







JVM认识
1.认识
1.1 一张图说明java 文件的加载的整体过程:
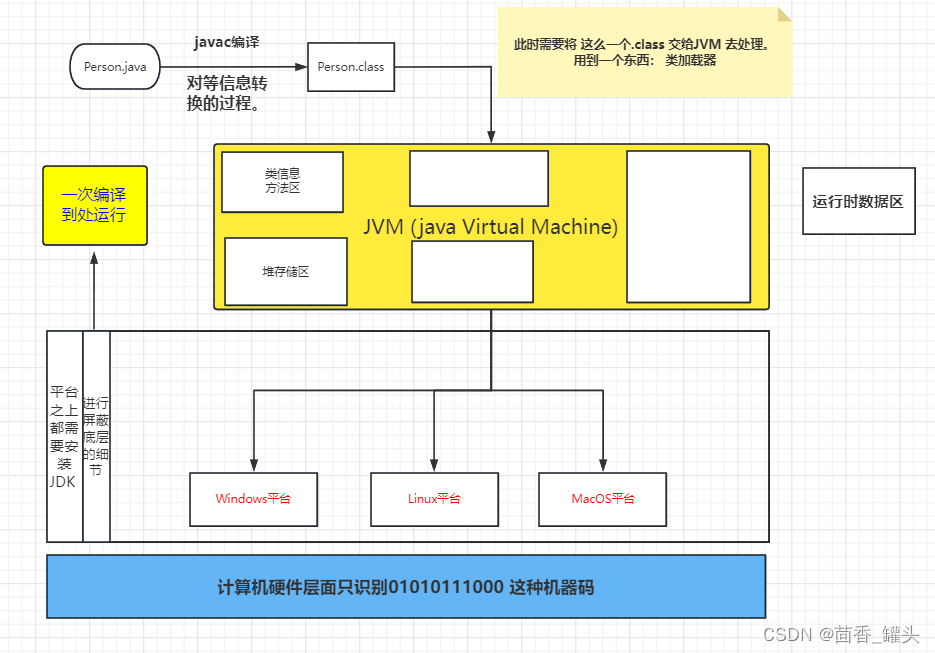
从图中可以看出, 在不同平台都需要安装JDK, 这个JDK就是 java 文件运行的基础。包括:JVM(java运行虚拟机、JRE java运行时所依赖的文件、和 java Tools 工具 以及java language )。
注意:
JDK = JRE + 类库;
JRK =JVM + 类库;
JVM : java虚拟机。
有JVM就可以解释执行字节码文件(.class).
JVM解释执行这些字节码文件的时候需要调用类库,如果没有这些类库JVM就不能正确的执行字节码文件,JVM+类库=JRE,
有了JRE就可以正确的执行java程序了,但是光有JRE不能开发Java程序,所以JRE+开发工具=JDK,有了JDK,就可同时开发,执行JRE.
JDK、JRE、JVM 之间的关系_小张讨厌生姜的博客-CSDN博客_jdk和jre和jvm的关系
jDK 文件的一些说明:
java:这个可执行程序其实就是JVM,运行Java程序,就是启动JVM,然后让JVM执行指定的编译后的代码;
javac:这是Java的编译器,它用于把Java源码文件(以.java后缀结尾)编译为Java字节码文件(以.class后缀结尾);
jar:用于把一组.class文件打包成一个.jar文件,便于发布;
javadoc:用于从Java源码中自动提取注释并生成文档;
jdb:Java调试器,用于开发阶段的运行调试。

1.2 类加载机制的引用
类的加载过程:
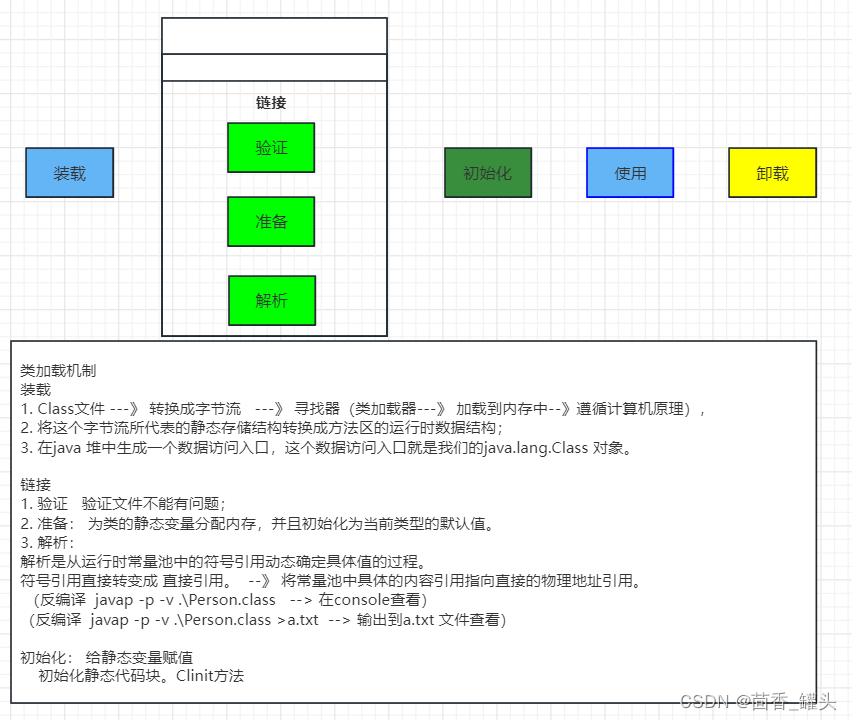
1.3 么是类加载器?
ClassLoader:
1.4 类加载机制 到 GC优化的过渡
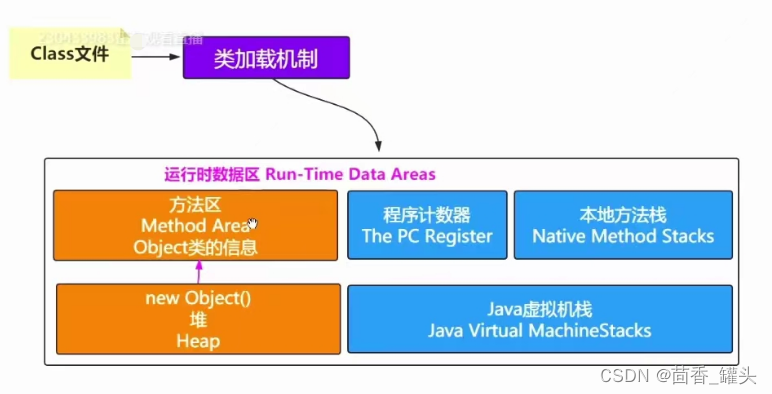

说明:
- 程序计数器、本地方法栈、Java 虚拟机栈 都是线程私有的的,随着线程生命周期消亡而消亡。 基本不需要我们进行GC优化。
- 垃圾回收最重要的是 方法区和 堆内存区域两个部分。
- 方法区 ? 持久代,保存时间比较长,GC 回收关心不是很大。
- 明确GC回收的是 堆中对没有用的垃圾进行回收。如果一个对象没有任何与之相关联的引用, 那么他对于GC来说就是垃圾。
- 垃圾回收所使用的的算法有:
- 引用计数法: 记录对象被引用的次数: 0 摒弃了; 原因: 产生对象之间的循环引用。
- 可达性分析算法: 根可达算法: GC Root 生成一条引用链,在引用链上的所有对象, 称之为存活对象。 GC Root 本质是什么? 本质是一组活跃的引用。
- GC Roots 对象包括:栈帧的局部变量表中的元素、方法区域中的类静态属性引用的对象、方法区域中常量引用的对象、本地方法栈中的JNI。
1.5 什么时候会进行垃圾回收?
搜索完垃圾之后的下一步就是回收垃圾。
-
内存不够用的时候。丢垃圾过程:1. 找到垃圾;2. 标记,(标记清除算法)【标记清除算法:递归遍历所有的对象: 先找到垃圾,进行标记,然后再清除。会产生很多空间碎片,内存浪费,效率慢】 3. 有空的时候,丢掉。 【标记清除算法: 需要维护一个额外的列表, 这个列表里面存放的是内存的空闲地址】
出现了一个问题:
如果是多线程业务项目, 出现了 该回收的没回收,不该回收的被回收了。 业务线程与垃圾收集线程并行, 改为串行 。 那就出现了一个词:
STW: stop the world: 停掉业务线, 运行完GC线 ,然后再切换回来业务线。 -
收垃圾原则: 高效(越简单越清晰的逻辑跑起来越高效)、健壮。
-
因为标记清除算法的缺点, 标记复制算法出现:
-
将回收的地址,将地址引用回收回来。 内存多利用了一半。(自适用算法)
-
标记整理算法(标记、清理、整理)也叫 标记压缩算法。
整理方式很多种: 随机整理、线性整理、滑动整理··· -
引出分代收集(Generational Collection)
分代收集是根据对象的存活时间把内存分为新生代和老年代,根据各个代对象的存活特点,每个代采用不同的垃圾回收算法。新生代采用复制算法,老年代采用标记—整理算法。垃圾算法的实现涉及大量的程序细节,而且不同的虚拟机平台实现的方法也各不相同。
分代收集: 老年代 ; 用标记整理算法 / 标记清除算法 效率斟酌···
落地垃圾收集器之上。

Serial: 单线程回收, STW , 出现业务系统线程与GC垃圾回收线程的切换, 出现停顿时间卡顿现象。
升级:
ParNew: 多线程垃圾回收
不满足:
多线程垃圾收集器: STW 降低停顿时间; 问题: 能不能单位时间内干的事儿更多,控制我们的吞吐量。
Parallel Scavenge 新生代: 复制算法 吞吐量 【业务线程处理时间/(垃圾回收线程处理时间 +业务线程处理时间 )】
Parallel Od 老年代 标记整理算法、 多线程的。
吞吐量 停顿时间 现在互联网公司项目 一般都是更加关注 停顿时间
在保证最大吞吐量的情况下, 尽可能降低停顿时间 如果 能用1% 吞吐量去换取 30% 停顿时间, 那么就干。 降吞吐 不能低于95% 。
不满足:
降低停顿时间能不能为 0 , 如果不能, 那么能不能降低点。
可以。 但是 在Hotspot 系列中不行。 但是 微软的C4 可以。
STW怎么来的? 垃圾收集的时候, 不让业务线跑。
CMS : 标记清除算法
- 初始标记: 找到所有的GC root 以及与之相对应的第一个对象 , 不耗时的。 所以我STW .
- 并发标记: 找出引用链上剩下的所有对象并标记,记录哪些对象发生依赖关系的变化, 耗时, 所以 并发执行;
- 重新标记: 补救措施, 将依赖关系发生变化的对象重新进行标记,不耗时的。 我也STW .
- 并发清除: 并发处理垃圾, 耗时。
CMS 也是产生内存碎片, 还是停顿时间太长了,
G1 :
第一个: 停顿时间比CMS 短, 短到你想多短就多短。
第二个: 我可以避免掉空间碎片, (某种程度上避免)。
内存重新划分:
2024个region 的区域;
每个区域都只是逻辑分代。
Garbage First 垃圾优先原则。
并发类垃圾收集器特点: 强制进行并发失败模式。
1.6 System.gc() 能调用使用么?
系统内置的调用操作。 一般不建议使用,通知JVM 触发 Full gc; 仅仅只是通知, 不一定会触发使用。想要触发,还要睡个500ms.(业务大的话, 会停顿10几秒······)
淘宝早期 在凌晨3:00 - 4:00 定时任务去触发System.gc(); 定时执行, 业务不会受影响。
1.7 面试怎么聊性能调优这个东西?
- 优先保证内存 不OOM(Out of Memory) , 上线前的内存配置是否符合要求?计算
1000*1K = 1M * 60s = 60M *20 = 1200M , 新生代是否符合够1200M。 总共:2400M - 压测的吞吐量 >95% , 用GC view查看。
- Full GC 和Young GC 的频率 , 是否需要更换GC收集器。
- 可靠性观测 内存泄漏(等内存不够了, 仪表盘 再去检查) 对比分析
- 垃圾收集器的参数是否需要变更? 比如:G1 更改标记线程;或者说Mixed mode
- CPU的使用率情况: 看是否上升。
2. JVM 如何进行调优
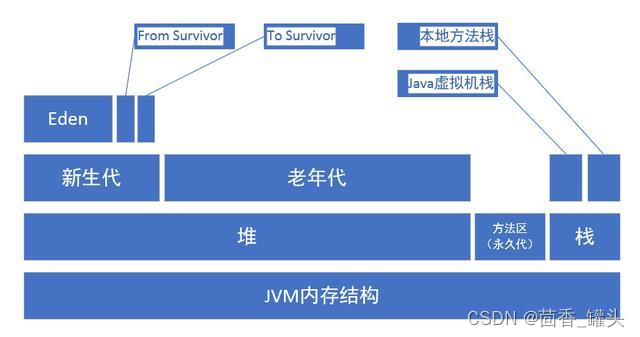
2.1 调优建议
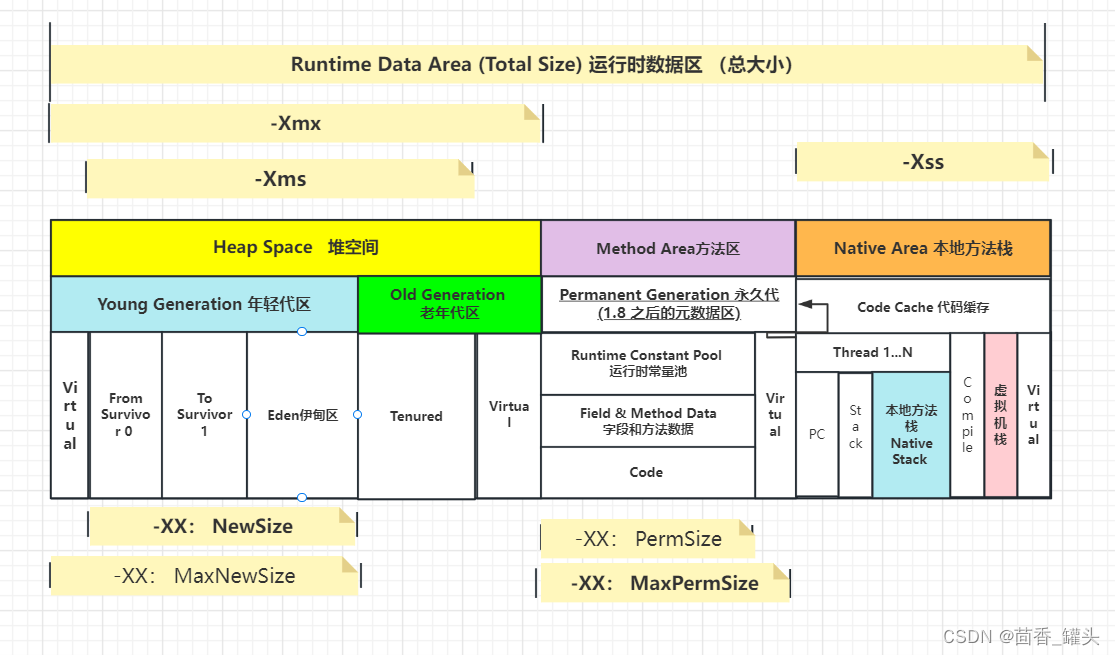
- 针对JVM堆的设置,通常能够经过**-Xms(设置堆的最小空间大小) -Xmx(设置堆的最大空间大小)**限定其最小、最大值,为了防止垃圾收集器在最小、最大之间收缩堆而产生额外的时间,一般把最大、最小设置为相同的值;
- 年轻代和年老代将根据默认的比例(1:2)分配堆内存, 能够经过调整两者之间的比率NewRadio来调整两者之间的大小,也能够针对回收代。默认的,Eden : from : to = 8 : 1 : 1 ( 可以通过参数 –XX:SurvivorRatio 来设定 ),即: Eden = 8/10 的新生代空间大小,from = to = 1/10 的新生代空间大小。
好比年轻代,经过 -XX:newSize -XX:MaxNewSize来设置其绝对大小。一样,为了防止年轻代的堆收缩,咱们一般会把-XX:newSize -XX:MaxNewSize设置为一样大小。 - 年轻代和年老代设置多大才算合理
1)更大的年轻代必然致使更小的年老代,大的年轻代会延长普通GC的周期,但会增长每次GC的时间;小的年老代会致使更频繁的Full GC
2)更小的年轻代必然致使更大年老代,小的年轻代会致使普通GC很频繁,但每次的GC时间会更短;大的年老代会减小Full GC的频率
如何选择应该依赖应用程序对象生命周期的分布状况: 若是应用存在大量的临时对象,应该选择更大的年轻代;若是存在相对较多的持久对象,年老代应该适当增大。但不少应用都没有这样明显的特性。
在抉择时应该根 据如下两点:
(1)本着Full GC尽可能少的原则,让年老代尽可能缓存经常使用对象,JVM的默认比例1:2也是这个道理 。
(2)经过观察应用一段时间,看其余在峰值时年老代会占多少内存,在不影响Full GC的前提下,根据实际状况加大年轻代,好比能够把比例控制在1:1。但应该给年老代至少预留1/3的增加空间。 - 在配置较好的机器上(好比多核、大内存),能够为年老代选择并行收集算法: -XX:+UseParallelOldGC 。
- 线程堆栈的设置:每一个线程默认会开启1M的堆栈,用于存放栈帧、调用参数、局部变量等,对大多数应用而言这个默认值太大了,通常256K就足用。理论上,在内存不变的状况下,减小每一个线程的堆栈,能够产生更多的线程,但这实际上还受限于操做系统。
2.2 调优工具之jps(Java Virtual Machine Process Status Tool)
2.3 调优工具之jstack
2.4 调优工具之jmap(Memory Map)和jhat(Java Heap Analysis Tool)
2.5 jstat(JVM统计监测工具)
2.6 hprof(Heap/CPU Profiling Tool)
2.7 jconsole、jvisualvm
2.8 jinfo
2.9 依赖、参考的数据有系统运行日志、堆栈错误信息、gc日志、线程快照、堆转储快照进行调优
使用方面查看以下文章!
参考地址:
https://blog.csdn.net/fedorafrog/article/details/104503740
https://blog.csdn.net/weixin_45735355/article/details/121397268















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









