






视频格式
- -,视频产生到文件格式封装
- , 镜头->CCD->编码->记录。

1. CCD,编码部分
拍摄的画面转变为RGB像素->YUV像素->色彩采样(YUV4:4:4,YUV4:2:2, YUV4:2:0,YUV4:1:1等)->码流->压缩->记录(封装的文件格式)
CCD扫描方式: 逐行,隔行 。隔行带宽少,但不适应于运动画面。
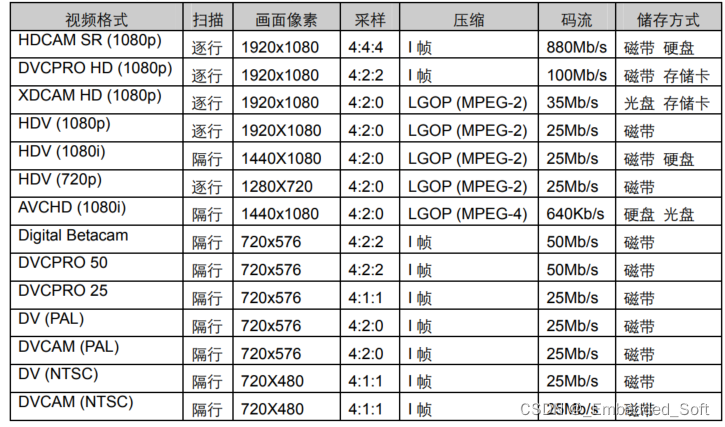
**下图为常见视频格式:**
**编码部分包括**:编码(MPEG, H.264, H.265):色彩采样,码流,压缩.
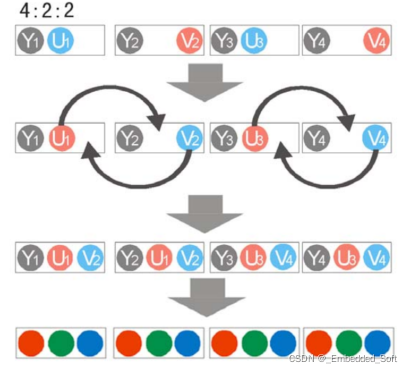
如下图为色彩采样YUV4:2:2:

码流 (码率):码率的分类:CBR:静态码率(Constant Bit Rate),恒定的码率可以保证视频在播放时,不会有卡顿缓冲等现象。VBR:可变码率(Variable Bit Rate),动态码率的好处是,在相同画质的前提下,可以缩小文件体积,码率越大,视频质量就越高,但文件体积也就越大。码率越小,文件体积变小,但视频质量也就越低.
码流计算公式(MB/s):码率 × 时长(秒)÷ 8 ÷ 1024 ÷ 1024
码率的设置:
(1)上传到网络时,应使用5M~10M或更大的码率,因为一般的视频平台都会再次压缩,较高的码率容易保证画质。
(2)传到移动设备时,可以Adobe Media Encoder等软件里的预设,建议再适当提高一点点预设中的码率值。
(3)音频的码率:原理跟视频是一致的,只不过音频的数据量相对少很多,单位通常为kbps(千位每秒)。音频码率一般大于128kbps每秒就不会有多大问题。
参考原文链接:https://blog.csdn.net/qq_41176800/article/details/103932875
压缩分帧内压缩和帧间压缩:
视频压缩分为有损压缩和无损压缩。
I帧压缩(帧内)和LGOP压缩(帧间)的出发点是不一样。I帧压缩是根据每帧的“画面内容”进行压缩,由于每帧独立,无论拍摄的是运动镜头还是固定镜头,对压缩率并没有影响。LGOP压缩是根据“帧与帧之间的关系”进行压缩,如果是静止画面,I帧后面的那些B帧和P帧几乎什么信息都可以不留;如果是运动画面, B帧和P帧只需要保留那些变化的即可。如果用一句话来区分这两种压缩方式,可以说:“I帧压缩是静态压缩,LGOP压缩是动态压缩”


视频封装(记录),其实就是把所有相关信息(视频、音频、字幕、媒体信息等)按照一定的格式打包一个文件。比如,将H.264编码的视频和MP3编码的音频按照MP4的封装标准封装起来,这样我们看到的就是MP4格式的视频文件了。
二,视频播放
用录像机把磁带上的内容放出来;另一个就是把它们导进电脑里进行编辑。
首先把压缩在磁带上的帧信息解压成YUV的帧画面,然后再把YUV转换成RGB,显像管把RGB信息投影在荧光屏上,画面就出来了
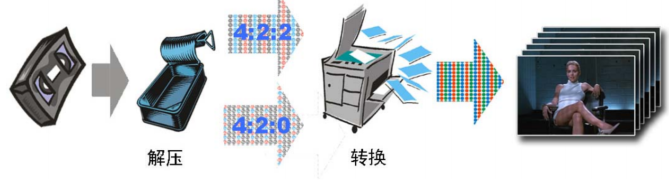
不同的容器格式规定了其中音视频数据的组织方式(也包括其他数据,比如字幕等)。容器中一般会封装有视频和音频,播放视频文件的第一步就是根据视频文件的格式,解析(demux)出其中封装的视频流、音频流以及字幕(如果有的话),解析的数据读到包 (packet)中,每个包里保存的是视频帧(frame)或音频帧,然后分别对视频帧和音频帧调用相应的解码器(decoder)进行解码,比如使用 H.264编码的视频和MP3编码的音频,会相应的调用H.264解码器和MP3解码器,解码之后得到的就是原始的图像(YUV or RGB)和声音(PCM)数据,然后根据同步好的时间将图像显示到屏幕上,将声音输出到声卡,最终就是我们看到的视频。
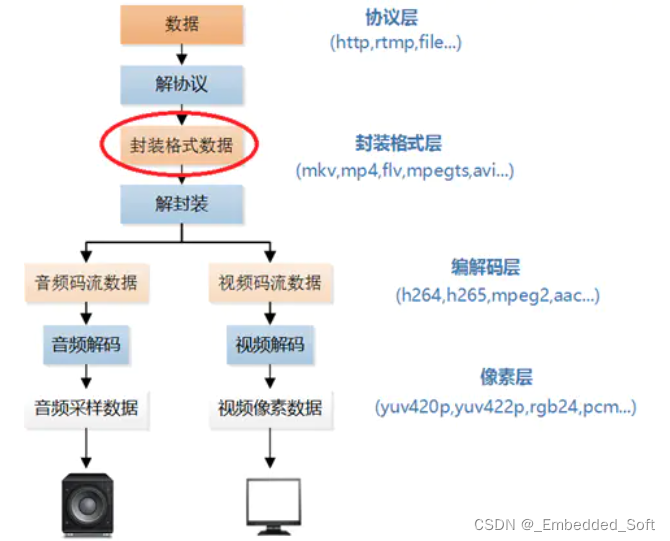
1、解压:I帧解压, LGOP解压
I帧压缩的解压过程与其压缩过程正好相反
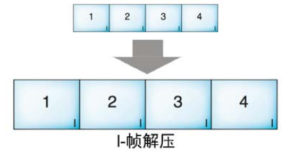
I帧把那些保留好的“没用的”信息传给P帧,然后P帧再把那些信息传给B帧,这样大家你给我一点,我给你一点,那些被扔掉的信息就又回到每个B帧和P帧里,15帧的完整画面就出来了
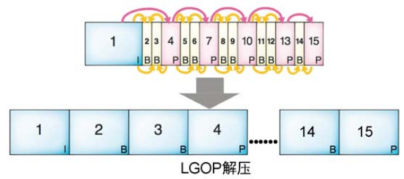
解压后,就得到了YUV的采样画面。但我们还要将“采样YUV”转换成“完整YUV”,再将YUV转换RGB,电视机才能将画面再现出来。然色度采样后的YUV就是色度分量不全的YUV,色度不全的YUV如何能转换成完整的YUV呢?其实道理和压缩解压是类似的,就是给那些扔掉的部分“找补”填回来。下图是4:2:2采样YUV还原的方法,让那些“留住的”色度分量复制自己去填那些“牺牲掉的”同学的空位。
采样
参考: RGB、YUV、YCbCr几种颜色空间的区别.
图解YU12、I420、YV12、NV12、NV21、YUV420P、YUV420SP、YUV422P、YUV444P的区别.
ffmpeg数据结构AVFrame.
RGB、YUV和YCbCr区别:
RGB:RGB(红绿蓝)是依据人眼识别的颜色定义出的空间,可表示大部分颜色。但在科学研究一般不采用RGB颜色空间,因为它的细节难以进行数字化的调整。它将色调,亮度,饱和度三个量放在一起表示,很难分开。它是最通用的面向硬件的彩色模型。该模型用于彩色监视器和一大类彩色视频摄像。
YUV: 在 YUV空间中,每一个颜色有一个亮度信号 Y,和两个色度信号 U 和V。亮度信号是强度的感觉,它和色度信号断开,这样的话强度就可以在不影响颜色的情况下改变.
YCbCr: YCbCr 是在世界数字组织视频标准研制过程中作为ITU - R BT1601 建议的一部分,其实是YUV经过缩放和偏移的翻版。其中Y与YUV 中的Y含义一致, Cb , Cr 同样都指色彩, 只是在表示方法上不同而已。在YUV家族中, YCbCr 是在计算机系统中应用最多的成员,其应用领域很广泛,JPEG、MPEG均采用此格式。一般人们所讲的YUV大多是指YCbCr
Y = (0.257 * R) + (0.504 * G) + (0.098 * B) + 16
Cr = V = (0.439 * R) - (0.368 * G) - (0.071 * B) + 128
Cb = U = -(0.148 * R) - (0.291 * G) + (0.439 * B) + 128
B = 1.164(Y - 16) + 2.018(U - 128)
G = 1.164(Y - 16) - 0.813(V - 128) - 0.391(U - 128)
R = 1.164(Y - 16) + 1.596(V - 128)
YUV 4:4:4采样,每一个Y对应一组UV分量,一个YUV占8+8+8 = 24bits 3个字节。
YUV 4:2:2采样,每两个Y共用一组UV分量,一个YUV占8+4+4 = 16bits 2个字节。
YUV 4:2:0采样,每四个Y共用一组UV分量,一个YUV占8+2+2 = 12bits 1.5个字节。
YUV 4:4:4
YUV三个信道的抽样率相同,因此在生成的图像里,每个象素的三个分量信息完整(每个分量通常8比特),经过8比特量化之后,未经压缩的每个像素占用3个字节。
下面的四个像素为: [Y0 U0 V0] [Y1 U1 V1] [Y2 U2 V2] [Y3 U3V3]
存放的码流为: Y0 U0 V0 Y1 U1 V1 Y2 U2 V2 Y3 U3 V3
YUV 4:2:2
每个色差信道的抽样率是亮度信道的一半,所以水平方向的色度抽样率只是4:4:4的一半。对非压缩的8比特量化的图像来说,每个由两个水平方向相邻的像素组成的宏像素需要占用4字节内存(例如下面映射出的前两个像素点只需要Y0、Y1、U0、V1四个字节)。
下面的四个像素为: [Y0 U0 V0] [Y1 U1 V1] [Y2 U2 V2] [Y3 U3V3]
存放的码流为: Y0 U0 Y1 V1 Y2 U2 Y3 V3
映射出像素点为:[Y0 U0 V1] [Y1 U0 V1] [Y2 U2 V3] [Y3 U2V3]
YUV 4:1:1
4:1:1的色度抽样,是在水平方向上对色度进行4:1抽样。对于低端用户和消费类产品这仍然是可以接受的。对非压缩的8比特量化的视频来说,每个由4个水平方向相邻的像素组成的宏像素需要占用6字节内存
下面的四个像素为: [Y0 U0 V0] [Y1 U1 V1] [Y2 U2 V2] [Y3 U3V3]
存放的码流为: Y0 U0 Y1 Y2 V2 Y3
映射出像素点为:[Y0 U0 V2] [Y1 U0 V2] [Y2 U0 V2] [Y3 U0V2]
YUV4:2:0
4:2:0并不意味着只有Y,Cb而没有Cr分量。它指得是对每行扫描线来说,只有一种色度分量以2:1的抽样率存储。相邻的扫描行存储不同的色度分量,也就是说,如果一行是4:2:0的话,下一行就是4:0:2,再下一行是4:2:0…以此类推。对每个色度分量来说,水平方向和竖直方向的抽样率都是2:1,所以可以说色度的抽样率是4:1。对非压缩的8比特量化的视频来说,每个由2x2个2行2列相邻的像素组成的宏像素需要占用6字节内存。
下面八个像素为:
[Y0 U0 V0][Y1 U1 V1] [Y2 U2 V2] [Y3 U3 V3]
[Y5 U5 V5] [Y6 U6 V6] [Y7U7 V7] [Y8 U8 V8]
存放的码流为:
Y0 U0 Y1 Y2U2 Y3
Y5 V5 Y6 Y7 V7 Y8
映射出的像素点为:
[Y0 U0 V5][Y1 U0 V5] [Y2 U2 V7] [Y3 U2 V7]
[Y5 U0 V5][Y6 U0 V5] [Y7U2 V7] [Y8 U2 V7]
YUV420p数据格式:
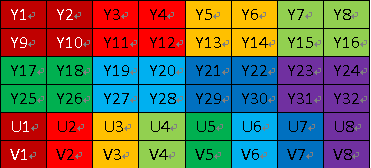
YUV420 planar数据, 以720×488大小图象YUV420 planar为例,
其存储格式是: 共大小为(720×480×3>>1)字节,
分为三个部分:Y,U和V
Y分量: (720×480)个字节
U(Cb)分量:(720×480>>2)个字节
V(Cr)分量:(720×480>>2)个字节
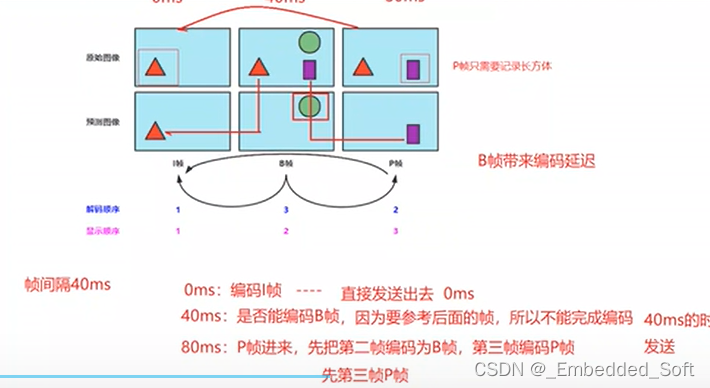
I、B、P帧
时间基
不同的场景下取到的数据帧的time是相对哪个时间体系的。
场景1:编码器产生的帧,直接存入某个容器的AVStream中,那么此时packet的Time要从AVCodecContext的time转换成目标AVStream的time
场景2:从一种容器中demux出来的源AVStream的frame,存入另一个容器中某个目的AVStream。
此时的时间刻度应该从源AVStream的time,转换成目的AVStream timebase下的时间。
demux出来的帧的time:是相对于源AVStream的timebase
编码器出来的帧的time:是相对于源AVCodecContext的timebase
mux存入文件等容器的time:是相对于目的AVStream的timebase
这里的time指pts
AVCodecContext中的AVRational根据帧率来设定,如25帧,那么num = 1,den=25
AVStream中的time_base一般根据其采样频率设定,如(1,90000)
在刻度为1/25的体系下的time=5,转换成在刻度为1/90000体系下的时间time为(51/25)/(1/90000) = 36005=18000
那pts是什么呢?
就是从开始录制瞬间到这个packet录制的所经历的tick的总和。
到这里大家应该明白怎么计算播放时长了吧,有刻度,有刻度总数:
time = packet->pts * (num/den);

















 2131
2131

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









