




 本文介绍了网易有数大数据平台通过数据沙箱机制,实现开发模式与线上模式任务的隔离,避免代码修改影响线上数据。通过开发生产双集群和数据脱敏,确保开发过程中的数据安全,提升开发与生产的效率。
本文介绍了网易有数大数据平台通过数据沙箱机制,实现开发模式与线上模式任务的隔离,避免代码修改影响线上数据。通过开发生产双集群和数据脱敏,确保开发过程中的数据安全,提升开发与生产的效率。
大数据平台不仅需要稳定地运行生产任务,还需要提供数据开发的能力。因此,不少大数据平台都会为每个任务区分开发模式与线上模式,可以通过提交上线的方式,将开发模式任务提交到线上,让其用于线上数据生产工作。
开发模式与线上模式其实可以看成两个代码相似,但完全独立的任务,为了便于后续描述,将其分别称为开发模式任务与线上模式任务。

 开发模式下的任务可以进行编辑、运行、调试。当任务开发完毕后,通过提交上线功能,将开发模式的任务提交到线上,也即使用开发模式的任务代码覆盖原本的线上模式任务代码。线上模式下的任务是用于生产的,因此该模式下的任务不可以编辑、调试,但可以配置调度、依赖、报警。
开发模式下的任务可以进行编辑、运行、调试。当任务开发完毕后,通过提交上线功能,将开发模式的任务提交到线上,也即使用开发模式的任务代码覆盖原本的线上模式任务代码。线上模式下的任务是用于生产的,因此该模式下的任务不可以编辑、调试,但可以配置调度、依赖、报警。
问题背景
开发模式任务与线上模式任务代码虽然相似,但却是完全独立的,修改开发模式任务,并不会影响到线上模式任务。这在一定程度上避免了“开发阶段影响线上”的问题,但在实际的开发过程中,用户在调试某个开发任务时,由于数据与线上任务是同一份(引用了同一个 table 或者同一份 hdfs 数据),因此极易影响到线上的产出数据,造成线上数据被污染情况。
例如,某线上模式任务的代码如下:

由于业务需求的改变,需要将 ods_student 的数据按照年龄进行过滤(仅需要小于 18 岁的学生数据),则 SQL 被改写成:

但该 SQL 在开发阶段如果执行的话,会直接影响到线上的数据。针对该问题,大部分数据开发人员会建立一个 school.dwd_student_dev 表(该表作为 school.dwd_student 的开发表),然后在开发模式下写入数据到该表。
在提交上线时,再将 school.dwd_student_dev 改成 school.dwd_student。
虽然这样可以在一定程度上避免数据污染问题,但需要在提交上线时修改代码。由于生产级别的 SQL 非常复杂,会涉及很多表,因此很容易导致数据开发人员出现漏改、错改的情况。一旦将错误的代码提交上线后,便会导致线上问题/事故。
传统方案及优化空间
针对上述问题,业内最常见的解决方案是搭建完全独立的两套集群(不仅包含 hadoop 集群,还包含大数据平台子系统),一套作为开发集群、一套作为线上集群。在开发集群进行数据开发、测试,经过验证后,再通过手动/半自动的方式将开发任务、调度信息导入到线上集群。

传统双集群架构图
这种方式虽然完全避免了开发阶段影响线上的问题,但却失去了一些灵活性。
1. 实际的开发场景会经常遇到:开发阶段,需要读取线上数据进行开发、测试(往往是开发集群无此数据、或者在任务调优阶段开发集群数据量过小,无法模拟真实场景)。为了满足读取线上数据的需求,只能在使用的时候导入线上数据。导数过程非常耗时,针对一个存储数据较多的 table/hdfs 往往需要数个小时,这无疑给此方案增加了很多使用成本,致使该方案难以在业务落地。
2. 由于线上集群、开发集群是两套完全独立大数据平台,而且它们中间还需要保持数据的一致性(任务、表、调度数据的一致性)。众所周知,一致性在两套系统中是很难保证的,因此极有可能出现:提交上线的时候,发现线上没有该表;该表字段与开发集群不一致;设置依赖时发现被依赖的任务在线上集群不存在等等。
基于数据沙箱的集群隔离方案
网易有数大数据平台,引入了一种“数据沙箱”的机制,将代码与代码运行所需要的数据、环境变量解耦,根据代码的运行环境,自动关联所需要的数据和环境变量。一套代码,可以在不同的环境之间,无缝切换。下面,我们重点介绍一下,数据沙箱在生产、测试物理集群隔离场景下的应用。
“开发、生产双集群”方案的架构图如下所示:
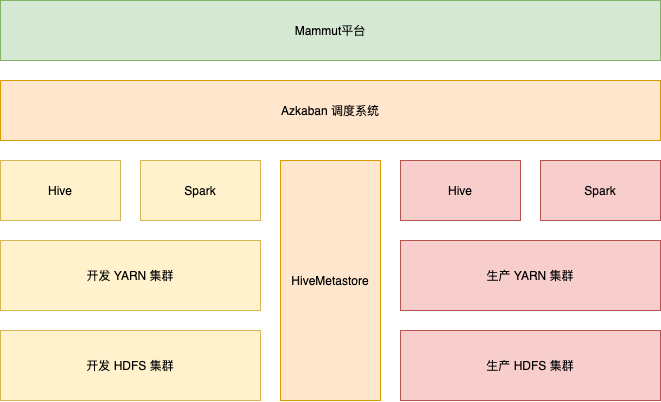
通过架构图可以看出,网易有数大数据平台具备真正意义上的开发模式任务与线上模式任务的数据、计算隔离。
在双集群场景下,网易有数大数据平台拥有两套独立的 HDFS 集群与 YARN 集群,在开发模式下默认读写开发 HDFS 集群,在线上模式下默认读写线上 HDFS 集群。这两套集群公用同一个 HiveMetastore 服务,开发模式下的 table 处于开发库下面,线上模式下的 table 处于线上库下面,这两个 table 的 location 分别指向开发 HDFS 集群、线上 HDFS 集群。同时,网易有数大数据平台还提供 ${database} 的宏定义,在开发模式下支持将其自动替换为 database_dev,在线上模式下支持将其自动替换为 database。
以 school.ods_study 表举例,对应的开发表为 school_dev.ods_study。它们的 location 分别为:
线上表为“hdfs://online/warehouse/school.db/ods_study/”;
开发表为“hdfs://dev/warehouse/school.db/ods_study/”。
可以看出这两个表的 location 只有 authority 不同,path 部分完全一致。这样无论是使用 SQL 直接读写这两个表,还是通过 hdfs 操作这两个表的数据(外表操作),结合宏定义之后,代码都是完全相同的。
基于数据沙箱的开发生产双集群应用实践
在介绍完网易有数大数据平台“开发、生产双集群”功能的实现后,再了解一下双集群的使用姿势,以便更好的理解双集群的实现细节。
ETL 任务大部分都是 SQL 任务(操作 hive 表),还有少部分 MR、SparkRDD 任务(直接操作 HDFS 数据)。
操作SQL
开发阶段仅读写开发集群数据
SQL 编写如下:

该 SQL 在开发模式下运行,相当于执行如下 SQL:

该 SQL 在线上模式下运行,相当于执行如下 SQL:

从开发模式与线上模式的 SQL 可以看出,该 SQL 在提交上线时完全不需要修改代码的,便可以在执行时通过宏替换的方式,动态的完成开发模式下读写开发集群数据,线上模式下读写线上集群数据。
开发阶段读线上集群数据,写开发集群数据
SQL 编写如下:

该 SQL 在开发模式下运行,相当于执行如下 SQL:

该 SQL 在线上模式下运行,相当于执行如下 SQL:

从开发模式与线上模式的 SQL 可以看出,该 SQL 在提交上线时完全不需要修改代码的,便可以在执行时通过宏替换的方式,动态的完成开发模式下读线上集群数据写入到开发集群,线上模式下读线上集群数据写入到线上集群。
操作 HDFS
HDFS 双集群使用姿势与 SQL 双集群使用姿势基本类似,SQL 是通过宏定义实现的,HDFS 是通过 default.fs 实现的。
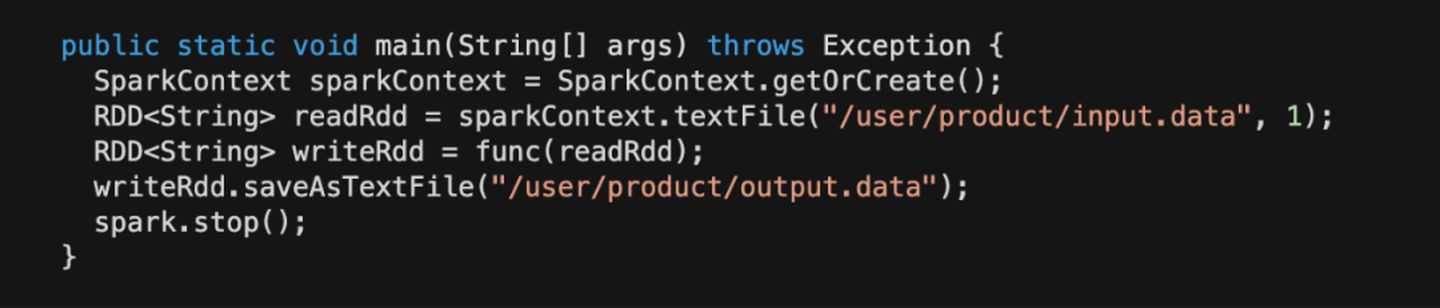
比如:读开发集群的 HDFS 数据,写入到开发集群的 HDFS。
读开发集群的 HDFS 数据,写入到线上集群的 HDFS。
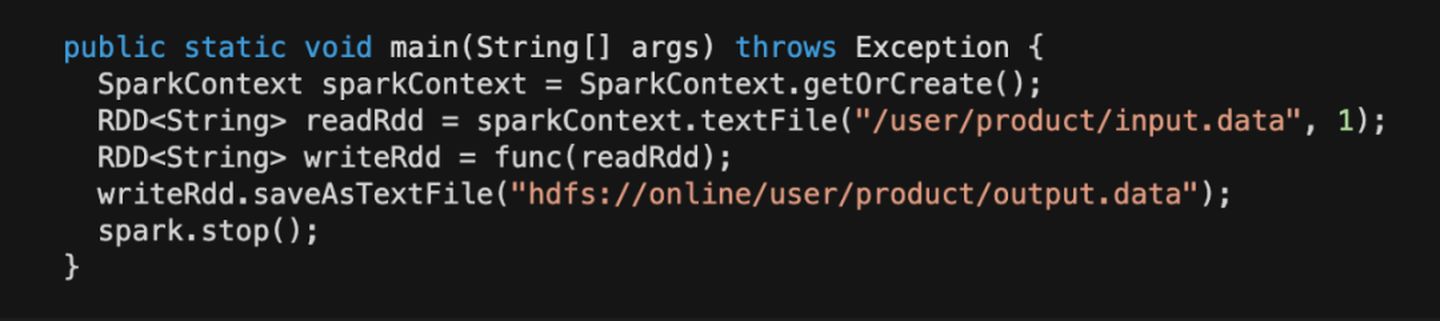
通过代码对比可以发现,使用MR、SparkRDD操作 HDFS 数据时,也无需修改代码即可提交上线,同一份代码在两套环境都完全适用。同时还完全保留了,开发环境读写开发集群数据、开发环境读线上数据,写开发数据的特性。
应用效果
网易有数大数据平台通过开发、生产双集群,实现了开发模式任务与线上模式任务,在代码、数据、计算上的隔离,同时在提交上线节点还避免了修改代码。通过开发、生产双集群功能,即保证了开发的效率,还保证了线上数据不被污染的问题。
同时,在开发、生产双集群中,网易大数据平台还引入了数据脱敏的功能,在开发阶段,如果读取线上敏感数据,将会进行脱敏处理。在保证数据安全的前提下,解决了数据开发、测试、发布阶段效率问题。
华泰集团:统一客户沙箱平台系统
项目背景及目标
大数据时代,对海量数据的搜集、存储、分析、挖掘及应用已是大势所趋,因此需要有专门的平台及相应产品来专门进行大数据的分析和挖掘;保险公司沉淀了几十年的客户交易数据,随着保险业务模式的不断创新,数据量呈现指数级增长,数据来源也更加多元化;目前各个保险公司都在密切的搜集客户多方面数据,在营销、风控、核保、理赔、定价等方面进行更好的应用。
目前公司数据分析、挖掘等涉及计算资源分散,可利用的工具有限及计算资源和效率较低,不能进行大规模数据挖掘,且无法统一进行管理;需要一个集成相关多种数据分析工具的统一平台来完成整个数据解决方案;当前各个子公司的数据没有整合,数据分析人员仅能在不同的子平台进行数据分析,不能对客户进行更完整的刻画;跨平台、公司访问数据需要频繁申请,数据安全及工作效率不能保证因此需要提供一个综合统一的平台,提供为一整套数据解决方案实施的平台。
项目方案
平台架构
数据沙箱是客户统一平台的重要组成部分,沙箱整合产、寿等子公司各系统数据,在集团层面做客户打通,并相应的为子公司提供客户画像、保单查询、精准营销等方面工作;数据沙箱提供了为一整套数据解决方案实施的平台,链接平台各层数据源,集合多种数据分析、挖掘工具,支持数据探查、分析、建模及报表展示等多种工作。
下图为基于大数据平台的沙箱架构图:
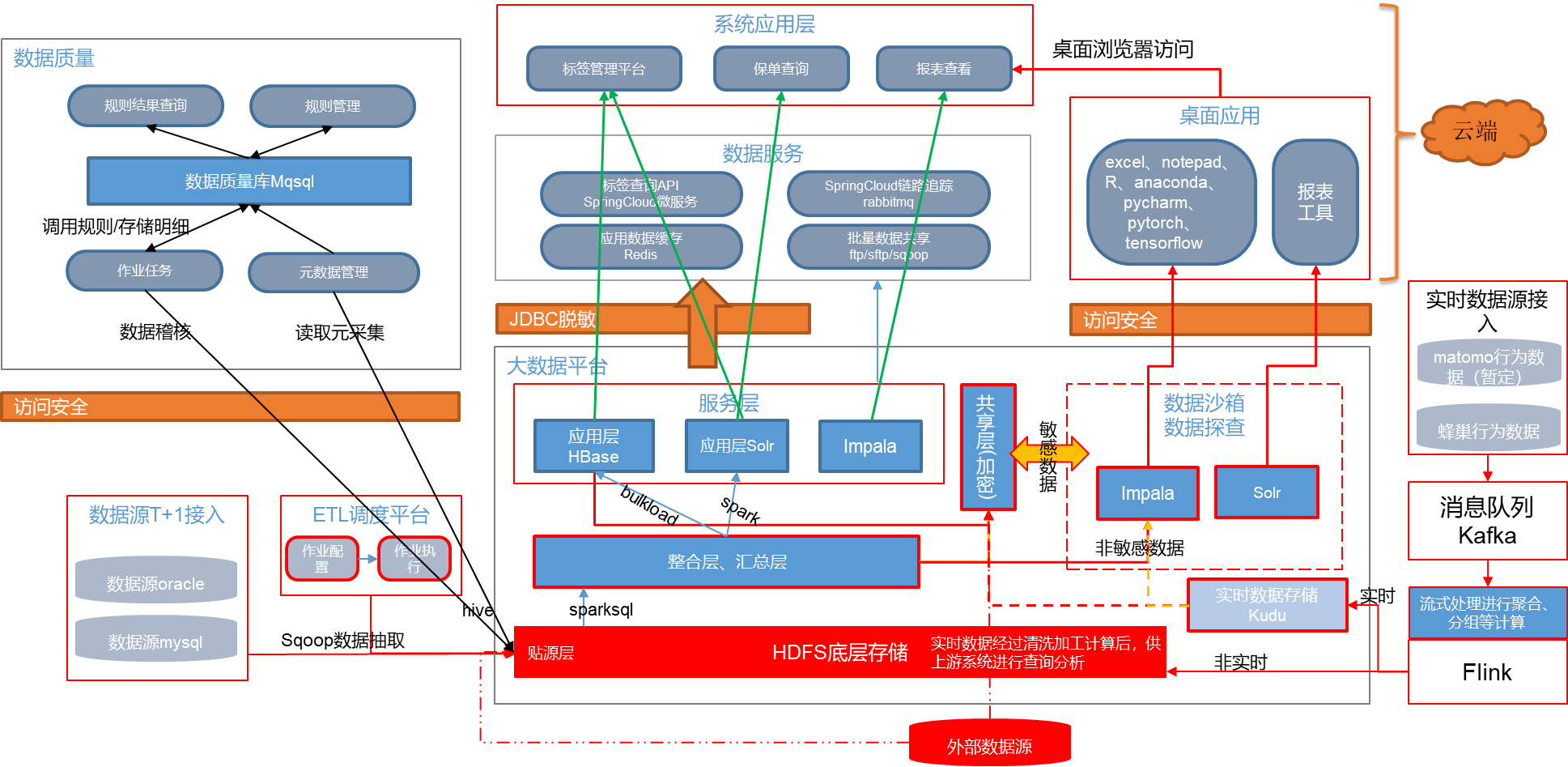
下图为沙箱的一个物理架构图:
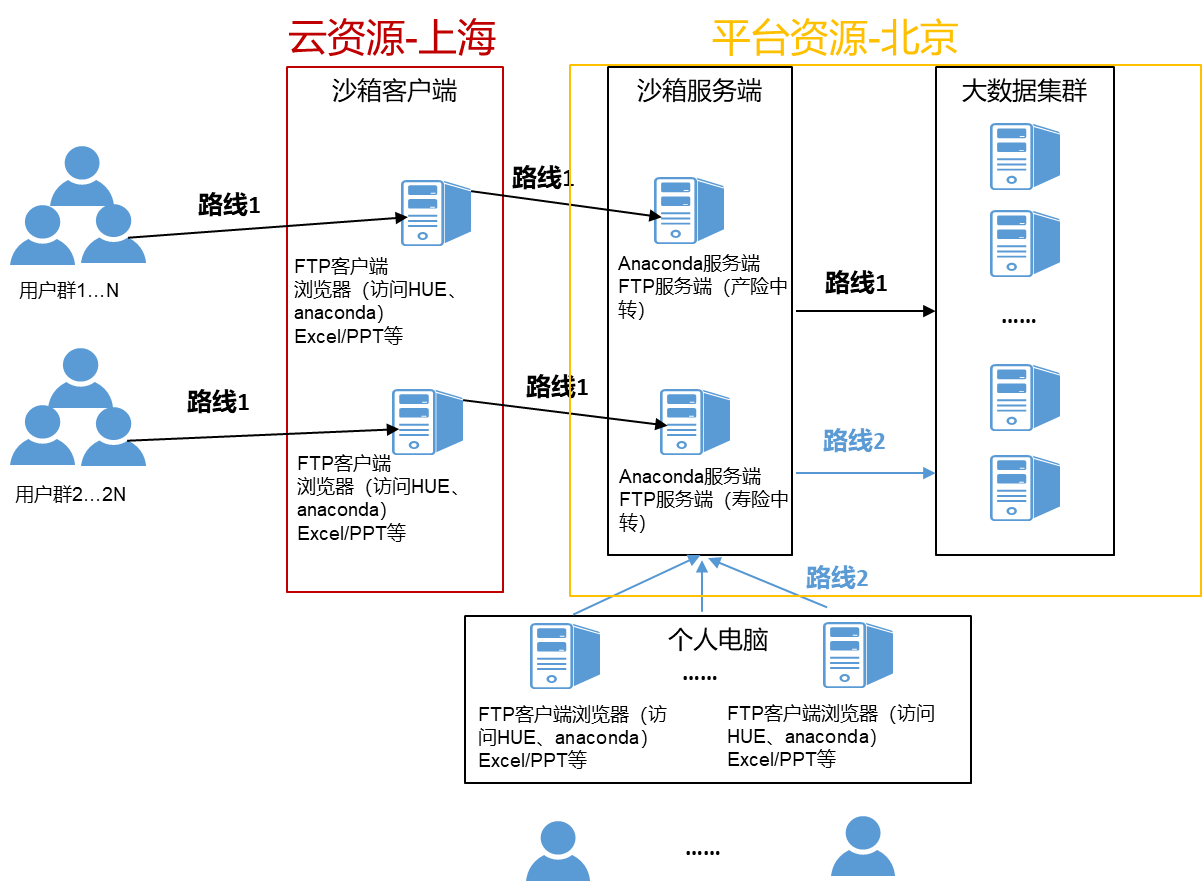
创新点
性能优越:沙箱计算资源庞大,整合了大数据平台计算资源,支持大规模数据并行计算,通过开通账号,使得整个集团人员能够集中在平台中进行数据分析挖掘;
数据全面:整合全集团数据,同时也可以接入外部数据,和平台共享一套数据源,与平台各层互通,保证数据可获得、一致、便捷高效;
多种数据挖掘工具:可实现一站式数据解决方案;多种数据挖掘工具可利用,如sql查询工具、excel、python、spark等;
支持业务报表查询:支持业务统计指标的web展示、提供BI工具协助进行数据分析、报表发布;
人员权限及数据安全:支持多租户分权限分资源管理;对敏感数据进行加密处理;
使用便捷:提供进入、使用沙箱环境的友好界面,方便非开发数据分析人员使用;
提供算法平台,支持可视化建模,降低建模门槛。
提供云办公桌面,解决个人电脑设备老、旧、性能差的问题
项目主要建设内容及功能
1、沙箱云服务办公环境
沙箱为每位用户提供一个远程的windows办公环境,并安装常用的数据分析工具,如office、notepad、anaconda等;在安全方面,为每个用户提供仅供个人访问的目录来保证个人数据的私密,同时提供共享文件夹,方便进行不同用户之间文件的传输。
云办公桌面展示如下:

2、沙箱数据挖掘notebook环境
当需要进行大批量数据分析、挖掘时,可使用沙箱专供的数据挖掘工具-jupterhub来执行;
沙箱安装了anaconda运行环境,集成了较新的python及相应的很多数据分析、建模包,jupterhub的notebook是一个数据图形化GUI展示工具,能够通过浏览器打开,方便数据挖掘人员使用。
沙箱数据挖掘notebook环境界面展示如下:
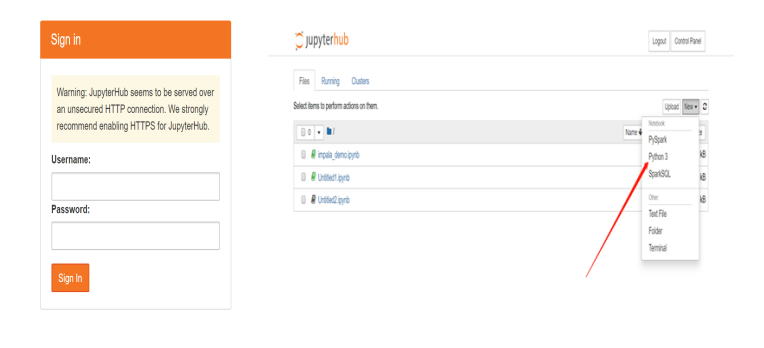
点击python3即可进入相应的交互式编程,沙箱针对该工具已安装常用的机器学习算法,包括目前主流的算法:scikit-learn的所有算法(如Random Forest、SVM等)、XGBoost、LightGBM等;深度学习如:pytorch、tensorflower(不支持GPU);同时已为每位用户创建单独的文件夹;同时也安装了pyimpala、pyspark等,支持连接大数据平台,利用大数据平台资源进行快速的大数据分析及分布式建模等。
3、大数据分析交互平台HUE
沙箱为用户提供一个快速的大数据查询平台,通过Hue可使用Hive、impala进行数据分析,通过impala进行sql查询分析,性能优越,传统数据库查询耗时费力,而通过impala进行查询,速度一般都能提升10倍以上,同时可以通过python连接impala,通过python端进行sql查询,还可以将云办公桌面的客户端连接到大数据平台进行查询。
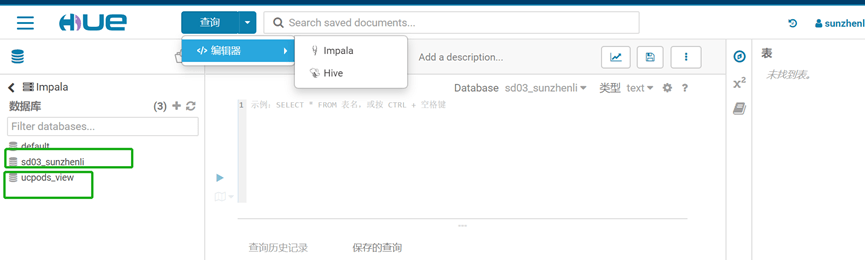
3、大数据分析交互平台HUE
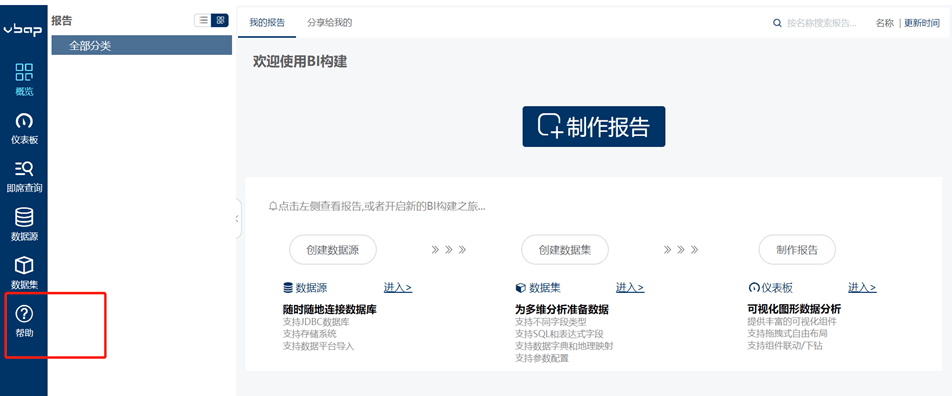
沙箱提供了专门的BI工具,通过该工具,可以连接数据库,并对数据进行探查、分析并制作固定报表等。
BI工具展示如下:
沙箱AI算法平台工具
沙箱提供了专门的AI算法平台工具,通过该工具,大大降低算法使用的门槛,使得部分非专业人员能够自行建模,挖掘业务价值。
AI 算法平台展示如下:
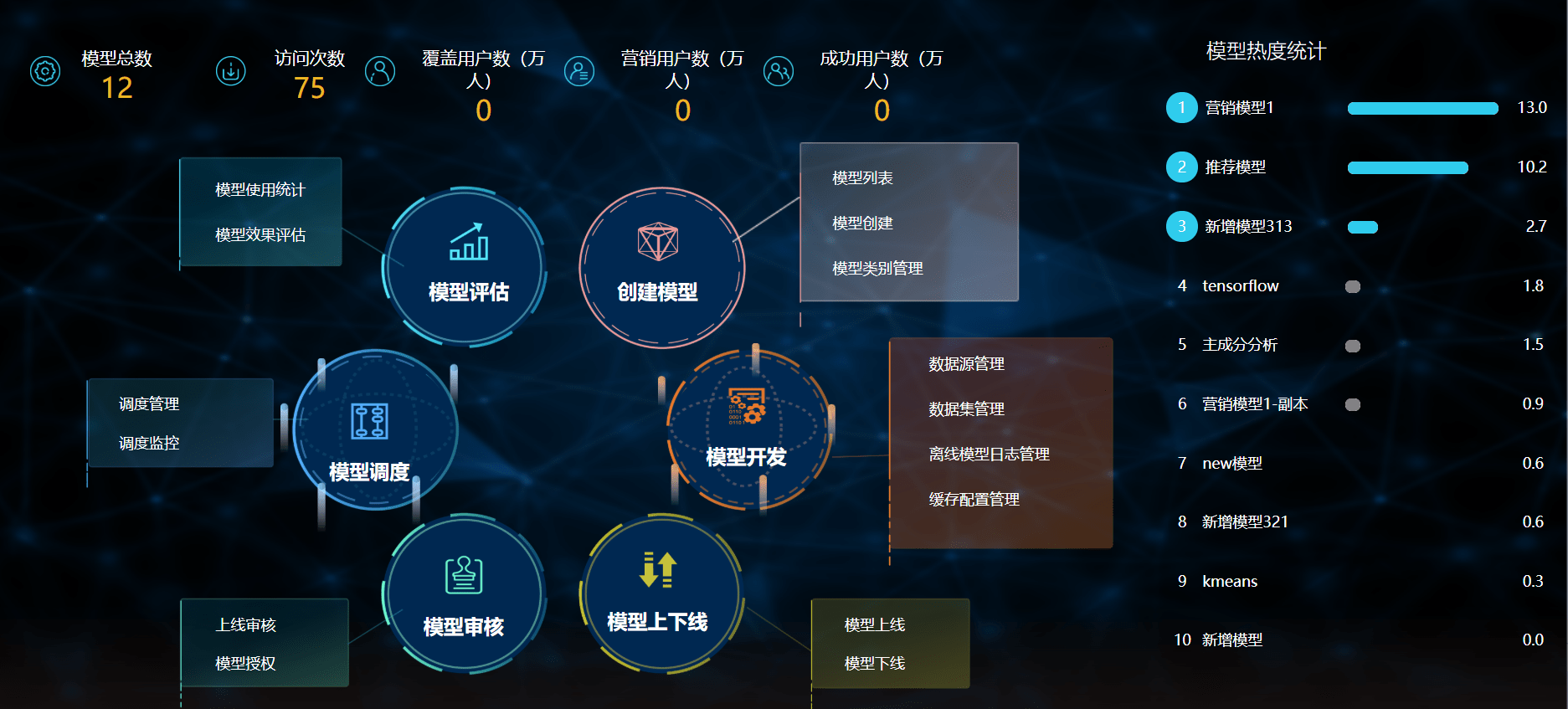
项目过程管理
1、需求分析和概要设计阶段
此阶段时间段为2019年9月至2020年2月,其间主要完成了业务需求分析、业务功能和技术构架的高层设计。提交了现状需求分析报告、各功能模块的高层设计、技术构架和接口的高层设计等文档。
2、系统详细设计阶段
此阶段起始时间为2020年2月至2020年3月,其间主要完成了沙箱系统详细设计工作,确定沙箱的主要建设方案及功能重点。
3、系统开发、测试和上线准备阶段
此阶段起始时间为2020年3月至2020年7月,完成了平台搭建、数据接入、数据加工整合、产品部署等,编写了测试用例和操作手册。
4、上线阶段
此阶段起始时间为2020年8月至今,沙箱处于正式上线使用状态,已开放给各个子公司相关部门人员使用
项目成效
沙箱平台旨在通过打造综合的数据挖掘平台,来提升整个集团的数字化运用、分析能力。沙箱主要服务于数据分析人员,通过提供强大的计算资源、整合多种分析工具,并实行统一的用户管理,方便数据分析人员进行有价值的数据挖掘,赋能于公司业务发展。在投入使用过程中得到了广大子公司及多部门的青睐,如下为部分沙箱的具体支持案例:
沙箱目前服务的部门有:集团精算部、集团综合创新部、集团内审部、集团资产管理部、财险的科创部、财险精算部、财险车险部、目前累计开通近100个用户,并在持续推广中;
支持财险科创产寿交叉和车险续保率预测的相关数据挖掘、建模工作;
支持用户数据分析及财务报表ocr文本识别等具体工作;
支持集团综合创新部进行产寿交叉分析等方面的工作;
支持集团资产管理部相关性热力图展示的统计分析。
经验总结
让数据产生价值的重要一环就是搭建一个强大的分析挖掘平台,沙箱不直接面向市场,但通过提供分析平台来协助相关的业务及管理人员来支持运营决策;通过沙箱可以实现对客户的分类,筛选优质客户,预测客户产品偏好,更全面支持客户画像、统计报表分析、提供运营决策数据等等



















 610
610

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











