







 Hadoop的MapReduce计算框架通过JobTracker和TaskTracker实现计算向数据移动。然而,JobTracker的单点故障、资源管理与任务调度集成等问题在Hadoop 2.x中被Yarn解决。Yarn将资源管理和任务调度分离,提供更高效和弹性的资源调度,支持多种计算框架。
Hadoop的MapReduce计算框架通过JobTracker和TaskTracker实现计算向数据移动。然而,JobTracker的单点故障、资源管理与任务调度集成等问题在Hadoop 2.x中被Yarn解决。Yarn将资源管理和任务调度分离,提供更高效和弹性的资源调度,支持多种计算框架。
MapReduce计算框架是如何实现计算向数据移动的呢?
计算向数据移动面临着诸多问题,如:怎么让机器自动移动,面对block的许多副本,怎么判别移动到的是最合适的Datanode
这个问题牵扯到两个概念:资源管理,任务调度
资源管理:掌握各机器当前可用内存,可用CPU等情况
任务调度:根据可用资源,进行计算任务的分配(也就是向哪个Datanode移动)
MapReduce想要完成资源管理和任务调度,需要引进两个新的角色:JobTracker和TaskTracker
JobTracker:负责资源管理,任务调度
TaskTracker:管理被分到Datandoe的计算任务,资源汇报(TaskTracker与JobTracker之间维持心跳,实时汇报当前Datanode资源所剩情况)
JobTracker与TaskTracker之间也是主从结构。
然而推动计算向数据移动的角色是client
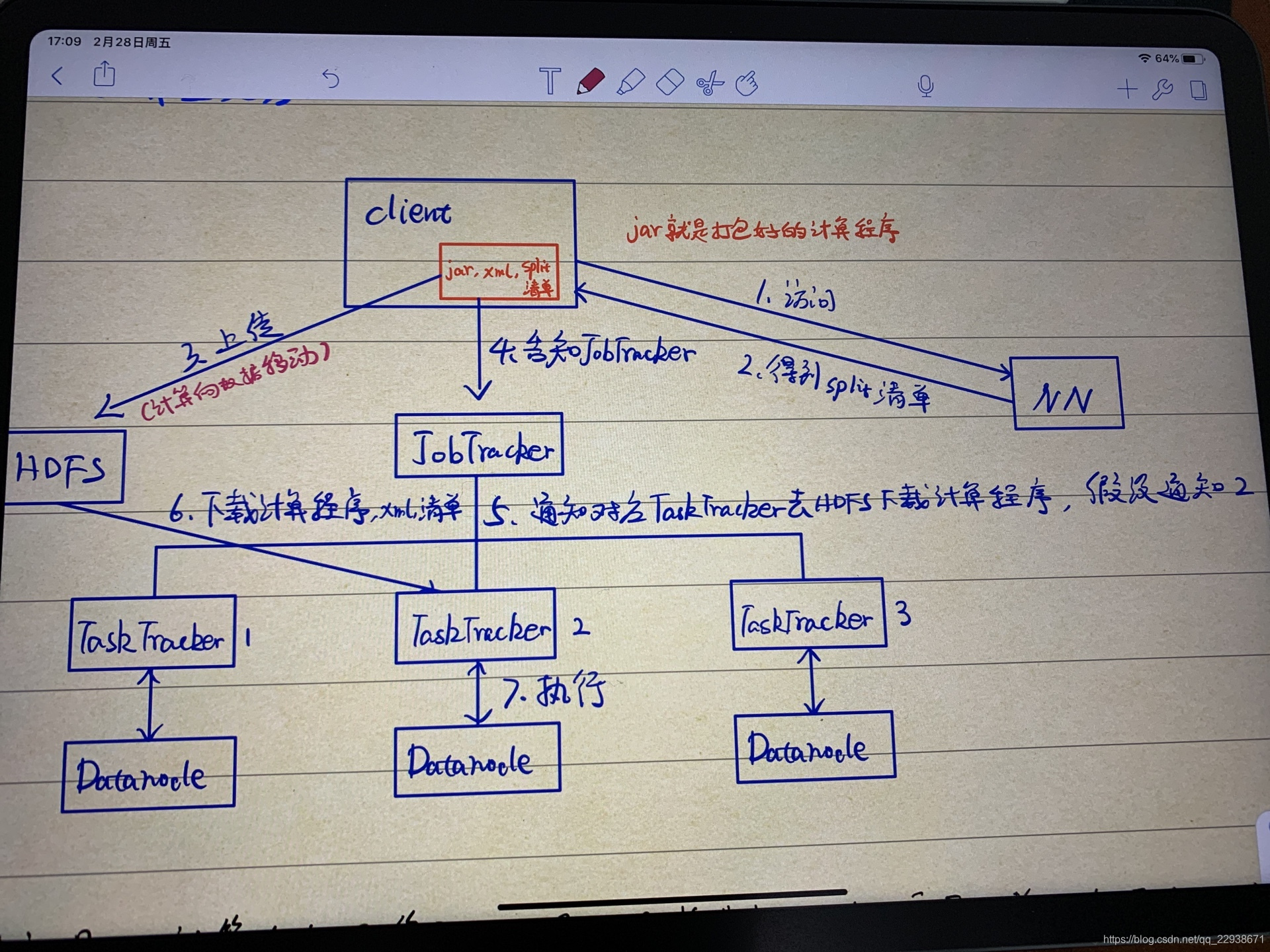
下面具体阐述client到底做了什么
- 根据每次需要计算的数据,咨询NN元数据,得到block信息
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1809
1809

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









