







在日常的工作中,我们发现很多开发对Kafka本身并不太了解,运维由于经验的不足在初期对整体Kafka的管控也不是那么的严格,导致在使用上有很多问题。所以我们整合了内部的Kafka监控服务的数据,结合我们平台的任务血缘,开发了自己的一套Kafka监控服务。
目前这套系统整体还比较初级,除了关联了Kafka、流表、和任务之间的关系以外,我们还对以下这几种情况做了主动监控:
- Kafka Topic的分区数的合理性,主要监控消息队列分区数过少或者过多的情况,主要是过少的情况,防止因为分区数过小,下游任务处理性能跟不上的问题;
- Kafka分区数据生产均衡问题:防止因为Kafka本身分区数据的不均衡导致下游任务处理性能不行的问题;
- Kafka分区数据消费均衡问题:防止因为Kafka本身分区发生变化,而下游任务因为没有开启分区感知,导致一些数据没有消费到等问题;
- 流量激增和激降报警:关键队列流量报警,保障实时数据的质量。
Kafka版本升级:为了解决本身Kafka扩容的稳定性问题、资源隔离问题,通过我们在Kafka 2.X版本基础上做了一些二次开发工作,将Kafka整个服务做了平台化的支持,支持了Topic的平滑扩所容,支持资源隔离。
48.Kafka 监控都有哪些?
比较流行的监控工具有:
- KafkaOffsetMonitor
- KafkaManager
- Kafka Web Console
- Kafka Eagle
- JMX协议(可以用诸如jdk自带的jconsole来进行连接获取状态信息)
消息延迟如何监控?
我们可以通过两种方式进行监控消息:
- 消息队列提供的工具,通过监控消息的堆积来完成。
- 通过生产监控消息来对消息延时的监控。
一、消息队列工具
Kafka 也提供了一些工具来获取这个消费进度的信息帮助我们实现自己的监控,这个工具主要有两个:
(1)Kafka 提供了工具叫做“kafka-consumer-groups.sh”(它在 Kafka 安装包的 bin 目录下)。

- 前两列是队列的基本信息,包括topic名和分区名;
- 第三列是当前消费者的消费进度;
- 第四列是当前生产消息的总数;
- 第五列就是消费消息的堆积数(也就是第四列与第三列的差值)。
(2)第二个工具是JMX
Kafka 通过 JMX 暴露了消息堆积的数据,然后我们就可以通过写代码将这个堆积数据发送到我们的监控系统中去。
1.4.2 broker服务监控
broker服务的监控,主要是通过在broker服务启动时指定JMX端口,然后通过实现一套指标采集程序去采集JMX指标。(服务端指标官网地址)
broker级监控:broker进程、broker入流量字节大小/记录数、broker出流量字节大小/记录数、副本同步入流量、副本同步出流量、broker间流量偏差、broker连接数、broker请求队列数、broker网络空闲率、broker生产延时、broker消费延时、broker生产请求数、broker消费请求数、broker上分布leader个数、broker上分布副本个数、broker上各磁盘流量、broker GC等。
topic级监控:topic入流量字节大小/记录数、topic出流量字节大小/记录数、无流量topic、topic流量突变(突增/突降)、topic消费延时。
partition级监控:分区入流量字节大小/记录数、分区出流量字节大小/记录数、topic分区副本缺失、分区消费延迟记录、分区leader切换、分区数据倾斜(生产消息时,如果指定了消息的key容易造成数据倾斜,这严重影响Kafka的服务性能)、分区存储大小(可以治理单分区过大的topic)。
用户级监控:用户出/入流量字节大小、用户出/入流量被限制时间、用户流量突变(突增/突降)。
broker服务日志监控:对server端打印的错误日志进行监控告警,及时发现服务异常。
1.4.3.客户端监控
客户端监控主要是自己实现一套指标上报程序,这个程序需要实现
org.apache.kafka.common.metrics.MetricsReporter 接口。然后在生产者或者消费者的配置中加入配置项 metric.reporters,如下所示:
Properties props = new Properties();
props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "");
props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, IntegerSerializer.class.getName());
props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
//ClientMetricsReporter类实现org.apache.kafka.common.metrics.MetricsReporter接口
props.put(ProducerConfig.METRIC_REPORTER_CLASSES_CONFIG, ClientMetricsReporter.class.getName());
...客户端指标官网地址:
http://kafka.apache.org/21/documentation.html#selector_monitoring
http://kafka.apache.org/21/documentation.html#common_node_monitoring
http://kafka.apache.org/21/documentation.html#producer_monitoring
http://kafka.apache.org/21/documentation.html#producer_sender_monitoring
http://kafka.apache.org/21/documentation.html#consumer_monitoring
http://kafka.apache.org/21/documentation.html#consumer_fetch_monitoring
客户端监控流程架构如下图所示:
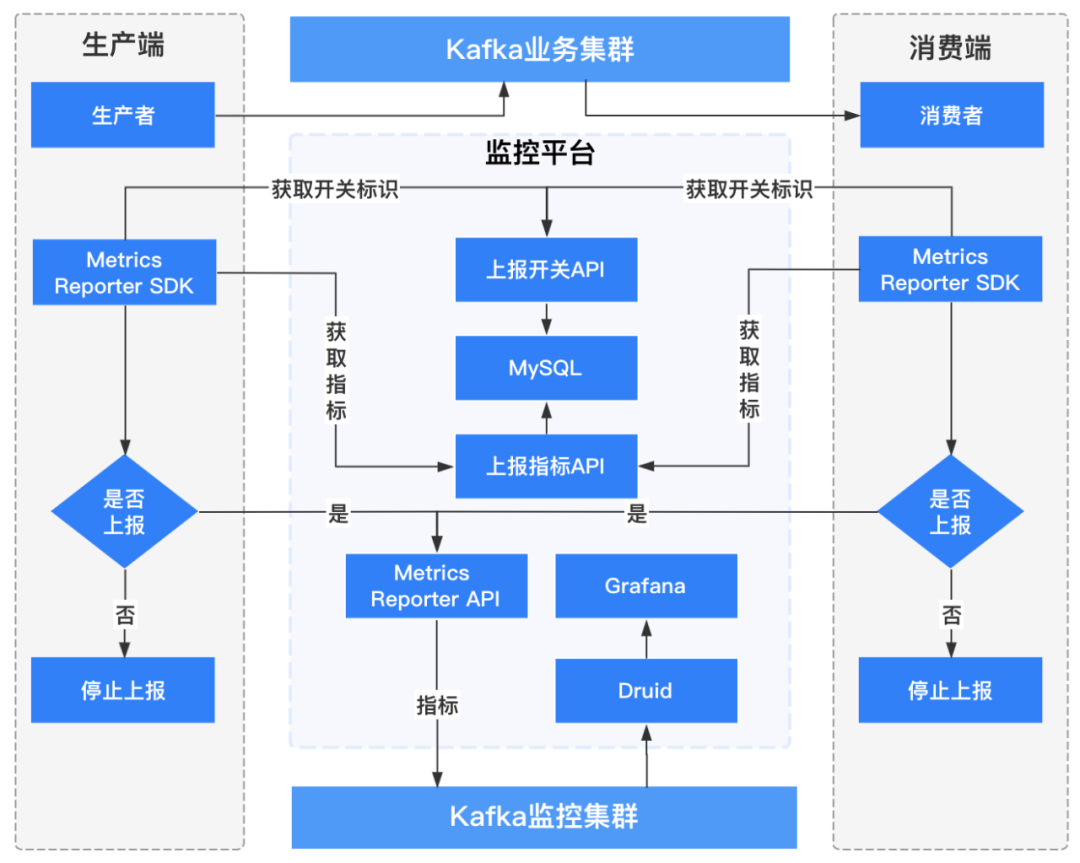
1.4.3.1 生产者客户端监控
维度:用户名称、客户端ID、客户端IP、topic名称、集群名称、brokerIP;
指标:连接数、IO等待时间、生产流量大小、生产记录数、请求次数、请求延时、发送错误/重试次数等。
1.4.3.2 消费者客户端监控
维度:用户名称、客户端ID、客户端IP、topic名称、集群名称、消费组、brokerIP、topic分区;
指标:连接数、io等待时间、消费流量大小、消费记录数、消费延时、topic分区消费延迟记录等。
开启JMX
kafka开启JMX的2种方式:
1. 启动kafka时增加JMX_PORT=9988,即JMX_PORT=9988 bin/kafka-server-start.sh -daemon config/server.properties
2. 修改kafka-run-class.sh脚本,第一行增加JMX_PORT=9988即可。
事实上这两种配置方式背后的原理是一样的,我们看一下kafka的启动脚本kafka-server-start.sh的最后一行exec $base_dir/kafka-run-class.sh $EXTRA_ARGS kafka.Kafka "$@",实际上就是调用kafka-run-class.sh脚本,其中有一段这样的内容:
配置好jmx并启动kafka后,可以启动jconsole验证jmx配置是否正确
jmx属性值的核心业务代码如下:如何使用JMX监控Kafka_朱小厮的博客-CSDN博客
public class KafkaJmxConnection {
private Logger log = LoggerFactory.getLogger(this.getClass());
private MBeanServerConnection conn;
/**
* 默认连接的ip和端口号
*/
private String ipAndPort = "localhost:9999";
public KafkaJmxConnection(String ipAndPort){
this.ipAndPort = ipAndPort;
}
public boolean init() throws Exception {
String jmxURL = "service:jmx:rmi:///jndi/rmi://" +ipAndPort+ "/jmxrmi";
log.info("init jmx, jmxUrl: {}, and begin to connect it",jmxURL);
try {
// 初始化连接jmx
JMXServiceURL serviceURL = new JMXServiceURL(jmxURL);
JMXConnector connector = JMXConnectorFactory.connect(serviceURL, null);
conn = connector.getMBeanServerConnection();
if(conn == null){
log.error("getValue connection return null!");
return false;
}
} catch (Exception e) {
e.printStackTrace();
return false;
}
return true;
}
public String getName(String metric, String topicName){
if (topicName==null){
return metric;
}
// 一些metric与topic有关, 如果要指定具体的topic的话
return metric + ",topic=" + topicName;
}
public Map<String, Object> getValue(String topicName, String metric, Collection<String> attrs){
ObjectName objectName;
try {
objectName = new ObjectName(this.getName(metric, topicName));
} catch (MalformedObjectNameException e) {
e.printStackTrace();
return null;
}
Map<String, Object> result = new HashMap<>();
// 遍历所有属性, 获取每个属性的结果, 并将属性和属性对应的结果保存到map中
for(String attr:attrs){
result.put(attr, getAttribute(objectName, attr));
}
return result;
}
public Map<String, Object> getValue(String metric, Collection<String> attrs){
return getValue(null, metric, attrs);
}
private Object getAttribute(ObjectName objName, String objAttr){
if(conn== null){
log.error("jmx connection is null");
return null;
}
try {
return conn.getAttribute(objName,objAttr);
} catch (Exception e) {
e.printStackTrace();
return null;
}
}
}从kafka官网摘取两个bean name:
- kafka.server:type=BrokerTopicMetrics,name=BytesInPerSec
kafka官方文档的解释:Byte in rate from clients。
属性列表:从jconsole上可以看到BytesInPerSec包含的属性有Count、MeanRate、RateUnit、EventType、OneMinuteRate、FiveMinuteRate、FifteenMinuteRate。
kafka.server:type=ReplicaManager,name=PartitionCount
kafka官方文档的解释:Partition counts。
属性列表:Value
下面的代码就以获取kafka.server:type=BrokerTopicMetrics,name=BytesInPerSec和kafka.server:type=ReplicaManager,name=PartitionCount为例:
public class KafkaMetricMain {
public static void main(String[] args) throws Exception {
KafkaJmxConnection jmxConn = new KafkaJmxConnection("10.0.55.229:9988");
jmxConn.init();
while(true) {
String topicName = "TPC_WALLET_UNFREEZE_DEDUCT_COMPENSATE";
// 与topic无关的metric
Object o1 = jmxConn.getValue(
"kafka.server:type=ReplicaManager,name=PartitionCount",
Lists.newArrayList("Value"));
System.out.println(o1);
// 与topic有关的metric
Object o2 = jmxConn.getValue(topicName,
"kafka.server:type=BrokerTopicMetrics,name=BytesInPerSec",
Lists.newArrayList("Count", "OneMinuteRate", "FiveMinuteRate"));
System.out.println(o2);
Thread.sleep(5000);
}
}
} 1.4.4 Zookeeper监控
1) Zookeeper进程监控;
2) Zookeeper的leader切换监控;
3) Zookeeper服务的错误日志监控;
1.4.5 全链路监控
当数据链路非常长的时候(比如:业务应用->埋点SDk->数据采集->Kafka->实时计算->业务应用),我们定位问题通常需要经过多个团队反复沟通与排查才能发现问题到底出现在哪个环节,这样排查问题效率比较低下。在这种情况下,我们就需要与上下游一起梳理整个链路的监控。出现问题时,第一时间定位问题出现在哪个环节,缩短问题定位与故障恢复时间。
二、自己生成消息监控
首先,我们可以自定义一种特殊的消息,然后启动一个监控程序将消息定时循环的写入到消息队列中,这个消息可以是生成一个时间戳。同时这个消息是可以被消费者消费的,当业务消费到的时候就将其丢弃,而监控程序消费这个消息是,就将其生成时间和消费时间进行对比,如果超过了我们预设的一定阈值就像我们报警。
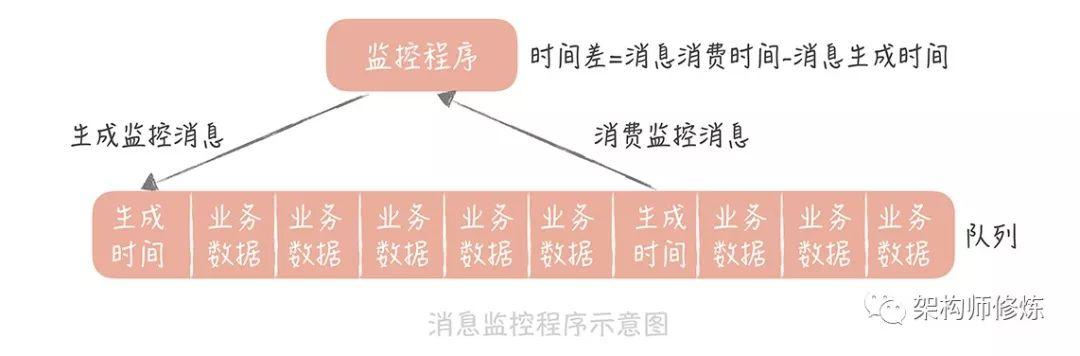
生产建议:上面两种方式都是可以监控消息延迟的,但是在实际生产中,这里推荐将他们两者进行结合来使用,比如,我们先可以在监控程序中通过JMX获取消息堆积数据,然后发送到我们的dashboard 中;同时起一个探测进程确认消息的延迟情况是怎样的。
通过上面我们都已经了解了消息延迟怎么进行监控,接下来我们再来看看怎么来提升消息的写入和消费性能,这样才能将异步消息更快的处理掉。
三、kafka学习笔记--使用java api监控Kafka消费者组的消费积压
/**
* @date 2020/1/6 10:04
* @description 获取Kafka指定消费者组堆积的偏移量, 并发送邮件预警
*/
@Slf4j
public class KafkaOffsetTools {
private static final Logger logger = LoggerFactory.getLogger(Property.class);
public static void main(String[] args) throws InterruptedException {
String topics = Property.getProperty("topics");
String broker = Property.getProperty("broker");
int port = 9092;
String servers = Property.getProperty("servers");
String clientId = Property.getProperty("clientId");
int correlationId = 0;
while (true) {
List<String> brokerlist = new ArrayList<>();
brokerlist.add(broker);
KafkaOffsetTools kafkaOffsetTools = new KafkaOffsetTools();
String[] topicArgs = topics.split(",");
StringBuilder sb = new StringBuilder();
for (String topic : topicArgs) {
TreeMap<Integer, PartitionMetadata> metadatas = kafkaOffsetTools.findLeader(brokerlist, port, topic);
List<TopicAndPartition> partitions = new ArrayList<>();
for (Entry<Integer, PartitionMetadata> entry : metadatas.entrySet()) {
int partition = entry.getKey();
TopicAndPartition testPartition = new TopicAndPartition(topic, partition);
partitions.add(testPartition);
}
String groups = Property.getProperty(topic);
String[] groupArgs = groups.split(",");
sb.setLength(0);
BlockingChannel channel = new BlockingChannel(broker, port, BlockingChannel.UseDefaultBufferSize(), BlockingChannel.UseDefaultBufferSize(), 5000);
for (String group : groupArgs) {
long sumLogSize = 0L;
long sumOffset = 0L;
long lag = 0L;
KafkaConsumer<String, String> kafkaConsumer = kafkaOffsetTools.getKafkaConsumer(group, topic, servers);
for (Entry<Integer, PartitionMetadata> entry : metadatas.entrySet()) {
int partition = entry.getKey();
try {
channel.connect();
OffsetFetchRequest fetchRequest = new OffsetFetchRequest(group, partitions, (short) 1, correlationId, clientId);
channel.send(fetchRequest.underlying());
/*
* 消费的commited offset, 针对kafka 0.9及以后的版本, 提交的offset可以选择保存在broker上的__consumer_offsets的内部topic上, Burrow还是通过sarama来消费__consumer_offsets这个topic来获取;
*/
OffsetAndMetadata committed = kafkaConsumer.committed(new TopicPartition(topic, partition));
long partitionOffset = committed.offset();
sumOffset += partitionOffset;//消费偏移量大小
/*
需要获取各group的消费的topic的各个partition的broker offset,就是实际生产的msg的条数, 通过sarama可以轻松获取, 当然这个需要周期性不间断获取;
* */
String leadBroker = entry.getValue().leader().host();
String clientName = "Client_" + topic + "_" + partition;
SimpleConsumer consumer = new SimpleConsumer(leadBroker, port, 100000, 64 * 1024, clientName);
// long readOffset = getLastOffset(consumer, topic, partition, kafka.api.OffsetRequest.LatestTime(), clientName);
long readOffset = getLastOffset(consumer, topic, partition, kafka.api.OffsetRequest.LatestTime(), consumer.clientId());
sumLogSize += readOffset; //消息总大小
logger.info("group: " + group + " " + partition + ":" + readOffset);
consumer.close();
} catch (Exception e) {
e.printStackTrace();
channel.disconnect();
}
}
logger.info("logSize:" + sumLogSize);
logger.info("offset:" + sumOffset);
lag = sumLogSize - sumOffset;
logger.info("lag:" + lag);
sb.append("消费者组 " + group + " 积压的偏移量为: " + lag).append("\n");
}
String title = topic + " 消费者消费情况";
EmailSender emailSender = new EmailSender();
emailSender.sendMail(title, sb.toString());
}
Thread.sleep(60000 * Integer.valueOf(Property.getProperty("sleepTime")));
}
}
/**
* 获取Kafka消费者实例
*
* @param group 消费者组
* @param topic 主题名
* @param servers 服务器列表
* @return KafkaConsumer<String, String>
*/
private KafkaConsumer<String, String> getKafkaConsumer(String group, String topic, String servers) {
Properties props = new Properties();
props.put("bootstrap.servers", servers);
props.put("group.id", group);
props.put("enable.auto.commit", "true");
props.put("auto.commit.interval.ms", "1000");
props.put("max.poll.records", 100);
props.put("session.timeout.ms", "30000");
props.put("auto.offset.reset", "earliest");
props.put("key.deserializer", StringDeserializer.class.getName());
props.put("value.deserializer", StringDeserializer.class.getName());
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props);
consumer.subscribe(Arrays.asList(topic));
return consumer;
}
private KafkaOffsetTools() {
}
/**
* 获取该消费者组每个分区最后提交的偏移量
*
* @param consumer 消费者组对象
* @param topic 主题
* @param partition 分区
* @param whichTime 最晚时间
* @param clientName 客户端名称
* @return 偏移量
*/
private static long getLastOffset(SimpleConsumer consumer, String topic, int partition, long whichTime, String clientName) {
TopicAndPartition topicAndPartition = new TopicAndPartition(topic, partition);
Map<TopicAndPartition, PartitionOffsetRequestInfo> requestInfo = new HashMap<>();
requestInfo.put(topicAndPartition, new PartitionOffsetRequestInfo(whichTime, 1));
OffsetRequest request = new OffsetRequest(requestInfo, kafka.api.OffsetRequest.CurrentVersion(), clientName);
OffsetResponse response = consumer.getOffsetsBefore(request);
if (response.hasError()) {
System.out.println("Error fetching data Offset Data the Broker. Reason: " + response.errorCode(topic, partition));
return 0;
}
long[] offsets = response.offsets(topic, partition);
return offsets[0];
}
/**
* 获取每个partation的元数据信息
*
* @param seedBrokers 服务器列表
* @param port 端口号
* @param topic 主题名
* @return TreeMap<Integer, PartitionMetadata>
*/
private TreeMap<Integer, PartitionMetadata> findLeader(List<String> seedBrokers, int port, String topic) {
TreeMap<Integer, PartitionMetadata> map = new TreeMap<>();
for (String broker : seedBrokers) {
SimpleConsumer consumer = null;
try {
consumer = new SimpleConsumer(broker, port, 100000, 64 * 1024, "leaderLookup" + new Date().getTime());
List<String> topics = Collections.singletonList(topic);
TopicMetadataRequest req = new TopicMetadataRequest(topics);
TopicMetadataResponse resp = consumer.send(req);
List<TopicMetadata> metaData = resp.topicsMetadata();
for (TopicMetadata item : metaData) {
for (PartitionMetadata part : item.partitionsMetadata()) {
map.put(part.partitionId(), part);
}
}
} catch (Exception e) {
System.out.println("Error communicating with Broker [" + broker + "] to find Leader for [" + topic + ", ] Reason: " + e);
} finally {
if (consumer != null)
consumer.close();
}
}
return map;
}
}

Kafka(六) ----使用Java api监控Kafka消费者组的消费积压_....-CSDN博客_java kafka 监控
二、解决方案:减少消息延时,消息堆积
我们可以通过在消费端和消息队列这两块来减少消息的延时。
1)如果是 Kafka 消费能力不足,则可以考虑增加 Topic 的分区数,并且同时提升消费组的消费者数量,消费者数=分区数。(两者缺一不可)
2)如果是下游的数据处理不及时:提高每批次拉取的数量 batchsize。批次拉取数据过少(拉取数据/处理时间<生产速度),使处理的数据小于生产的数据,也会造成数据积压。
1. topic增加分区
随着topic数据量增长,我们最初创建的topic指定的分区个数可能已经无法满足数量流量要求,所以我们需要对topic的分区进行扩展。扩容分区时需要考虑一下几点:
必须保证topic分区leader与follower轮询的分布在资源组内所有broker上,让流量分布更加均衡,同时需要考虑相同分区不同副本跨机架分布以提高容灾能力;
当topic分区leader个数除以资源组节点个数有余数时,需要把余数分区leader优先考虑放入流量较低的broker。
1 消费端
那我们在消费端该怎么处理呢?我们消费端处理的目标应该就是尽量的提升它的处理能力,可以这么做:
- 通过优化消费代码来提升性能。
- 增加消费者的数量。
不过第二种方式并不是对于所有的消费队列有效的,它是受消费队列限制的,比如Kafka 是不能通过增加消费者数量来提升消费性能的
因为,在 Kafka 中,一个 Topic 可以配置多个 Partition,数据会被平均或者按照生产者指定的方式写入到多个分区中,那么在消费的时候,Kafka 约定一个分区只能被一个消费者消费,为什么要这么设计呢?在我看来,如果有多个 consumer(消费者)可以消费一个分区的数据,那么在操作这个消费进度的时候就需要加锁,可能会对性能有一定的影响。
所以说,话题的分区数量决定了消费的并行度,增加多余的消费者也是没有用处的,你可以通过增加分区来提高消费者的处理能力。
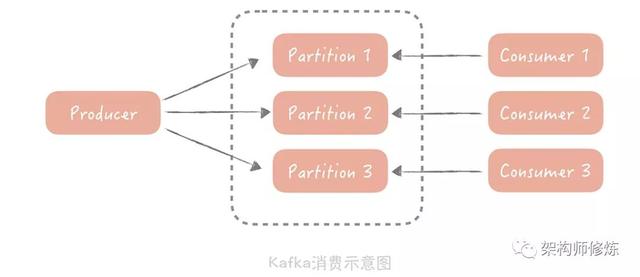
既然如此,那我们在不增加分区的情况下该怎么去提升消费性能呢?
我们虽然不能增加消费者,但是我们可以在消费者使用并行处理。所以我们就可以考虑使用多线程的方式来增加处理能力:
- 预先创建一个或者多个线程池。
- 拉取到消息丢到线程池中进行异步处理,将串行的消息消费变成了并行的。
- 不仅提高了吞吐量,还可以一次消费多拉取一些消息,分配给多个线程来处理。
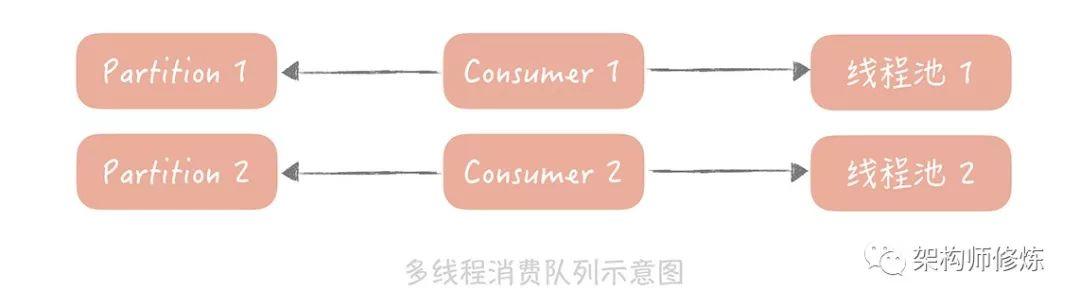
2 消息队列自身
如上我们学习到了怎么通过消费端来提升消息消费能力,那接下来我们要来看看消息队列自身在读取性能上该做些什么优化,其实有两个关键点:
- 消息存储
- 零拷贝技术
消息存储,应当使用本地磁盘作为存储介质。Page Cache 的存在就可以提升消息的读取速度,即使要读取磁盘中的数据,由于消息的读取是顺序的并且不需要跨网络读取数据,所以读取消息的 QPS 肯定是比普通数据库高很多很多。
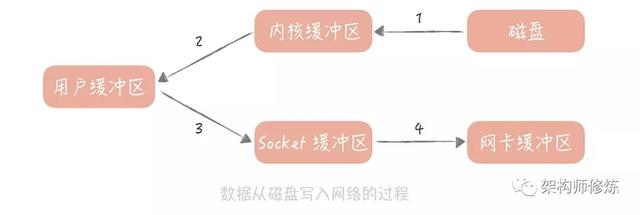
零拷贝技术,说是零拷贝,其实我们不可能消灭数据的拷贝,只是尽量减少拷贝的次数。在读取消息队列的数据的时候,其实就是把磁盘中的数据通过网络发送给消费客户端,在实现上会有四次数据拷贝的步骤:
- 数据从磁盘拷贝到内核缓冲区;
- 系统调用将内核缓存区的数据拷贝到用户缓冲区;
- 用户缓冲区的数据被写入到 Socket 缓冲区中;
- 操作系统再将 Socket 缓冲区的数据拷贝到网卡的缓冲区中。
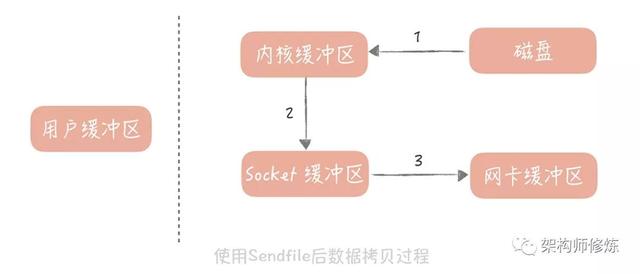
操作系统提供了 Sendfile 函数可以减少数据被拷贝的次数。使用了 Sendfile 之后,在内核缓冲区的数据不会被拷贝到用户缓冲区而是直接被拷贝到 Socket 缓冲区,节省了一次拷贝的过程提升了消息发送的性能。高级语言中对于 Sendfile 函数有封装,比如说在 Java 里面的 java.nio.channels.FileChannel 类就提供了 transferTo 方法提供了 Sendfile 的功能。
总结,我们通过提升消息队列的性能来减少消息消费的延迟,主要讲到了,
- 通过消息队列工具监控消息堆积数据以及通过监控生成消息方式进行监控消息延迟情况,
- 通过横向扩展消费者来增加处理能力
- 采取高性能的数据存储然后配合零拷贝技术,来提升消息消费性能。
所以,队列经常会用在我们项目当中,做好数据堆积监控是关键。希望今天的内容对你有所帮助,如果你喜欢就关注我,我会持续写一线互联网各种实战解决方案,谢谢。
————————————————
五、消息堆积延时如何解决、生产事故!几百万消息在消息队列里积压了几个小时!
07、完了!生产事故!几百万消息在消息队列里积压了几个小时!_一诺-CSDN博客
消息队列满了以后该怎么处理?有几百万消息持续积压几小时,说说怎么解决?
其实本质针对的场景,都是说,可能你的消费端出了问题,不消费了,或者消费的极其极其慢,举个例子,消费端每次消费之后要写mysql,结果mysql挂了,消费端宕那儿了,不动了。或者是消费端出了个什么叉子,导致消费速度极其慢。
可能你的消息队列集群的磁盘都快写满了,都没人消费,这个时候怎么办?或者是整个这就积压了几个小时,你这个时候怎么办?或者是你积压的时间太长了,几千万条数据在kafka里积压了七八个小时 ,导致比如rabbitmq设置了消息过期时间后就没了怎么办?
方案一:修复consumer的问题,让他恢复消费速度
这个是我们真实遇到过的一个场景,确实是线上故障了,这个时候要不然就是修复consumer的问题,让他恢复消费速度,一个消费者一秒是1000条,一秒3个消费者是3000条,一分钟是18万条,1000多万条。所以如果你积压了几百万到上千万的数据,即使消费者恢复了,也需要大概1小时的时间才能恢复过来然后傻傻的等待几个小时消费完毕。这个肯定不能在面试的时候说吧。
方案二:新建一个topic,partition是原来的10倍,重新部署一个consumer程序消费
一般这个时候,只能操作临时紧急扩容了,具体操作步骤和思路如下:
1)先修复consumer的问题,确保其恢复消费速度,然后将现有consumer都停掉
2)新建一个topic,partition是原来的10倍,临时建立好原先10倍或者20倍的queue数量
3)然后写一个临时的分发数据的consumer程序,这个程序部署上去消费积压的数据,消费之后不做耗时的处理,直接均匀轮询写入临时建立好的10倍数量的queue
4)接着临时征用10倍的机器来部署consumer,每一批consumer消费一个临时queue的数据
5)这种做法相当于是临时将queue资源和consumer资源扩大10倍,以正常的10倍速度来消费数据
6)等快速消费完积压数据之后,得恢复原先部署架构,重新用原先的consumer机器来消费消息
问题:新建一个topic、重新部署一个consumer程序,也许需要很长时间,修复consumer重新慢慢消费估计也差不多了

(2)这里我们假设再来第二个坑,大量的数据丢失怎么办,方案:重新发送
假设你用的是rabbitmq,rabbitmq是可以设置过期时间的,就是TTL,如果消息在queue中积压超过一定的时间就会被rabbitmq给清理掉,这个数据就没了。那这就是第二个坑了。这就不是说数据会大量积压在mq里,而是大量的数据会直接搞丢。
这个情况下,就不是说要增加consumer消费积压的消息,因为实际上没啥积压,而是丢了大量的消息。我们可以采取一个方案,就是批量重导,这个我们之前线上也有类似的场景干过。就是大量积压的时候,我们当时就直接丢弃数据了,然后等过了高峰期以后,比如大家一起喝咖啡熬夜到晚上12点以后,用户都睡觉了。
这个时候我们就开始写程序,将丢失的那批数据,写个临时程序,一点一点的查出来,然后重新灌入mq里面去,把白天丢的数据给他补回来。也只能是这样了。
假设1万个订单积压在mq里面,没有处理,其中1000个订单都丢了,你只能手动写程序把那1000个订单给查出来,手动发到mq里去再补一次
(3)然后我们再来假设第三个坑:长时间都没处理掉,此时导致消息队列都快写满了,咋办
如果走的方式是消息积压在mq里,那么如果你很长时间都没处理掉,此时导致mq都快写满了,咋办?这个还有别的办法吗?没有,谁让你第一个方案执行的太慢了,你临时写程序,接入数据来消费,消费一个丢弃一个,都不要了,快速消费掉所有的消息。然后走第二个方案,到了晚上再补数据吧。
五 spark streaming 处理kafka中积压的数据
spark streaming 处理kafka中积压的数据
spark streaming冷启动处理kafka中积压的数据
因为首次启动JOB的时候,由于冷启动会造成内存使用太大,为了防止这种情况出现,限制首次处理的数据量
spark.streaming.backpressure.enabled=true
spark.streaming.backpressure.initialRate=200
举个例子:
#!/bin/sh
TaskName="funnel"
UserName="hadoop"
cd `dirname $0`
nohup sudo -u ${UserName} /data/bigdata/spark/bin/spark-submit \
--name ${TaskName} \
--class FunnelMain \
--master yarn \
--deploy-mode cluster \
--executor-memory 2G \
--num-executors 3 \
--conf spark.streaming.backpressure.enabled=true \
--conf spark.streaming.backpressure.initialRate=1000 \
--files /data/apps/funnel/app/conf/conf.properties \
/data/apps/funnel/app/target/apphadoop-1-jar-with-dependencies.jar conf.properties >>../log/${TaskName}.log 2>&1 &
exit 0使用SparkStreaming集成kafka时有几个比较重要的参数:
- spark.streaming.stopGracefullyOnShutdown (true / false)默认fasle。。确保在kill任务时,能够处理完最后一批数据,再关闭程序,不会发生强制kill导致数据处理中断,没处理完的数据丢失
- spark.streaming.backpressure.enabled (true / false) 默认false。。开启后spark自动根据系统负载选择最优消费速率
- spark.streaming.backpressure.initialRate (整数)。。默认直接读取所有 在(2)开启的情况下,限制第一次批处理应该消费的数据,因为程序冷启动队列里面有大量积压,防止第一次全部读取,造成系统阻塞
- spark.streaming.kafka.maxRatePerPartition (整数)。。默认直接读取所有限制每秒每个消费线程读取每个kafka分区最大的数据量
特别注意:
只有(4)激活的时候,每次消费的最大数据量,就是设置的数据量,如果不足这个数,就有多少读多少,如果超过这个数字,就读取这个数字的设置的值
只有(2)+(4)激活的时候,每次消费读取的数量最大会等于(4)设置的值,最小是spark根据系统负载自动推断的值,消费的数据量会在这两个范围之内变化根据系统情况,但第一次启动会有多少读多少数据。此后按(2)+(4)设置规则运行
(2)+(3)+(4)同时激活的时候,跟上一个消费情况基本一样,但第一次消费会得到限制,因为我们设置第一次消费的频率了。
Spark Streaming 重启后Kafka数据堆积调优
问题:
当应用由于各种其它因素需要暂停消费时,下一次再次启动后就会有大量积压消息需要进行处理,此时为了保证应用能够正常处理积压数据,需要进行相关调优。
另外对于某个时刻,某个topic写入量突增时,会导致整个kafka集群进行topic分区的leader切换,而此时Streaming程序也会受到影响。
所以针对以上问题我们进行了如下调优:
spark.streaming.concurrentJobs=10:提高Job并发数,读过源码的话会发现,这个参数其实是指定了一个线程池的核心线程数而已,没有指定时,默认为1。
spark.streaming.kafka.maxRatePerPartition=2000:设置每秒每个分区最大获取日志数,控制处理数据量,保证数据均匀处理。
spark.streaming.kafka.maxRetries=50:获取topic分区leaders及其最新offsets时,调大重试次数。
在应用级别配置重试
spark.yarn.maxAppAttempts=5
spark.yarn.am.attemptFailuresValidityInterval=1h
此处需要【注意】:
spark.yarn.maxAppAttempts值不能超过hadoop集群中yarn.resourcemanager.am.max-attempts的值,原因可参照下面的源码或者官网配置。

















 9302
9302











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











