






GLTF数据格式规范
GLTF文件格式
glTF 导出格式有两种后缀格式可供选择:.gltf 和 .glb:
.gltf 文件导出时一般会输出两种文件类型,一是 .bin 文件,以二进制流的方式存储顶点坐标、顶点法线坐标和贴图纹理坐标、贴图信息等模型基本数据信息;二是 .gltf 文件,本质是 json 文件,记录对bin文件中模型顶点基本数据的索引、材质索引等信息,方便编辑,可读性较好;
.glb 文件格式只导出一个 .glb 文件,将所有数据都输出为二进制流,通常来说会更小一点,若不关心模型内的具体数据可直接选择此类型。
GLTF文件内容解析
参考:https://www.jianshu.com/p/905671909b25、https://blog.csdn.net/hometoned/article/details/125187834
解析文件时,我习惯于从scene开始解析,gltf文件本身就是一个场景文件。可以从scene开始一步一步去完成整个文件的解析。
解析“scene”的值,这个值可以没有,也可以有。如果没有时, 表示当前或初始化时,默认的场景索引。如果有值,且值的合理范围应该是0至scenes.size()。如是值不在这个范围或是没有"scene"字段时,可以给出一个默认值。一般默认值为0,即场景数组scenes中的第一个场景。
解析"scenes",通过scene的值,对应于scenes中的索引,scenes数组中是对象即“{}”,每一个对象,表示一个场景的,其中字段有name、nodes。分别表示这个场景的名称和这个场景的根节点的索引。根节点可以是一个,也可以是多个。一般为一个根节点。名称可以有,也可以没有。由此可以看出,scenes字段是必需要有,否则,整个文件中没有场景,显然不合理。
解析"nodes",这个字段中保存了所有场景的所有的节点。通过scenes节点中找到的场景的根节点的索引。在这个数组中通过索引查询节点。再通过查询到的节点对应的索引,再向下查询节点,如此递归,递归时,做深度递归。子节点可以是"children",依然是个节点;可以是"mesh",是个要绘制的网格;可以是"skin",骨骼动画的蒙皮;可以是"camera"相机。
如果是"children",那么就需要再取得这个节点的索引值,继续查询nodes数组。
如果是"mesh",需要去"meshes"中继续查询。
如果是"skin",需要去"skins"中继续查询。
如果"camera",需要去"cameras"中继续查询。
在递归遍历nodes数组时,节点中可能会有"translation"、"rotation"或"scale"中的一个或多个。也可能是"matrix",代表当前节点的姿态。递归的过程也是节点与节点建父子关系的过程。总是由父节点向子节点递归。
需要注意的是当前节点如是为:"mesh"、"skin"或"camera"当前节点中还可以有自己的子节点。所以解析时,需要判断是否有"children"字段。如果有则说明
解析“meshes”,这个字段中包含了构建一个网格所需要的数据"primitives",这是个数组,也就是说,可以有多个图元的信息。即子网格的概念,一个网格中可以有多个子网格。
"primitives"包含的数据有"attributes"顶点属性数据对应的buffer的索引、"indices"顶点的索引数据buffer的索引、"mode"绘模式、"material"材质对应的索引。
"attributes"又包含了"NORMAL"、"POSITION"、"TEXCOORD_0"、"TANGENT"、“JOINTS_0”、“WEIGHTS_0”等数据对应的索引。其对应的数据应该在"accessors"字段中的查询,比如:"POSITION"对应的索引是0,则在accessors[0]里存储相关的数据信息。在这里"POSITION"字段是必需要有的,顶点属性数据中如果没有顶点,那就不可能绘制出网格了。其它的数据,可以没有。
"indices"表示的是索引数据,如果绘制网格用的是顶点,则可以没有这个数据。同样是从"accessors"数据组中取值。同 "attributes"中的属性数据对应的索引,查询的方法一致。
"mode"表示的是绘制方式 ,其数值代表:0 代表GL_POINTS;1代表GL_LINES;2代表GL_LINE_LOOP;3代表GL_LINE_STRIP;4代表GL_TRIANGLES;5代表GL_TRIANGLE_STRIP;6代表GL_TRIANGLE_FAN。
"material"是对应的"materials"数组中的索引。
解析"accessors",这个字段中包含对应于"bufferView"的数组索引、"componentType"数据类型,"byteOffset"数据在buffer中的偏移、"count"数据的个数、"type"数据的组织形式和"max"、"min"数据的最大值和最小值。
bufferView"的数组索引可以在"bufferViews"数组中查询。
"componentType"的数值代表了数据的类型,如:5120表示byte类型;5121表示ubyte类型;5122表示short类型;5123表示ushort类型;5124表示int类型;5125表示uint类型;5126表示float类型;5130表示double类型。
"byteOffset"表示数据的偏移,最终计算真实数据在buffer中的偏移时,还需要再加上buffer中的偏移。没有这个字段时,可以将这个值默认为0。
"type"是字符串,以字符串的形式,表示:SCALAR标量、VEC2、VEC3、VEC4、MAT2、MAT3、MAT4。
解析"bufferViews",这个字段中的"buffer"表示是"buffers"中的索引。"byteLength"数据的字节长度。"byteOffset"数据的字节偏移。"target"对应的数值表示数据在buffer中的组织形式。
在一个buffer中,可以存放多个顶点属性数据,如可以将"NORMAL"、"POSITION"、"TEXCOORD_0"对应的真实数据放在一起保存。数据可以通过"byteOffset"确定数据在buffer中的起始位置;通过"byteLength"来获取数据长度,再通过"componentType"、"type"就能正确的解析出真实的数据了。
解析"buffers"字段,是buffer数组,每个buffer中都存放真实的数据。一般包含"name"、"byteLength"和"uri"字段。其中,"name"和"uri"并不是必需有的。
"byteLength"表示了数据的真实的字节长度。
"uri"字段有三种情况,对应的文件三种形式:
如果是glb文件,则没有这个字段,其数据可以通过之前的偏移,直接从glb的buffer中取出来;
如果是外部文件方式 ,则这个字段是文件路径,一般是.bin的数据文件,其中的数据,可以直接读取使用的;
如果是内嵌式的,则这个字段是经过base64编码后的字符串,解析时需要base64解码才可以使用这个数据。
解析"materials"字段,包含"name"、"emissiveFactor"、"emissiveTexture"、"normalTexture"、"occlusionTexture"和"pbrMetallicRoughness",主要是提供了pbr渲染时,所需要的纹理信息。
其中"emissiveTexture"、"normalTexture"、"occlusionTexture"三个字段中的"index"值和pbrMetallicRoughness"中包含的"baseColorTexture"和"metallicRoughnessTexture"中的"index"值,对应的是"textures"字段数组的索引。
解析"textures"字段,一般包含"name"、"sampler"和"source"。其中"sampler"对应的是"samplers"数组中的索引;"source"对应的是"images"数组中的索引。
解析"samplers"字段,包含"magFilter"、"minFilter"、"wrapS"、"wrapT"字段。
"magFilter"、"minFilter"对应的是纹理的滤波试,其值:
9728表示GL_NEAREST; 9729表示GL_LINEAR;9984表示GL_NEAREST_MIPMAP_NEAREST;9985表示GL_LINEAR_MIPMAP_NEAREST;9986表示GL_NEAREST_MIPMAP_LINEAR;9987表示GL_LINEAR_MIPMAP_LINEAR 。
"wrapS"、"wrapT"对应的是纹理的环绕方式,其值如:
33071表示GL_CLAMP_TO_EDGE;33648表示GL_MIRRORED_REPEAT;10497表示GL_REPEAT。
解析"images"其中包含"mimeType"、"name"、"uri"和"bufferView"。其中"mimeType"给出了图片的格式。 "uri"也是分为三种情况,如果是glb文件,则这个字段为空,可以通过给出的"bufferView"的索引,查询相关的数据并读取。如果是内嵌式文件,则真实的数据,以base64编码的形式写入文件,解析时,需要base64解码来读取真实的内容,其中前前面的部分字节内容为"***;base64,"表示的是这个文件是什么格式的,并以base64进行了编码处理。之后的字段才是真实的图片内容。如果是外部文件格式的,则其内容为图片的路径。
"bufferView"这个字段,也只是glb时,才会有。
解析"cameras"字段,是个数组,可以有多个相机。一般有包含"type"字段,为字符串,其值为"perspective"或是"orthographic",表示这个相机是透视的还是正交的。这个类型不一样,其包含的字段也是不一样的。
perspective时,包含"aspectRatio"、"yfov"、"zfar"、"znear"。
orthographic时,包含"xmag"、"ymag"、"zfar"、"znear"。
解析灯光,灯光并没有字段"light",而是要先找到"KHR_lights_punctual"字段,再从这个对象里找"lights"字段。然后解析出灯光的"name"、"color"和"type"。"type"以字符串的形式,表示当前的灯光是什么类型的,其值为"point"、"DOT"和"direction"。"color"的值是个数组,所以颜色的通道数,不一定是3或4。
概述
模型加载顺序为,先加载gltf文件,然后解析依次读取scenes、nodes、meshes、accessors、bufferViews、buffers、materials、textures、images。其中每个mesh包括一个bufferViews和一个materials。每一层的递进都有数组下标来确定。
scenes 场景
scenes:[{nodes:0}],
scene:0一般模型只有一个也是默认场景,如果是多个,则根据对应的scene字段确定哪一个是默认场景,参考数据结构部分的数据,每一个scene都包含一个nodes字段,指定了scene的根结点。本例中nodes对应的值为0,代表根节点为nodes字段下对应的第一个元素。
nodes 节点
nodes:[
{
name:"rootModel",
children:[1]
},
{
name:"floor1",
children:[2]
},
{
name:"room1",
mesh:0
}
]nodes用来组装模型层级,第一个节点是父节点,children字段指定它所包含的子节点。
nodes节点分为俩种,一种是有children字段的,最终会渲染成group,一种是有mesh字段的最终渲染为mesh,mesh字段的值为meshes数组的小标。
meshes 网络
meshes:[{
name:"mesh1",
primitives:[{attributes:{POSITION:0,NORMAL:1,TEXCOORD_0:0},indices:0, material:0,mode:4}]}]网格由多个面和材质组成,通过primitives字段指定。
attributes 指定了顶点、顶点法线、uv坐标在accessors数组的对应数据的下标。
POSITION - 顶点
NORMAL - 顶点法线,顶点法线不是必须,导入引擎 时可生成
TEXCOORD_0 - uv坐标
indices 指定了面在accessors数组的对应数据的下标
material 指定了该mesh的材质在materials数组中的下标
accessors 访问器
accessors:[{name:"postions_0", componentType:5126,count:100, bufferView:0, byteOffset:0,type:"VEC3",max:[],min:[]}]访问器是链接bufferView和mesh之间的桥梁,主要作用是对bufferView中数据进行进一步描述
componentType 数据类型浮点或者整形
count 数量总和(顶点总数或者面总数,通过此字段可计算模型的总顶点数、总面数,对于模型性能分析和优化有很大作用
bufferView 对应数据在bufferViews中的下标
bufferViews 缓冲区视图
bufferViews:[
{name:"view0",buffer:0,byteLength: 144, byteOffset: 0, byteStride: 12, target: 34962}
]
buffer 对应的数据在buffers数组中的下标
byteLength 该缓冲区对于的数据长度
byteOffset 在buffer中的起始位置
buffers 缓冲区
buffers:[{name:1,uri:"1.bin"}]
uri 该缓冲区对于的bin文件,bin文件的作用参考第一部分的介绍
从mesh走到bin文件,模型的骨骼已经确定了,顶点、法线、面、都有了,剩下的就是给模型添加材质贴图,这一部分也是从mesh出发,由mesh下的material字段指定对应的材质
materials 材质
materials:[
{name:"m0", pbrMetallicRoughness:{baseColorTexture:{index:0}}}
]baseColorTexture 对应textures数组下标
textures 纹理
textures:[{name:"t0",source:0}],
source 对应images数组下标
images 贴图
images:[{name:"img0",uri:"1.jpg"]总的流程如下图
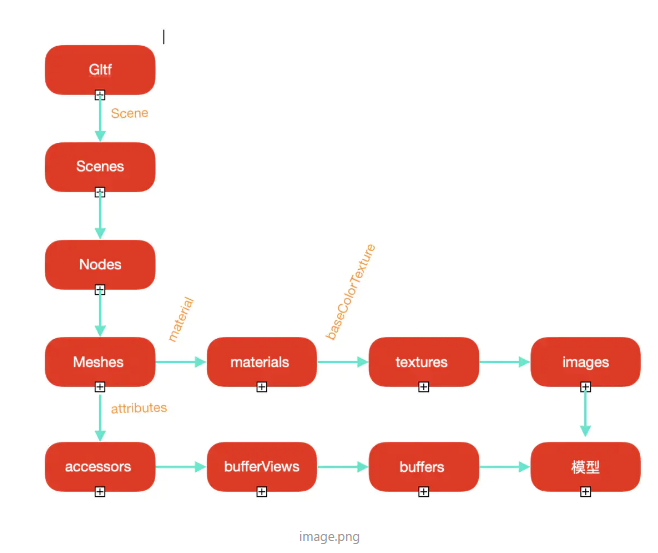
压缩优化
npm install gltf-pipeline作者:WebGiser
链接:https://www.jianshu.com/p/e134a2599cb7
来源:简书
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。

















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









