







FREEMATCH: SELF-ADAPTIVE THRESHOLDING FOR SEMI-SUPERVISED LEARNING
-
- 摘要
- 引言
- 2 动机
- 3 准备工作
- 4 freematch
- 5 实验
- 6 相关工作
- 7 结论
SEMI-SUPERVISED LEARNING)
摘要
半监督学习(SSL)由于伪标签和一致性正则化等各种方法带来的出色表现,取得了巨大成功。然而,我们认为现有方法可能未能更有效地利用未标记数据,因为它们要么使用预定义的/固定的阈值,要么采用临时的阈值调整方案,导致性能下降和收敛速度缓慢。我们首先分析了一个激励示例,以直观理解理想阈值与模型学习状态之间的关系。基于此分析,我们提出了FreeMatch,通过根据模型的学习状态自适应地调整置信度阈值。我们进一步引入了自适应类别公平正则化惩罚,以在早期训练阶段鼓励模型进行多样化的预测。大量实验表明,FreeMatch在标记数据极其稀少的情况下具有明显的优势。在CIFAR-10(每类1个标签)、STL-10(每类4个标签)和ImageNet(每类100个标签)上,FreeMatch相较于最新的最先进方法FlexMatch分别实现了5.78%、13.59%和1.28%的错误率减少。此外,FreeMatch还能提升不平衡半监督学习的表现。代码可在https://github.com/microsoft/Semi-supervised-learning获取。
引言
深度学习的卓越性能在很大程度上依赖于使用充足标注数据的监督训练 (He et al., 2016; Vaswani et al., 2017; Dong et al., 2018)。然而,获取大量标注数据仍然是一项费时且昂贵的任务。为减轻这种依赖,半监督学习(SSL)(Zhu, 2005; Zhu & Goldberg, 2009; Sohn et al., 2020; Rosenberg et al., 2005; Gong et al., 2016; Kervadec et al., 2019; Dai et al., 2017) 被开发出来,通过利用大量未标记数据来提高模型的泛化性能。伪标签 (Lee et al., 2013; Xie et al., 2020b; McLachlan, 1975; Rizve et al., 2020) 和一致性正则化 (Bachman et al., 2014; Samuli & Timo, 2017; Sajjadi et al., 2016) 是现代SSL中的两大主流范式。最近,二者的结合显示出了有希望的结果 (Xie et al., 2020a; Sohn et al., 2020; Pham et al., 2021; Xu et al., 2021; Zhang et al., 2021)。其核心思想是,模型应当在不同的扰动下为相同的未标记数据产生相似的预测或相同的伪标签,这符合SSL中的平滑性和低密度假设 (Chapelle et al., 2006)。
这些基于阈值的方法的一个潜在局限性在于,它们要么需要一个固定阈值 (Xie et al., 2020a; Sohn et al., 2020; Zhang et al., 2021; Guo & Li, 2022),要么需要一个临时的阈值调整方案 (Xu et al., 2021) 来仅使用高置信度的未标记样本计算损失。具体而言,UDA (Xie et al., 2020a) 和 FixMatch (Sohn et al., 2020) 采用了一个固定的高阈值来确保伪标签的质量。然而,固定的高阈值(0.95)在训练早期阶段可能导致数据利用率低,并忽略不同类别的学习难度差异。Dash (Xu et al., 2021) 和 AdaMatch (Berthelot et al., 2022) 提出随着训练的进行逐步提升固定的全局(数据集特定)阈值。虽然未标记数据的利用率有所提高,但它们的临时阈值调整方案受超参数的任意控制,与模型的学习过程脱节。FlexMatch (Zhang et al., 2021) 表明,不同类别应有不同的局部(类别特定)阈值。尽管局部阈值考虑了不同类别的学习难度,它们仍然是从预定义的固定全局阈值映射得来的。Adsh (Guo & Li, 2022) 通过优化每个类别的伪标签数量,从预定义阈值中获得自适应阈值,以应对不平衡的半监督学习。总的来说,这些方法可能无法或不足以根据模型的学习进展调整阈值,从而阻碍了训练过程,特别是在标记数据过于稀少,无法提供充分监督的情况下。
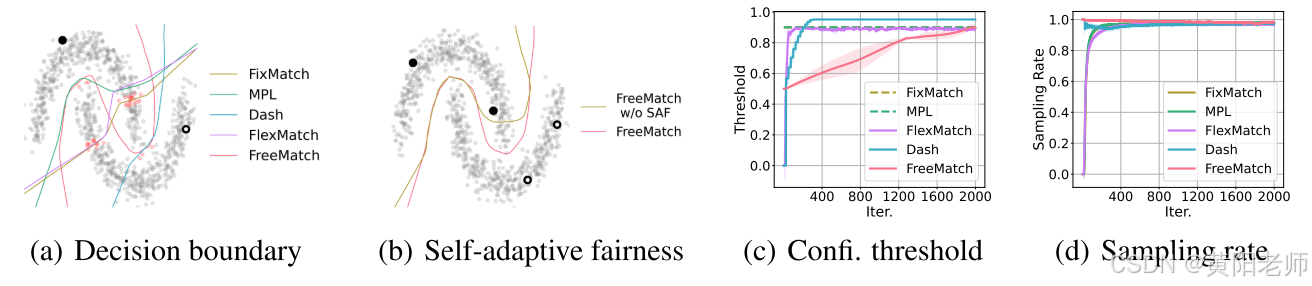
图1:演示FreeMatch如何在“两个月”数据集上工作。(a)FreeMatch和其他SSL方法的决策边界。(b)每类两个标记样本的自适应公平性(SAF)的决策边界改进。©类平均置信阈值。(d)训练期间FreeMatch的Classaware采样率。实验详情见附录A。
例如,如图1(a)所示,在“two-moon”数据集上,每个类别只有一个标记样本时,先前方法获得的决策边界未能满足低密度假设。因此,两个问题自然产生:1)是否有必要基于模型的学习状态来确定阈值?2)如何自适应地调整阈值以获得最佳训练效率?
在本文中,我们首先通过一个激励示例展示了不同数据集和类别应基于模型的学习状态来确定它们的全局(数据集特定)和局部(类别特定)阈值。直观地,我们在训练早期阶段需要一个较低的全局阈值,以利用更多未标记数据并加速收敛。当预测置信度增加时,需要一个更高的全局阈值来过滤错误的伪标签,以减轻确认偏差(Arazo et al., 2020)。此外,每个类别的局部阈值应根据模型对其预测的置信度来定义。图1(a)中的“two-moon”示例显示,当根据模型的学习状态调整阈值时,决策边界更为合理。
接下来,我们提出了FreeMatch,根据每个类别的学习状态以自适应方式调整阈值(Guo et al., 2017)。具体而言,FreeMatch 使用自适应阈值调整(SAT)技术,通过未标记数据置信度的指数移动平均(EMA)来估算全局(数据集特定)和局部阈值(类别特定)。为了更有效地处理极少监督的场景(Sohn et al., 2020),我们进一步提出了一个类别公平性目标,鼓励模型在所有类别之间产生公平(即多样化)的预测,如图1(b)所示。FreeMatch的整体训练目标是最大化模型输入与输出之间的互信息(John Bridle, 1991),在未标记数据上产生高置信度且多样化的预测。基准测试结果验证了其有效性。总之,我们的贡献是:
-
通过一个激励示例,我们讨论了为什么阈值应反映模型的学习状态,并为设计阈值调整方案提供了一些直观思路。
-
我们提出了一种新方法——FreeMatch,该方法包含自适应阈值调整(SAT)和自适应类别公平正则化(SAF)。SAT 是一种无需手动设置阈值的阈值调整方案,SAF 则鼓励多样化的预测。
-
大量结果表明,FreeMatch 在各种半监督学习基准测试中表现出卓越的性能,尤其是在标记数量非常有限的情况下(例如,在CIFAR-10数据集上,每类只有1个标记样本的情况下,错误率减少了5.78%)。
2 动机
在本节中,我们介绍了一个二分类示例,以激发我们对阈值调整方案的讨论。尽管这个示例简化了实际的模型和训练过程,但分析产生了一些有趣的启示,并为如何设置阈值提供了见解。
我们旨在展示自适应性和在SSL(半监督学习)中使用更精细的置信度阈值的重要性。受(Yang & Xu, 2020)的启发,我们考虑一个二分类问题,其中真实分布是两个高斯分布的均匀混合(即标签Y为正类(+1)或负类(-1)的概率相等)。输入X具有以下条件分布:
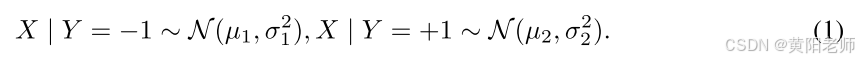

接下来,我们推导以下定理来展示自适应阈值的必要性:
定理 2.1 对于上述提到的二分类问题,伪标签 (Y_p) 的概率分布如下:
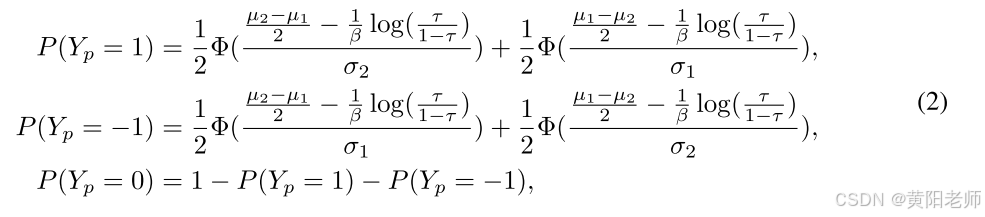

在附录B中提供了定理2.1的证明。定理2.1有以下几项含义或解释:

定理2.1的直观解释是,在训练初期,(\tau) 应该较低,以鼓励产生多样的伪标签&
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











