







李宏毅深度强化学习(国语)课程(2018)_哔哩哔哩_bilibili
on-policy:要learn的agent和环境互动的agent是同一个,即agent一边跟环境互动,一边学习;
off-policy:要learn的agent和环境互动的agent是同一个,即在旁边看别人玩。

on-policy→off-policy的目的是为提高数据利用效率。

on-policy→off-policy的公式推导:实现从p分布的policy中sample data→q分布的policy中sample data。

实际操作中,p分布和q分布还是不能差太多,否则会导致一些问题出现。这是因为期望相等,方差Variance不一定相等,公式推导如下。

如果sample的次数不够多,就会出现问题,如下图。
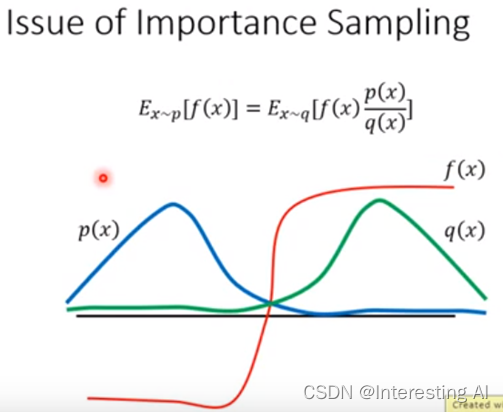
由于跟环境做互动的是θ',而不是θ,因此,θ' sample出来的数据和θ没有关系。进而,可以实现θ'跟环境做互动产生一大堆数据以后,θ可以update很多次。Train到一定程度以后,θ'重新跟环境做互动。

是Accumulated Reward 减去 bias,用来估测动作的相对好坏,如果正就增加动作几率,如果负,就减少几率。

这里有个假设,和
分布是差不多的,可以抵消,另外的原因是因为算不出来的。

前面的假设是与
不能差太多,否则结果会不准确。那么,如何避免差太多,就是PPO要做的事情,就是在training的时候,多加了一个constraint。这个constraint就是θ和θ'这两个model 输出的action的KL散度,KL Divergence。TRPO是PPO的前身,constraint的位置不同是两者的区别。

注意:PPO比TRPO在实操上容易多,效果差不多。KL Divergence并不是θ和θ'参数的距离,是行为上的距离,即给同一个state的时候,action几率分布之间的差距。
PPO算法流程:

PPO 2 公式复杂,但是操作起来简单。

式中, clip函数的含义

式中,min函数的含义
















 1770
1770











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











