







一、为什么需要Transformer?先看传统模型的痛点
1. 传统模型:RNN与CNN的短板
-
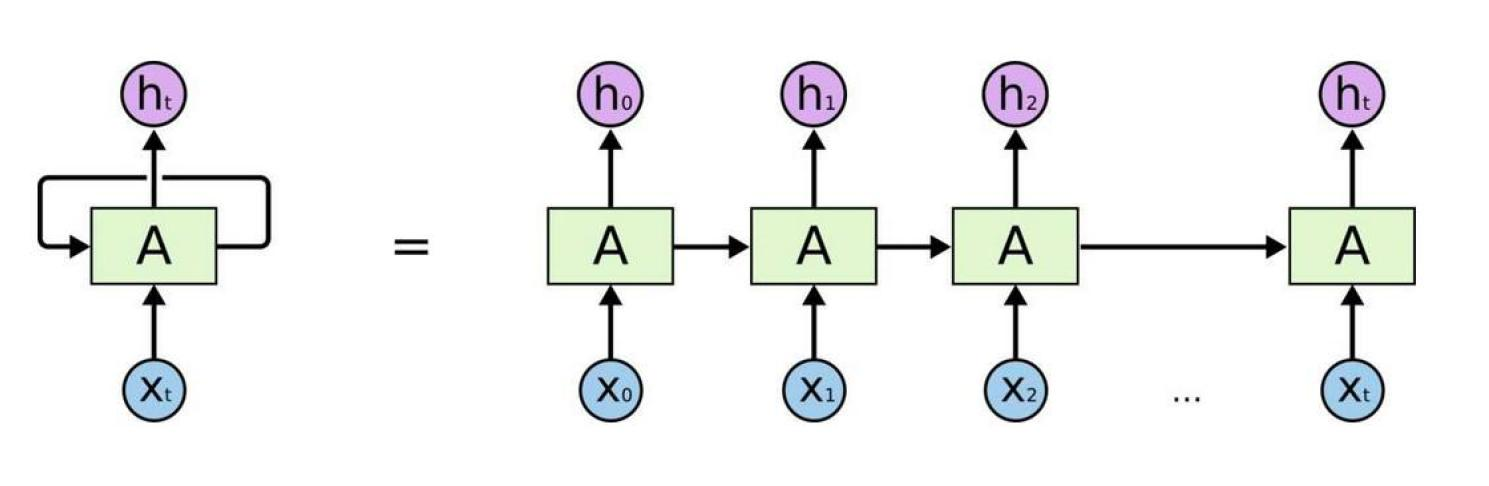
RNN(循环神经网络):逐个处理单词,像流水线作业。
- 问题:速度慢(无法并行),且长距离词语关系容易丢失(“梯度消失”)。
- 例子:句子“The cat, which ate the fish, was happy.”中,RNN可能无法关联“cat”和“was”。
-
CNN(卷积神经网络):用滑动窗口提取局部特征。
- 问题:窗口大小固定,难以捕捉长距离依赖。
2. Transformer的革新
- 并行处理整个句子:所有词同时计算,速度快。
- 自注意力机制:直接建模任意两个词的关系,无论距离多远。
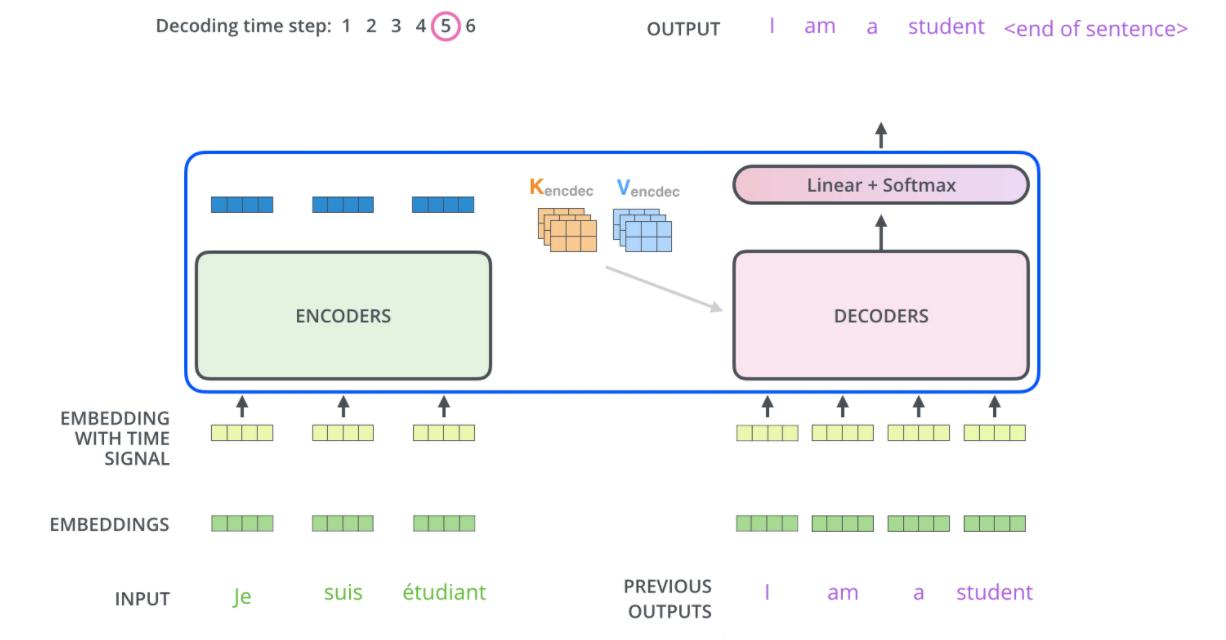
二、Transformer的骨架:编码器-解码器架构
1. 整体结构图
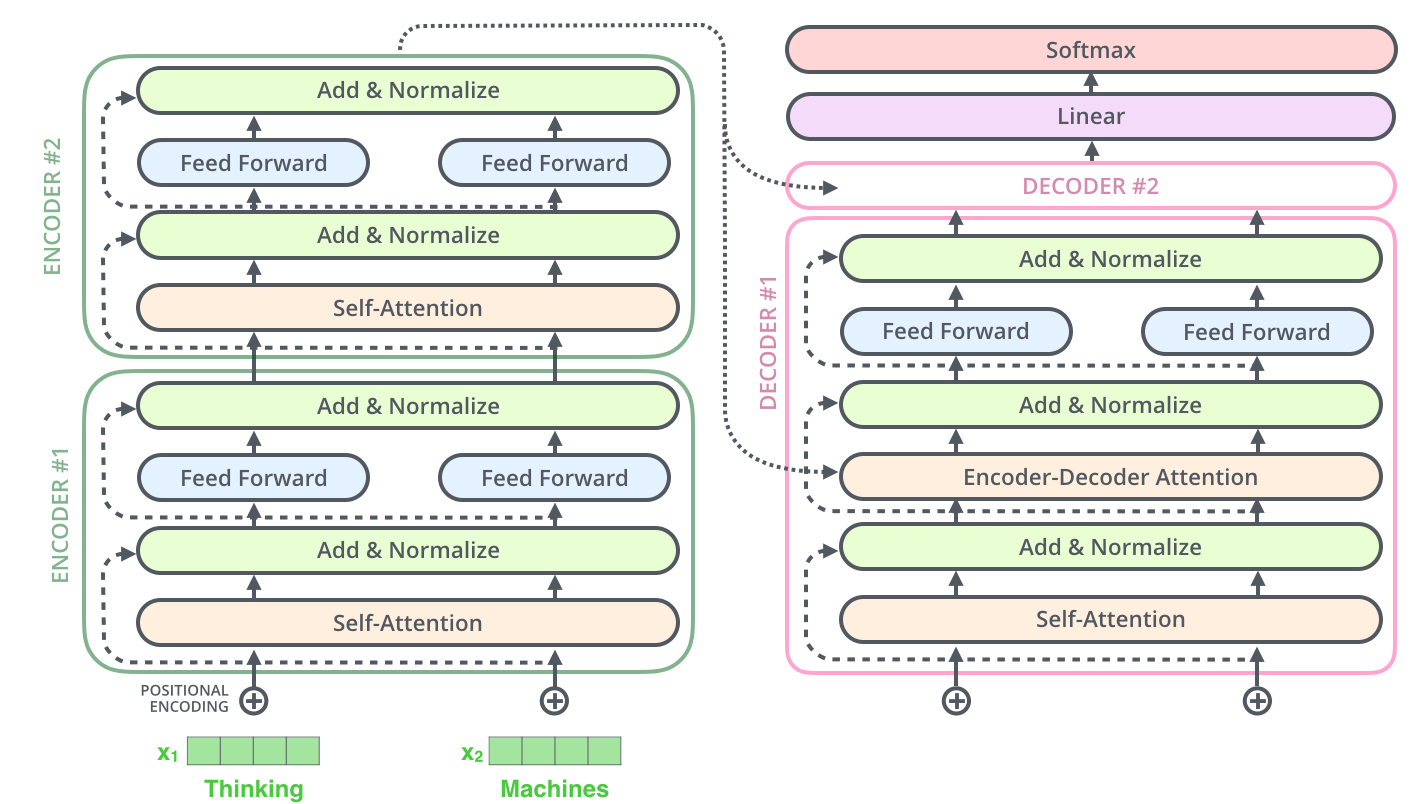
- 编码器(Encoder):理解输入内容(如一句英文)。
- 解码器(Decoder):生成输出内容(如对应的中文翻译)。
- 核心模块:自注意力(Self-Attention)和前馈神经网络(FFN)。
三、从输入开始:词如何变成向量?
1. 词嵌入(Word Embedding)
- 目标:将单词转换为计算机能理解的数值(向量)。
- 例子:
- “猫” → [0.2, -0.5, 1.3, ...](一个高维向量)。
- 语义相近的词(如“猫”和“狗”)向量距离较近。
2. 位置编码(Positional Encoding)
- 问题:Transformer没有RNN的时序信息,需告诉模型词的位置。
- 解决方案:为每个位置生成独特的编码向量,加到词嵌入上。
- 公式:用正弦和余弦函数生成位置编码。
- 直观理解:给每个词打上“位置标签”,比如第一个词标记为1,第二个为2,依此类推。
四、核心机制:自注意力(Self-Attention)
1. 什么是注意力?
- 类比:读一句话时,大脑会重点关注某些词。
- 例如:“我吃了披萨,它很美味。”中,“它”指向“披萨”。
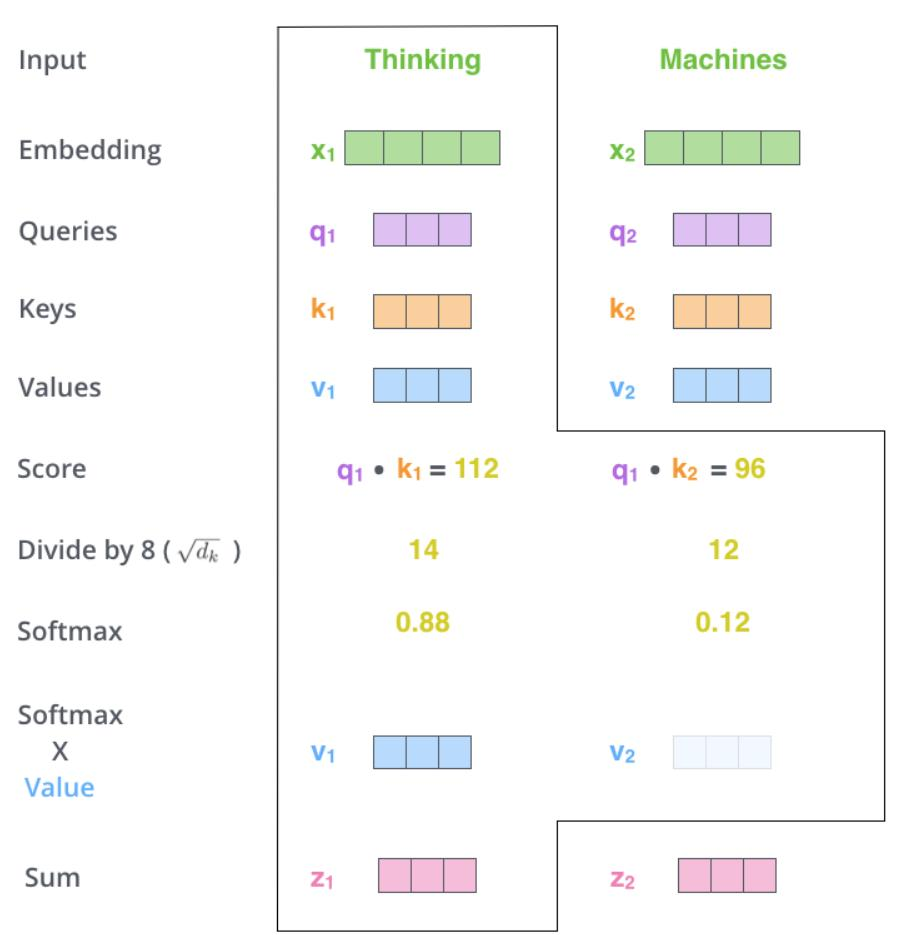
2. 自注意力如何工作?
-
步骤拆解:
-
生成Q, K, V矩阵:每个词通过线性变换得到三个向量:
- Query(查询):当前词想“问”的问题。
- Key(键):其他词提供的“答案线索”。
- Value(值):实际传递的信息。
-
计算注意力分数:
- Query与Key点积:衡量两个词的相关性。
- 缩放:除以向量维度的平方根(防止数值过大)。
- Softmax归一化:将分数转化为概率分布(权重)。
-
加权求和Value:根据权重聚合所有词的信息。
-
-
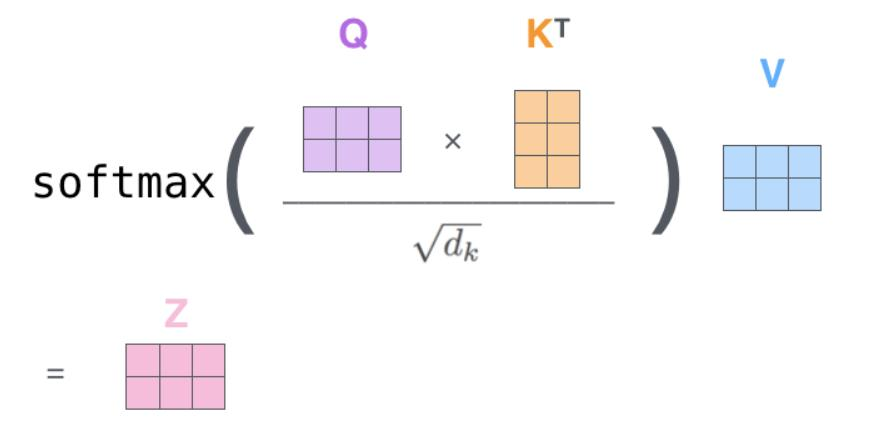
公式:
3. 自注意力的直观例子
- 句子:“The animal didn't cross the street because it was too tired.”
- 模型如何关联“it”和“animal”?
- “it”的Query与“animal”的Key匹配度高 → 权重高 → 聚合“animal”的Value。
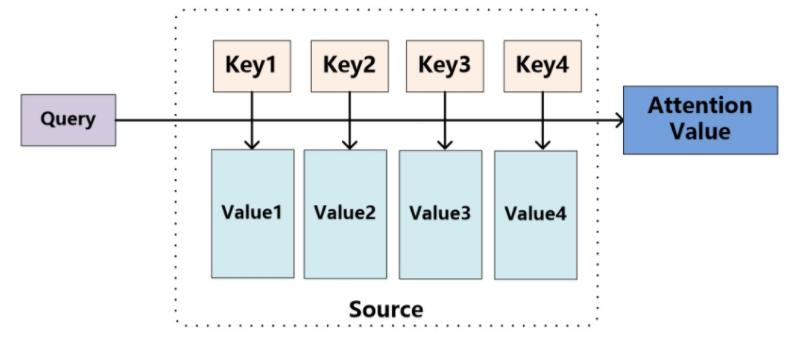
五、多头注意力(Multi-Head Attention)
1. 为什么需要多头?
- 单一注意力头的局限:可能只关注一种类型的关系(如语法)。
- 多头并行的优势:捕捉多种关系(如语法、语义、指代)。
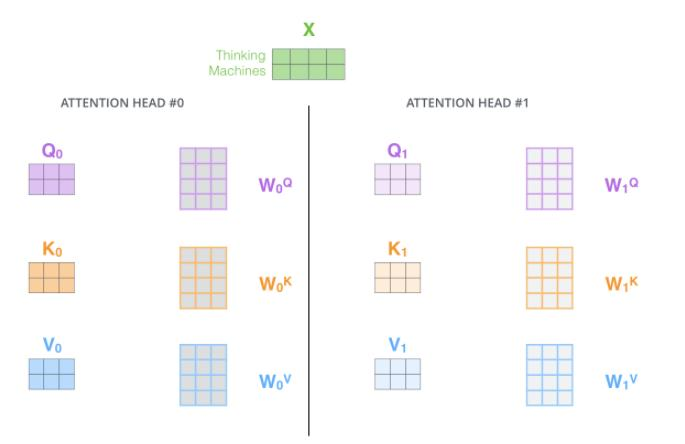
2. 如何实现?
-
步骤:
- 将Q、K、V切分为多个头(例如8头)。
- 每个头独立计算注意力。
- 合并所有头的输出,通过线性变换得到最终结果。
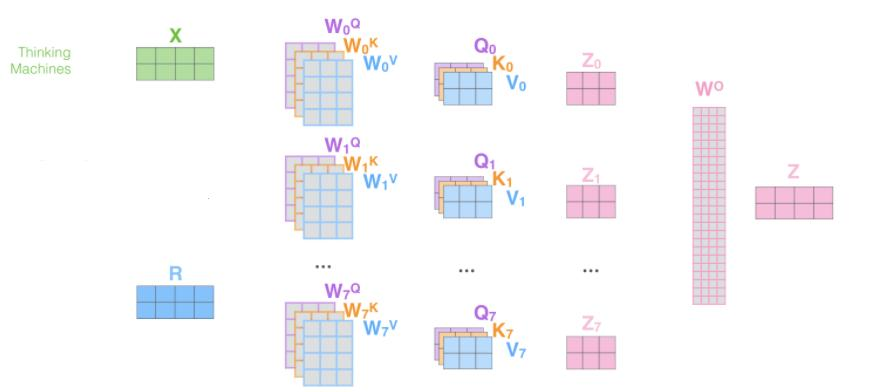
-
公式:
3. 多头注意力的直观理解
- 类比:多人从不同角度分析同一句话,再综合意见。
- 头1:关注主谓一致(“cat”是单数,“was”正确)。
- 头2:关注指代关系(“it”指代“animal”)。
六、前馈神经网络(FFN)
1. 作用:对自注意力的输出进行非线性变换,增强模型表达能力。
2. 结构:两层全连接层 + 激活函数(如ReLU)。
- 公式:
3. 直观理解:将注意力提取的“粗信息”加工为“细信息”。
七、残差连接(Residual Connection)与层归一化(Layer Normalization)
1. 残差连接:将输入直接加到输出上(防止深层网络梯度消失)。
- 公式:
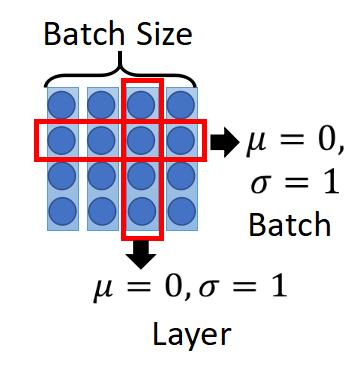
2. 层归一化:对每层的输出做标准化(均值为0,方差为1),加速训练。
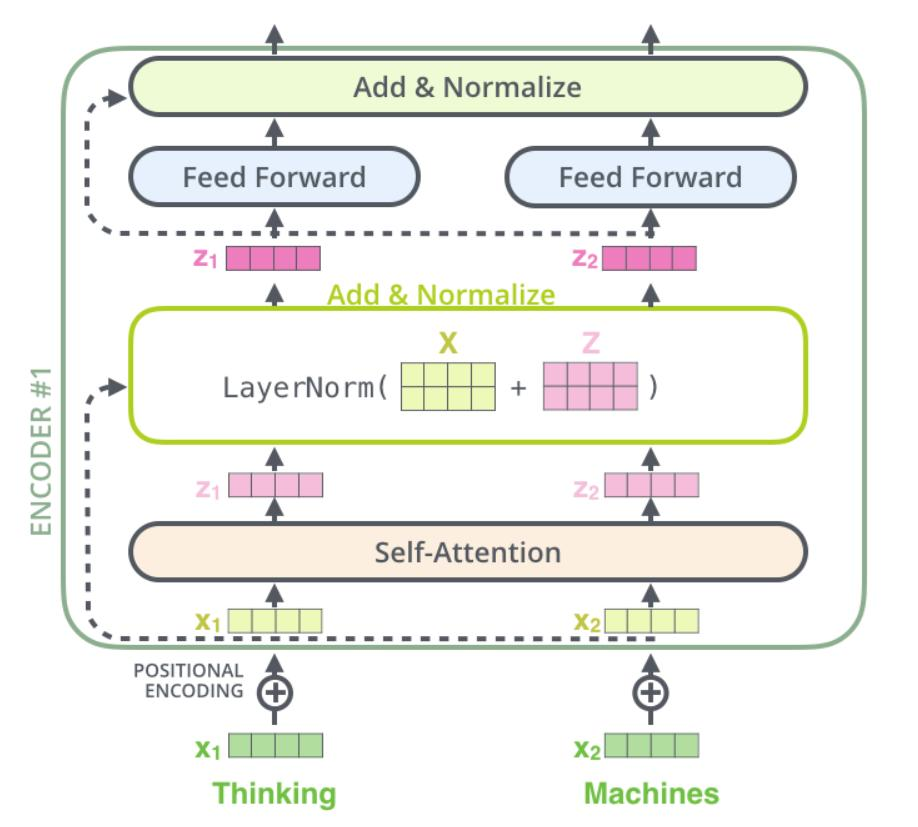
3. 直观理解:
- 残差连接:像“学习残差”而不是完整映射,让模型更容易优化。
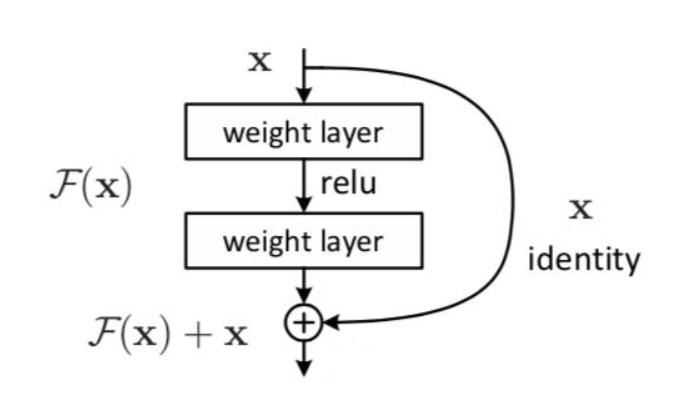
- 层归一化:确保每层的数据分布稳定,避免数值爆炸。
八、训练Transformer:预训练与微调
1. 预训练(Pre-training):
- 目标:在大规模文本上学习通用语言表示。
- 方法:
- 掩码语言模型(MLM):随机遮盖部分词,让模型预测(如BERT)。
- 自回归模型:根据上文预测下一个词(如GPT)。
2. 微调(Fine-tuning):
- 目标:在特定任务(如翻译、分类)上优化模型。
- 方法:在预训练模型后接任务特定层,用少量数据训练。
九、Transformer的局限与优化
1. 计算复杂度高
- 问题:注意力计算随序列长度平方增长(O(n²))。
- 解决方案:
- 稀疏注意力:只计算部分词对的关系(如Longformer)。
- 分块处理:将长文本分为块处理(如Reformer)。
2. 需要大量数据
- 问题:训练Transformer需海量文本(如GPT-3用了45TB数据)。
- 解决方案:
- 知识蒸馏:用大模型训练小模型(如DistilBERT)。
十、总结:Transformer如何改变AI?
1. 核心贡献:
- 并行计算:大幅提升训练速度。
- 全局依赖建模:任意距离词语直接关联。
2. 影响:
- NLP革命:BERT、GPT、T5等模型横扫各类任务。
- 跨界应用:Vision Transformer(ViT)在图像识别中超越CNN。
3. 未来方向:
- 更高效的注意力机制:降低计算成本。
- 多模态融合:同时处理文本、图像、语音(如CLIP、DALL-E)。
附:学习路线图
- 理解词嵌入和位置编码 → 2. 掌握自注意力计算 → 3. 拆解多头注意力 → 4. 研究残差与归一化 → 5. 动手实现小规模Transformer。

















 9万+
9万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









