










目录
2.7.1 minidom.parse(parse=None,bufsie=None)
2.7.3 doc.toxml(encoding=None)
2.7.5 node.getAttribute(attname)
2.7.6 node.getElementsByTagName(name)
2.7.8 node.childNodes[index].data
2.8.1 minidom.Document()创建xml空白文档
2.8.2 doc.createElement(tagName)
2.8.3 node.setAttribute(attname,value)添加节点属性
2.8.4 doc.createTextNode(data)
2.8.5 doc/parentNode.appendChild(node)
一、json
1.1 json简介
json是java script object notation的缩写,用来存储和交换文本信息,比xml更小/更快/更易解析,易于读写,占用带宽小,网络传输速度快的特性,适用于数据量大,不要求保留原有类型的情况。
Python的json模块序列化和反序列化分别是dumps和loads。
- json.dumps():将一个Python对象编码成json字符串
- json.loads():将json格式字符串解码成Pyhton对象
对简单的数据类型可以直接处理。如:string、Unicode、int、float、list、tuple、dict
1.2 json语法和语法规则
- 数据在名称/值对中
- 数据用逗号分隔
- 花括号保存对象
- 方括号保存数组
1.3 json名称/值对
名称/值对包括字段名称(在双引号中),后面写一个冒号,然后是值,比如:"firstName" : "John"
等价于下面这条JavaScript语句:firstName = "John"
json值可以是:
- 数字(整数、浮点数)
- 字符串(在双引号中)
- 逻辑值(true或false)
- 数组(在方括号中)
- 对象(在花括号中)
- null
1.4 json对象
在花括号中书写,对象可以包含多个名称/值对,例:
{"firstname":"jonh","lastname":"Doe"}
这等价于JavaScript语句:
firstName = "John"
lastName = "Doe"
1.5 json数组
在方括号中书写,数组可以包含多个对象:
{
"employees":[
{ "firstName":"John" , "lastName":"Doe" },
{ "firstName":"Anna" , "lastName":"Smith" },
{ "firstName":"Peter" , "lastName":"Jones" }
]
}
employees是包含三个对象的数组。每个对象代表一条关于某个人名的记录
1.6 json编码
>>> json.dumps({1:2})
'{"1": 2}'
>>> json.dumps({True:False})
'{"true": false}'
>>> json.dumps({None:[1,1.2,True]})
'{"null": [1, 1.2, true]}'
>>> json.dumps((1,22,545)) #元组变成了列表
'[1, 22, 545]'
>>> json.dumps(12345)
'12345'
>>> json.dumps(12.55)
'12.55'
>>> json.dumps({None:"这个"})
'{"null": "\\u8fd9\\u4e2a"}'
>>> json.dumps({1:3,True:False}) # 被合并
'{"1": false}'
>>> json.dumps({2:3,True:False})
'{"2": 3, "true": false}'1.6.1 json.dumps()
将一个Python数据类型列表编码成json格式的字符串
python类型与json类型对比
根据以上输出结果会发现Python对象被转成JSON字符串以后,跟原始的数据类型相比会有些特殊的变化,原字典中的元组被改成了json类型的数组。在json的编码过程中,会存在从Python原始类型转化json类型的过程,但这两种语言的类型存在一些差异,对照表如下:
| python类型 | json字符串类型 |
| dict | object |
| list, tuple | array |
| int, float | number |
| str(注意bytes类型不能转换为json) | string |
| True | true |
| False | false |
| None | null |
>>> a = [{1:12,"a":12.3}, [1,2,3],(1,2), "asd", "ad", 12,13,3.3,True, False, None]
>>> print("Python类型:\n", a)
Python类型:
[{1: 12, 'a': 12.3}, [1, 2, 3], (1, 2), 'asd', 'ad', 12, 13, 3.3, True, False, None]
>>> print("编码后的json串:\n", json.dumps(a))
编码后的json串:
[{"1": 12, "a": 12.3}, [1, 2, 3], [1, 2], "asd", "ad", 12, 13, 3.3, true, false, null]函数原型:
dumps(obj, skipkeys=False, ensure_ascii=True, check_circular=True, allow_nan=True,
cls=None, indent=None, separators=None, encoding='utf-8', default=None,sort_keys=False, **kw)
➢ 该方法返回编码后的一个json字符串,是一个str对象encodedjson。
➢ dumps函数的参数很多,但是不是所有的都必须弄清楚,下面只说明几个比较常用的参数。
1) sort_keys :是否按字典排序( a到z)输出。因为默认编码成json格式字符串后,是紧凑输出,并且也没有顺序的,不利于可读。
>>> data = [{'a':"A",'x':(2,4),'c':3.0,"b":4}]
>>> print(json.dumps(data))
[{"a": "A", "x": [2, 4], "c": 3.0, "b": 4}]
>>> print(json.dumps(data,sort_keys=True))
[{"a": "A", "b": 4, "c": 3.0, "x": [2, 4]}]
>>> data = [{'a':"A",'x':(2,4),'c':3.0,"b":4,"Dog":True,"dog":None,"amy":100,"apple":200}]
>>> print(json.dumps(data))
[{"a": "A", "x": [2, 4], "c": 3.0, "b": 4, "Dog": true, "dog": null, "amy": 100, "apple": 200}]
>>> print(json.dumps(data,sort_keys=True))
[{"Dog": true, "a": "A", "amy": 100, "apple": 200, "b": 4, "c": 3.0, "dog": null, "x": [2, 4]}]2)indent:indent默认值为None,表示以最紧凑的方式打印。如果indent是非负整数,则JSON数组元素和对象成员将以该缩进级别打印出来。如果indent=0表示将仅插入换行符。
>>> data = [{"a": "A", "b": [2, 4], "c": 3.0}]
>>> print(json.dumps(data, sort_keys=True, indent=4))
[
{
"a": "A",
"b": [
2,
4
],
"c": 3.0
}
]
>>> print(json.dumps(data, sort_keys=True, indent=0))
[
{
"a": "A",
"b": [
2,
4
],
"c": 3.0
}
]
>>> print(json.dumps(data, sort_keys=True))
[{"a": "A", "b": [2, 4], "c": 3.0}]3)separators:参数的作用是去掉逗号“,”和冒号“:”后面的空格。
>>> data = [{"a": "A", "b": [2, 4], "c": 3.0}]
>>> print(json.dumps(data))
[{"a": "A", "b": [2, 4], "c": 3.0}]
>>> print(len(json.dumps(data)))
35
>>> # 去掉编码后的json串中,和:后面的空格
>>> print(json.dumps(data, separators=(',',':')))
[{"a":"A","b":[2,4],"c":3.0}]
>>> print(len(json.dumps(data, separators=(',',':'))))
29从上面的输出结果都能看到“,”与“:”后面都有个空格,这都是为了美化输出结果的作用,但是在我们传输数据的过程中,越精简越好,冗余的东西全部去掉,因此就可以加上separators参数对传输的json串进行压缩。该参数是元组格式的。
4)skipkeys:在encoding过程中, dict对象的key只可以是基本数据类型(str,unicode,int,long,float,bool,None),如果是其他类型,那么在编码过程中就会抛出TypeError的异常。 skipkeys可以跳过那些非string对象的key的处理,就是不处理
>>> data= [ { 'a':'A', 'b':(2, 4), 'c':3.0, (1,2):'D tuple' } ]
>>> print("不设置skipkeys 参数")
不设置skipkeys 参数
>>> try :
... res1 = json.dumps(data) #skipkeys参数默认为False时
... except Exception as e:
... print(e)
...
keys must be str, int, float, bool or None, not tuple
>>> print("设置skipkeys 参数")
设置skipkeys 参数
>>> print(json.dumps(data, skipkeys=True))#skipkeys=True时
[{"a": "A", "b": [2, 4], "c": 3.0}]5)ensure_ascii:表示编码使用的字符集,默认是是True,表示使用ascii码进行编码。如果设置为False,就会以Unicode进行编码。由于解码json字符串时返回的就是Unicode字符串,所以可以直接操作Unicode字符,然后直接编码Unicode字符串,这样会简单些。
>>> print (json.dumps('中国'))
"\u4e2d\u56fd"
>>> print (json.dumps('中国',ensure_ascii=False))
"中国"6)check_circular:如果check_circular为false,则跳过对容器类型的循环引用检查,循环引用将导致溢出错误(或更糟的情况)。
7)allow_nan:如果allow_nan为假,则ValueError将序列化超出范围的浮点值(nan、inf、-inf),严格遵守JSON规范,而不是使用JavaScript等价值(nan、Infinity、-Infinity)。
8)default:将类对象编码成json串
类对象序列化成json类型
Python中的dict对象可以直接序列化为json的{},但是很多时候,可能用class表示对象,比如定义Employe类,然后直接去序列化就会报错。原因是类不是一个可以直接序列化的对象,但我们可以使用dumps()函数中的default参数来实现,由两种方法:
- 在类内部定义一个obj_json 方法将对象的属性转换成dict,然后再被序列化为json。
- 通过__dict__属性,通常class及其实例都会有一个__dict__属性(除非类中添加了__slots__属性),它是一个dict类型,存储的是类或类实例中有效的属性
代码示例1:通过类中的方法实现
import json
class Employee(object):
def __init__(self,name,age,sex,tel):
self.name=name
self.age=age
self.sex=sex
self.tel=tel
#将序列化函数定义到类中
def obj_json(self,obj_instance):
return{
'name':obj_instance.name,# 这里不能直接用self.name
'age':obj_instance.age,
'sex':obj_instance.sex,
'tel':obj_instance.tel
}
emp=Employee('kongsh',28,'female',13123456789)
print (json.dumps(emp,default=emp.obj_json))
# dumps()将emp实例传递给了emp.obj_json方法中的obj_instance参数,以此获得了一个返回的字典对象,并生成了一个json串![]()
代码示例2:通过类的__dict__属性实现
import json
class Employee(object):
def __init__(self,name,age,sex,tel):
self.name=name
self.age=age
self.sex=sex
self.tel=tel
emp=Employee('kongsh',18,'female',13123456789)
print (emp.__dict__)
print (json.dumps(emp,default=lambda Employee:Employee.__dict__)) 名
print (json.dumps(emp,default=lambda emp:emp.__dict__))
#lambda后面的Employee和emp只是一个变量名称,dumps()函数会把类实例emp传递给lambda的参数
1.6.2 json.loads()
将json的字符串解码成python对象
json类型转换为python类型
在编码过程中,Python中的list和tuple都被转化成json的数组,而解码后,json的数组最终被转化成Python的list的,无论是原来是list还是tuple。
| json格式 | python格式 |
| object | dict |
| array | list |
| string | unicode |
| number(int) | int |
| numer(real) | float |
| true | True |
| false | False |
| null | None |
>>> import json
>>> json.loads('{"1":"hello"}')
{'1': 'hello'}
>>> json.loads('{"1":[1,2,3]}')
{'1': [1, 2, 3]}
>>> json.loads('{"1":[1,2,3]}')["1"]
[1, 2, 3]
>>> json.loads('{"true":"false"}')
{'true': 'false'}
>>> a = [{1:12, 'a':12.3}, [1,2,3], (1,2), 'asd', 'ad', 12,13, 3.3, True, False, None]
>>> print(u"编码后\n", json.dumps(a))
编码后
[{"1": 12, "a": 12.3}, [1, 2, 3], [1, 2], "asd", "ad", 12, 13, 3.3, true, false, null]
>>> print(u"解码后\n", json.loads(json.dumps(a)))
解码后
[{'1': 12, 'a': 12.3}, [1, 2, 3], [1, 2], 'asd', 'ad', 12, 13, 3.3, True, False, None]json反序列化类对象
import json
class Employee(object):
def __init__(self, name, age, sex, tel):
self.name = name
self.age = age
self.sex = sex
self.tel = tel
def jsonToClass(emp):
# print(type(emp))
return Employee(emp['name'], emp['age'], emp['sex'], emp['tel'])
json_str = '{"name": "Lucy", "age": 21, "sex": "female", "tel": "15834560985"}'
e = json.loads(json_str, object_hook = jsonToClass)
print(e)
print(e.name)
# 把json_str的json内容经过loads()内部处理,生成了一个字典,然后传递给jsonToClass(),方法执行后返回了一个Employee实例
二、xml
2.1 xml简介
XML 指的是可扩展标记语言(eXtensible Markup Language),和json类似也是用于存储和传输数据,还可以用作配置文件。类似于HTML超文本标记语言,但是HTML所有的标签都是预定义的,而xml的标签可以随便定义。
2.2 xml元素
指从开始标签到结束标签的部分(均包括开始和结束)
一个元素可以包括:
- 其它元素
<aa>
<bb></bb>
</aa>
- 属性 <a id=’132’></a>
- 文本 <a >abc</a>
- 混合以上所有
2.3 xml语法规则
- 所有的元素都必须有开始标签和结束标签,省略结束标签是非法的。如:
<root>根元素</root>
- 大小写敏感,以下是两个不同的标签
<Note>this is a test1</Note>
<note>this is a test2</note>- xml文档必须有根元素
<note>
<b>this is a test2</b>
<name>joy</name>
</note>- XML必须正确嵌套,父元素必须完全包住子元素。如:
<note><b>this is a test2</b></note>- XML属性值必须加引号,元素的属性值都是一个键值对形式。如:
<book category=" Python"></book>注意:元素book的category属性值python必须用引号括起来,单引号双引号都可以。如果属性值中包含单引号那么用双引号括起来,如果属性值包含单引号那么外面用双引号括起来。
2.4 xml命名规则
- 名称可以包含字母、数字以及其他字符
- 名称不能以数字或标点符号开头
- 名称不能以字母xml或XML开始
- 名称不能包含空格
- 可以使用任何名称,没有保留字
- 名称应该具有描述性,简短和简单,可以同时使用下划线。
- 避免“-”、“.”、“:”等字符
Xml的注释格式:<!--注释内容-->
2.5 CDATA
CDATA( Unparsed Character Data)指的是不应由XML解析器进行解析的文本数据。
因为XML解析器会将“<”(新元素的开始)和” &”(字符实体的开始)解析成具有特殊含义的字符,所以如果在文本中需要使用这些字符时,就必须使用实体引用去代替。但是有些文本,如JavaScript代码中会包含大量的” <”和” &”符号,这时我们可以将我们的脚本定义为CDATA来避免这个问题,因为XML文档中的所有文本均会被解析器解析,只有CDATA部分中所有的内容会被XML解析器忽略
<script>
<![CDATA[
function test(x, y)
{ if (x < 0 && y < 0) then
{
return 0;
}
else
{
return 1;
}}
]]>
</script>2.6 Python解析xml的三种方法
常见的XML编程接口有DOM和SAX,这两种接口处理XML文件的方式不同,使用场合也不同。python有三种方法解析XML:SAX,DOM和ElementTree
- DOM(Document Object Model)
DOM的解析器在解析一个XML文档时,一次性读取整个文档,把文档中所有元素保存在内存中的一个树结构里,之后利用DOM提供的不同函数来读取该文档的内容和结构,也可以把修改过的内容写入XML文件。由于DOM是将XML读取到内存,然后解析成一个树,如果要处理的XML文本比较大的话,就会很耗内存,所以DOM一般偏向于处理一些小的XML,(如配置文件)比较快。
- SAX(simple API for XML)
Python标准库中包含SAX解析器,SAX是用的是事件驱动模型,通过在解析XML过程中触发一个个的事件并调用用户定义的回调函数来处理XML文件。
解析的基本过程:
读到一个XML开始标签,就会开始一个事件,然后事件就会调用一系列的函数去处理一些事情,当读到一个结束标签时,就会触发另一个事件。所以,我们写XML文档入如果有格式错误的话,解析就会出错。
这是一种流式处理,一边读一边解析,占用内存少。适用场景如下:
1、对大型文件进行处理;
2、只需要文件的部分内容,或者只需从文件中得到特定信息。
3、想建立自己的对象模型的时候。
- ElementTree(元素树)
ElementTree就像一个轻量级的DOM,具有方便友好的API。代码可用性好,速度快,消耗内存少。
注:因DOM需要将XML数据映射到内存中的树,一是比较慢,二是比较耗内存,而SAX流式读取XML文件,比较快,占用内存少,但需要用户实现回调函数(handler)。
2.7 xml.dom解析xml
2.7.1 minidom.parse(parse=None,bufsie=None)
函数作用:使用parse解析器打开xml文档,并将其解析为DOM文档,也就是内存中的一棵树,并得到这个对象
2.7.2 doc.documentElement
获取xml文档对象,就是拿到DOM树的根
2.7.3 doc.toxml(encoding=None)
返回xml的文档内容
#coding=utf-8
from xml.dom.minidom import parse
#minidom解析器打开xml文档并将其解析为内存中的一棵树
DOMTree = parse(r"book.xml")
print(type(DOMTree))
#获取xml文档对象,就是拿到树的根
booklist = DOMTree.documentElement
print("DOM数的根对象:",booklist)
print(type(booklist))
print("xml文档内容:",DOMTree.toxml())
2.7.4 hasAttribute(name)
判断某个节点node是否存在某个属性,存在返回True,否则返回False
>>> if booklist.hasAttribute("type"):
... #判断根节点booklist是否有type属性
... print("booklist元素存在type属性")
... else :
... print("booklist元素不存在type属性")
...
booklist元素存在type属性2.7.5 node.getAttribute(attname)
获取节点node的某个属性的值
>>> if booklist.hasAttribute("type") :
... #判断根节点booklist是否有type属性,有则获取并打印属性的值
... print("Root element is:", booklist.getAttribute("type"))
...
Root element is: science and engineering2.7.6 node.getElementsByTagName(name)
获取XML文档中某个父节点下具有相同节点名的节点对象集合,是一个list对象。
>>> #获取booklist对象中所有book节点的list集合
>>> books = booklist.getElementsByTagName("book")
>>> print(type(books))
<class 'xml.dom.minicompat.NodeList'>
>>> print(books)
[<DOM Element: book at 0x24e3c57b400>, <DOM Element: book at 0x24e3c58e170>]
>>> books[0].getElementsByTagName("title")
[<DOM Element: title at 0x24e3c58dfc0>]
>>> books[0].getElementsByTagName("title")[0].tagName
'title'2.7.7 node.childNodes
返回节点node下所有子节点组成的list
>>> #获取booklist对象中所有book节点的list集合
>>> books = booklist.getElementsByTagName("book")
>>> print(books[0].childNodes) # 包含了换行
[<DOM Text node "'\n\t\t'">, <DOM Element: title at 0x24e3c58dfc0>, <DOM Text node "'\n\t\t'">, <DOM Element: author at 0x24e3c58e050>, <DOM Text node "'\n\t'">, <DOM Element: pageNumber at 0x24e3c58e0e0>, <DOM Text node "'\n'">]
>>> books[0].childNodes[1].tagName
'title'
>>> books[0].childNodes[1].childNodes[0].data
'learning math'
>>> books[0]
<DOM Element: book at 0x24e3c57b400>
>>> books[0].childNodes[1]
<DOM Element: title at 0x24e3c58dfc0>
>>> books[0].childNodes[1].childNodes[0]
<DOM Text node "'learning m'...">
>>> books[0].childNodes[1].childNodes[0].data
'learning math'#coding=utf-8
#从xml.dom.minidom模块引入解析器parse
from xml.dom.minidom import parse
#minidom解析器打开xml文档并将其解析为内存中的一棵树
DOMTree = parse(r"book.xml")
print(type(DOMTree))
booklist = DOMTree.documentElement
print(booklist)
print("*"*30)
books = booklist.getElementsByTagName("book")
d={}
for j in range(2):
for i in range(1,6,2):
tag_name = "book" + str(j) + books[j].childNodes[i].tagName
d[tag_name]=books[j].childNodes[i].childNodes[0].data
print(d)
for k,v in d.items():
print(k,v)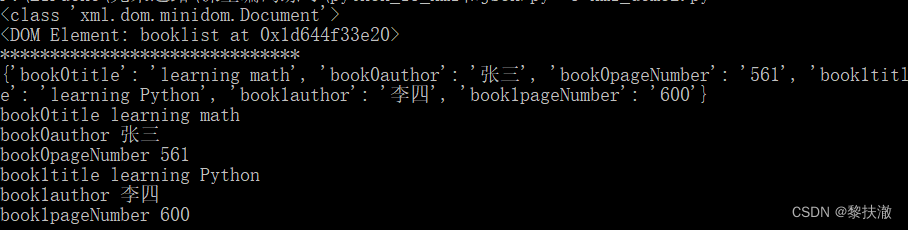
练习:写一个类ParseXML,实例化的传一个文件路径作为参数ParseXML("e:\\database.xml"),实现一个方法,可以读出执行标签的文本内容:
p.get_tag_content("username")--->root
#coding=utf-8
from xml.dom.minidom import parse
class ParseXML:
def __init__(self,file_path):
self.file_path = file_path
self.DOMTree = parse(self.file_path)
self.root = self.DOMTree.documentElement
def get_node_dict(self):
result_dict = {}
database = self.root.childNodes[1].childNodes # database子节点列表
for i in range(1,len(database),2):
tag_name = database[i].tagName
result_dict[tag_name] = database[i].childNodes[0].data
return result_dict
def get_tag_content(self,tag_name):
d = self.get_node_dict()
if tag_name in d.keys():
return d[tag_name]
else:
return
p = ParseXML("database.xml")
print(p.get_node_dict())
print(p.get_tag_content("host"))
print(p.get_tag_content("username"))
print(p.get_tag_content("password"))
print(p.get_tag_content("datasename"))
print(p.get_tag_content("test"))
2.7.8 node.childNodes[index].data
获取节点node的文本值,即标签之间的文本内容。
2.7.9 node.hasChildNodes()
判断节点node下是否有叶子节点,如果有返回True,否则返回False。
但是需要注意的是,每个节点都默认有一个文本叶子节点,所以只要标签后有值,就返回True,只有当标签后没值时并且也没有叶子节点时才会返回False
>>> if books[0].hasChildNodes():
... print("有子节点")
... else:
... print("没有子节点")
...
有子节点
>>> books[0]
<DOM Element: book at 0x19c3264dfc0>
>>> if books[0].childNodes[0].hasChildNodes():
... print("有子节点")
... else:
... print("没有子节点")
...
没有子节点
>>> books[0].childNodes[0]
<DOM Text node "'\n\t\t'">#coding=utf-8
from xml.dom.minidom import parse
import xml.dom.minidom
# 使用minidom解析器打开 XML 文档
DOMTree = xml.dom.minidom.parse("movie.xml")
collection = DOMTree.documentElement # 拿到树的根
# 判断根节点是否存在shelf属性
if collection.hasAttribute("shelf"):
# 存在则打印shelf属性的值
print("Root element's attribute value:%s" % collection.getAttribute("shelf"))
# 获取所有名为movie的节点list
movies = collection.getElementsByTagName("movie")
# 打印每部电影的详细信息
for movie in movies:
print("******movie******")
# 判断movie节点是否存在title属性
if movie.hasAttribute("title"):
# 打印属性值
print("title:%s" % movie.getAttribute("title"))
# 获取名为type的节点list
type = movie.getElementsByTagName("type")[0] # 因为list中只有一个值,所以直接用[0]
# 打印type节点的文本
print("type:%s"%type.childNodes[0].data) # 因为type节点仅有一个文本叶子节点,所以用childNodes[0]
# 获取名为format的节点list
format = movie.getElementsByTagName("format")[0]
# 打印format节点的文本
print("format:%s"%format.childNodes[0].data)
# 获取名为rating的节点list
rating = movie.getElementsByTagName("rating")[0]
# 打印rating节点的文本
print("rating:%s"%rating.childNodes[0].data)
# 获取名为description的节点list
description = movie.getElementsByTagName("description")[0]
# 打印description节点的文本
print("description:%s"%description.childNodes[0].data)2.8 xml.dom创建xml
创建步骤:
- 创建XML空白文档
- 产生根对象
- 向根对象中加入数据
- 将xml内存对象写入文件
2.8.1 minidom.Document()创建xml空白文档
该方法用于创建一个空白的xml文档对象,并返回这个doc对象。每个xml文档都是一个Document对象,代表着内存中的DOM树
>>> #coding=utf-8
>>> import xml.dom.minidom
>>> #在内存中创建一个空的文档
>>> doc = xml.dom.minidom.Document()
>>> print(doc)
<xml.dom.minidom.Document object at 0x00000232A0206C80>2.8.2 doc.createElement(tagName)
生成XML文档节点。参数表示待生成的节点名称
>>> #创建一个根节点Managers对象
>>> root = doc.createElement('Managers')
>>> print("添加的xml标签为: ", root.tagName)
添加的xml标签为: Managers2.8.3 node.setAttribute(attname,value)添加节点属性
函数作用:给节点添加属性-值对(attribute)
参数说明:
attname:属性的名称
value:属性的值
# 给根节点root添加属性
root.setAttribute('company', 'xx科技')
value = root.getAttribute('company')
print("root元素的'company'属性值为: ", value)2.8.4 doc.createTextNode(data)
给叶子节点添加文本节点
>>> # 给根节点添加一个叶子节点
>>> ceo = doc.createElement('CEO')
>>> #给叶子节点name设置一个文本节点,用于显示文本内容
>>> ceo.appendChild(doc.createTextNode('吴总'))
<DOM Text node "'吴总'">
>>> print(ceo.tagName)
CEO
>>> print("给叶子节点添加文本节点成功")
给叶子节点添加文本节点成功2.8.5 doc/parentNode.appendChild(node)
将节点node添加到文档对象doc作为文档树的根节点或者添加到父节点parentNode下作为其子节点
2.8.6 doc.writexml()生成xml文档
函数作用:用于将内存中的xml文档树写入到文件中,并保存到本地磁盘。只有调用该方法后,才能将上面创建的存在于内存中的xml文档写入本地硬盘中,这时才能看到新建的xml文档
语法:
writexml(file,indent='',addindent='',newl='',endocing=None)
参数说明:
file:要保存为的文件对象名
indent:根节点的缩进方式
allindent:子节点的缩进方式
newl:针对新行,指明换行方式
encoding:保存文件的编码方式
#coding=utf-8
import xml.dom.minidom
import codecs
#在内存中创建一个空的文档
doc = xml.dom.minidom.Document()
print(doc)
#创建一个根节点company对象
root = doc.createElement('companys')# 根节点:companys
# 给根节点root添加属性
root.setAttribute("name","公司列表")
#将根节点添加到文档对象中
doc.appendChild(root)
# 给根节点添加一个叶子节点
company = doc.createElement('gloryroad')# 子节点:gloryroad
# 叶子节点下再嵌套叶子节点
name = doc.createElement("Name")# 子节点:Name
# 给节点添加文本节点
name.appendChild(doc.createTextNode("光荣之路教育科技"))
ceo = doc.createElement('CEO')# 子节点:CEO
ceo.appendChild(doc.createTextNode('吴老师'))
# 将各叶子节点添加到父节点company中
# 然后将company添加到跟节点companys中
company.appendChild(name)# gloryroad子节点:Name
company.appendChild(ceo)# gloryroad子节点:ceo
root.appendChild(company)# companys子节点:gloryroad
fp = open('company.xml', 'w',encoding='utf-8')
doc.writexml(fp, indent='', addindent='\t', newl='\n', encoding="utf-8")
fp.close()















 1316
1316











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









