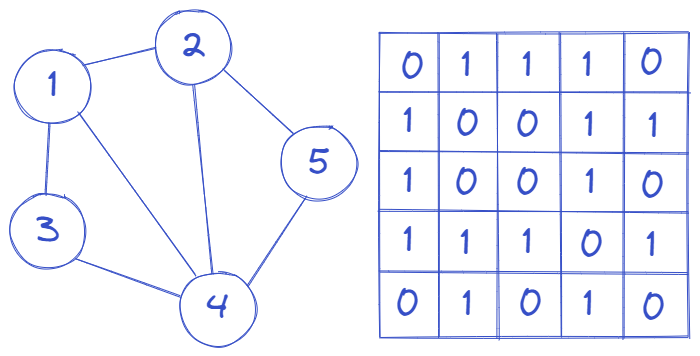
习题:邻接矩阵的使用
- 给出一个包含有向图和无向图的混合图G,图上有n 个点和m 条边,现在你需要使用邻接矩阵来存储该混合图G并按格式输出邻接矩阵。
- 输入格式:输入第一行为两个正整数n和m (1≤n,m≤100),表示混合图上的n 个点和m条边。接下来输入m行,每行输入三个整数a,x, y (0≤x,y<n),表示点x和点y之间有一条边。如果a=0,则表示该边为有向边,如果a=1,则表示该边为无向边。
- 输出格式:输出一个n×n的邻接矩阵,矩阵中第i行第j列的值描述了点i到点j的连边情况。如果值为О表示点i到点j没有边相连,值为1表示有边相连。在每一行中,每两个整数之间用一个空格隔开,最后一个整数后面没有空格。
输入样例
4 4
0 0 1
1 0 2
0 3 1
1 2 3
输出样例
0 1 1 0
0 0 0 0
1 0 0 1
0 1 1 0
参考代码
package main
import "fmt"
func main() {
var n, m, a, x, y int
fmt.Scan(&n, &m)
type graph struct{ a, x, y int }
an := make([]graph, m)
for i := 0; i < m; i++ {
fmt.Scan(&a, &x, &y)
an[i] = graph{a, x, y}
}
grid := make([][]int, n)
for i := range grid {
grid[i] = make([]int, n)
}
for i := 0; i < m; i++ {
if an[i].a == 0 {
grid[an[i].x][an[i].y] = 1
} else {
grid[an[i].x][an[i].y] = 1
grid[an[i].y][an[i].x] = 1
}
}
for i := 0; i < n; i++ {
for j := 0; j < n; j++ {
fmt.Print(grid[i][j])
if j != n-1 {
fmt.Print(" ")
}
}
fmt.Println()
}
}
邻接表
- 邻接表是图的一种顺序存储与链式存储相结合的存储方式。我们给图中的每个顶点建立一个单链表,第 i 个单链表中的结点表示依附于顶点 vi 的边(对于有向图是以 vi 为起点的弧)。所有单链表的表头节点都存储在一个一维数组中,以便于顶点的访问。下图为图 G1 对应的邻接表。

- 在无向图的邻接表中,顶点vi的度为第i个单链表中的结点数;而在有向图中,第i个单链表中的结点数表示的是顶点vi的出度,如果要求入度,则要遍历整个邻接表。另外,在邻接表中,我们很容易就能知道某一顶点和哪些顶点相连接。
习题:邻接表的使用
- 给出一个包含有向图和无向图的混合图G,图上有n个点和 m条边,现在你需要使用邻接表来存储该混合图G并按格式输出邻接表。
- 输入格式:输入第一行为两个正整数n和m1≤n,m≤100),表示混合图上的n个点和m条边。接下来输入m 行,每行输入三个整数a,x,y (0≤a≤10,O≤x,y<n),表示点x和点y之间有一条边a=0,则表示该边为有向边,a=1,则表示该边为无向边。
- 输出格式:输出邻接表,输出n行,第i行表示第i个点连接边的情况,首先输出i,接着输出:,然后输出所有点 i能到达的点的编号,边关系中后出现的点先输出。每个整数前有一个空格,具体格式见样例。
样例输入
4 4
0 0 1
1 0 2
0 3 1
1 2 3
样例输出
0:2 1
1:
2:3 0
3:2 1
参考代码
package main
import "fmt"
func main() {
var n, m int
var lines = [105][3]int{}
fmt.Scan(&n, &m)
for i := 0; i < m; i++ {
fmt.Scan(&lines[i][0], &lines[i][1], &lines[i][2])
}
tables := make([][]int, n)
for i := range tables {
tables[i] = make([]int, 0)
}
for i := 0; i < m; i++ {
if lines[i][0] == 0 {
tables[lines[i][1]] = append(tables[lines[i][1]], lines[i][2])
} else {
tables[lines[i][1]] = append(tables[lines[i][1]], lines[i][2])
tables[lines[i][2]] = append(tables[lines[i][2]], lines[i][1])
}
}
for i := 0; i < n; i++ {
fmt.Printf("%d:", i)
for j := len(tables[i]) - 1; j >= 0; j-- {
fmt.Print(" ")
fmt.Print(tables[i][j])
}
fmt.Println()
}
}
邻接矩阵和邻接表使用场合
- 我们可以看到,邻接矩阵存储结构最大的优点就是简单直观,易于理解和实现。其适用范围广泛,有向图、无向图、混合图、带权图等都可以直接用邻接矩阵表示。另外,对于很多操作,比如获取顶点度数,判断某两点之间是否有连边等,都可以在常数时间内完成。
- 然而,它的缺点也是显而易见的:从以上的例子我们可以看出,对于一个有n个顶点的图,邻接矩阵总是需要O(n2)的存储空间。当边数很少的时候,就会造成空间的浪费。
- 因此,具体使用哪一种存储方式,要根据图的特点来决定:如果是稀疏图(点多边少),我们一般用邻接表来存储,这样可以节省空间;如果是稠密图(点少边多),当需要频繁判断图中的两点之间是否存在边时往往用邻接矩阵来存储,其他时候用邻接表或邻接矩阵皆可。
点的图,邻接矩阵总是需要O(n2)的存储空间。当边数很少的时候,就会造成空间的浪费。
- 因此,具体使用哪一种存储方式,要根据图的特点来决定:如果是稀疏图(点多边少),我们一般用邻接表来存储,这样可以节省空间;如果是稠密图(点少边多),当需要频繁判断图中的两点之间是否存在边时往往用邻接矩阵来存储,其他时候用邻接表或邻接矩阵皆可。















 282
282











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









