










文章目录
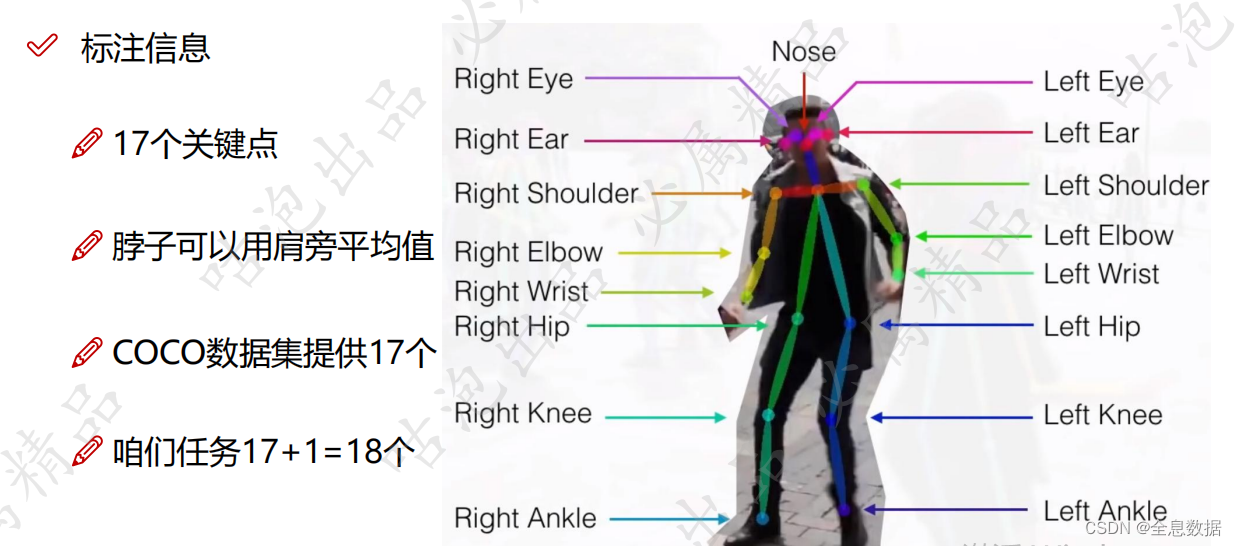
1、人体需要检测的关键点
在本项目中,需要检测人体18个关键点,除了下图所标注的17个关键点外,还有1个脖子关键点
2、Top-down方法
1、检测得到所有人的框;
2、对每一个框进行姿态估计输出结果;
Top-down方法的问题 :
- 1、姿态估计做成啥样主要由人体检测所决定,能检测到效果估计也没问题
- 2、但是如果俩人出现重叠,只检测到一个人,那肯定会丢失一个目标
- 3、计算效率有点低,如果一张图像中存在很多人,那姿态估计得相当慢了
能不能设计一种方法不依赖于人体框而是直接进行预测呢?有的,接下来请看下面的方法,
3、Openpose制作标签和预测细节
3.1 姿态估计的步骤
姿态估计的2个步骤
- 1、识别出图片中所有关键点,
- 2、按顺序拼接同属一个人的所有关键点
如下面左图所示,我们识别人体18个关键点中的右肩关键点,就在图片中建立热度图(高斯),识别18个关键点就需要建立18个特征图

3.2 PAF(Part Affinity Fields)部分亲和场
PAF作用:将属于同一个人的不同关键点按顺序拼接
整体框架如下,1张图片经过CNN网络后分成2个网络,Parts Detection网络是预测关键点,Parts Association网络是预测方向,人体18个关键点总共需要19个不同的方向,而确定方向至少需要1个平面,即 x x x 和 y y y 坐标,所以Parts Association需要预测19x2=38个特征图

3.3 制作PAF标签
Parts Association输出38张特征图,其中19张特征图预测 x x x 坐标,19张特征图预测 y y y 坐标,每一张特征图的像素点都需要输出坐标值。在PAF标签处理中,把2个关键点所包围的矩形当中的所有像素值的方向与2个关键点的方向都一致。
蓝色和红色分别是两个关键点, V V V是其向量, X j 1 , k X_{j_1,k} Xj1,k中 j 1 j_1 j1表示不同的关键点, k k k表示不同的人,
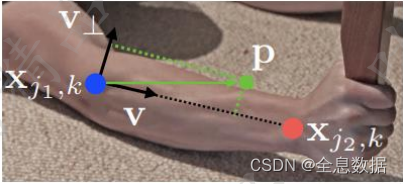
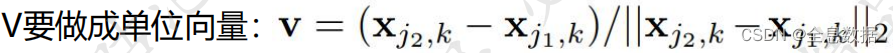

对于其中某个PAF特征图(19种连接方式中的1种),这就相当于得到PAF标签值了,包括所有人在该连接处的向量,

3.4 PAF权值计算
如何确定2个关键点之间的预测方向呢?
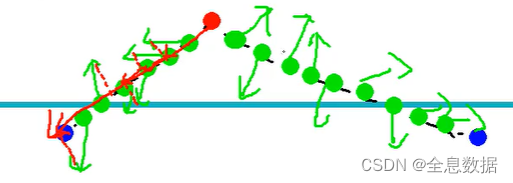
- 比如下图中红色点表示左肩,左边的蓝点表示和左肩属于同一个人的左手肘,右边的蓝点表示另外一个人的左手肘,然后网络会输出每一个点的预测方向,然后比较每一个点的预测方向和ground truth的投影的之和,哪个预测方向的和最大哪个就是最佳的预测方向,
- 如下图所示,绿色小箭头是网络的预测方向,可以看出左边的预测是最佳预测方向,
两个关键点j1与j2之间的权值计算方法
E
=
∫
μ
=
0
μ
=
1
L
c
(
p
(
μ
)
)
⋅
d
j
2
−
d
j
1
∣
∣
d
j
2
−
d
j
1
∣
∣
2
E=\int_{\mu=0}^{\mu=1}L_c(p(\mu))\cdot\frac{d_{j2}-d_{j1}}{\mid\mid d_{j2}-d_{j1}\mid\mid_2}
E=∫μ=0μ=1Lc(p(μ))⋅∣∣dj2−dj1∣∣2dj2−dj1
p
(
μ
)
=
(
1
−
μ
)
d
j
1
+
μ
d
j
2
p(\mu)=(1-\mu)d_{j1}+\mu d_{j2}
p(μ)=(1−μ)dj1+μdj2
d
j
1
d_{j1}
dj1,
d
j
2
d_{j2}
dj2分别表示
j
1
j1
j1与
j
2
j2
j2两点的坐标,求
j
1
j1
j1和
j
2
j2
j2间各点的PAF在线段
j
1
j
2
j1j2
j1j2上投影的积分,其实就是线段上各点的PAF方向如果与线段的方向越接近权值就越大
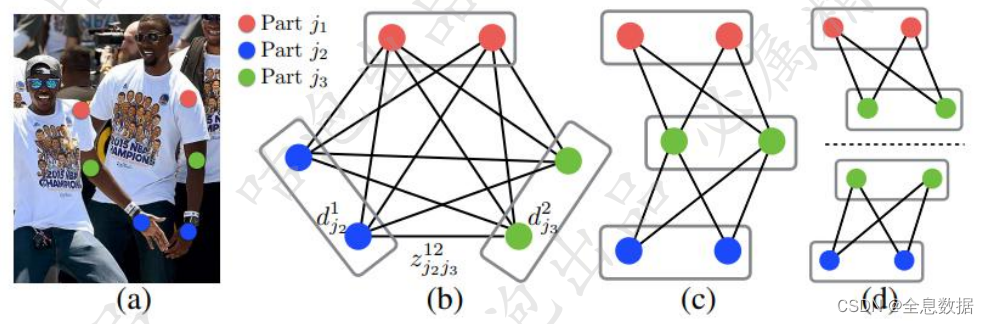
3.5 匹配方法
- 每一个关键点先与其中一个关键点做匹配,而不是每一个关键点与几个关键点做匹配,因为每个关键点先与其中一个关键点做匹配的效果更好,
- 如果同时考虑多种匹配,那太难了
- 咱们固定好就是二分图,这样可以直接套匈牙利算法
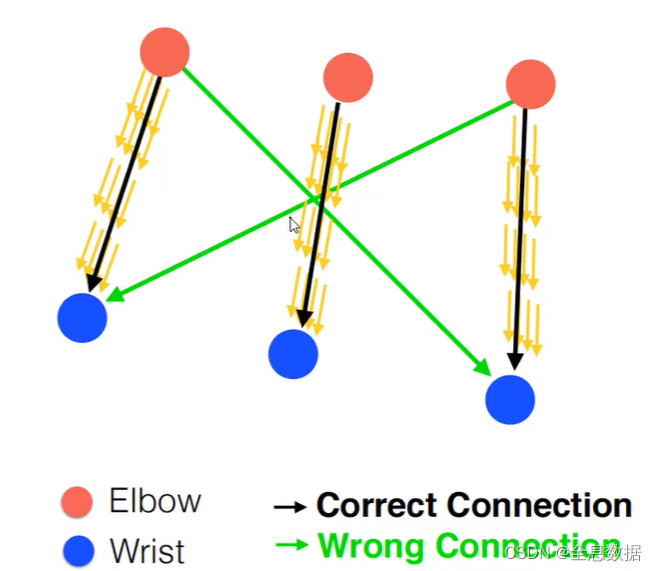
如下图,黑色线是ground truth,黄色小箭头是预测,预测方向和黑色线的投影和最大即为最佳预测方向,而绿色线就是错误匹配,
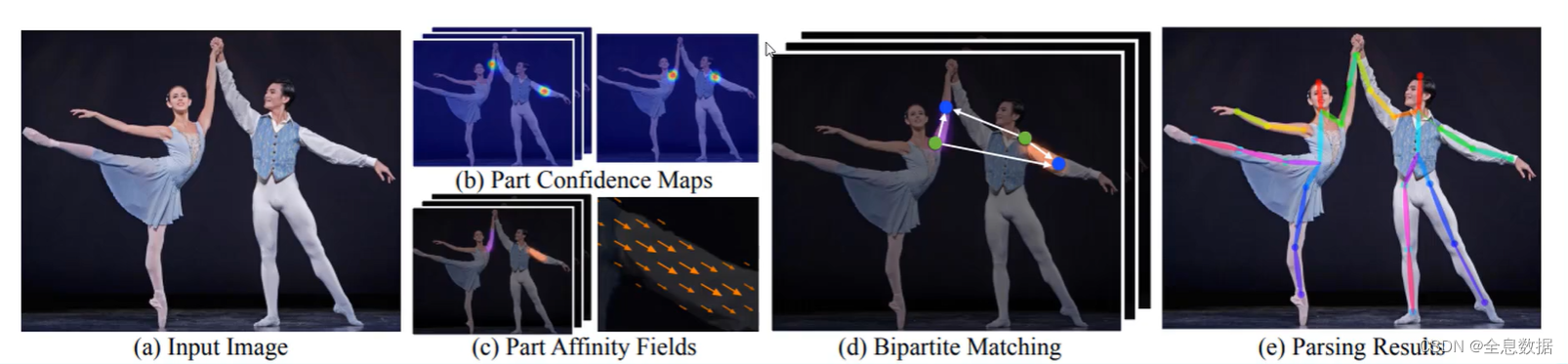
3.6 任务流程
- (a):输入图片
- (b):输入图片的后分为2个分支,一个分支是预测关键点,一个分支是预测关键点之间的方向,其中(b)图是预测关键点,有18个特征图
- (c):预测关键点之间的方向,有19*2个特征图
- (d):选出最佳预测方向
- (e):整合预测的关键点和预测方向,
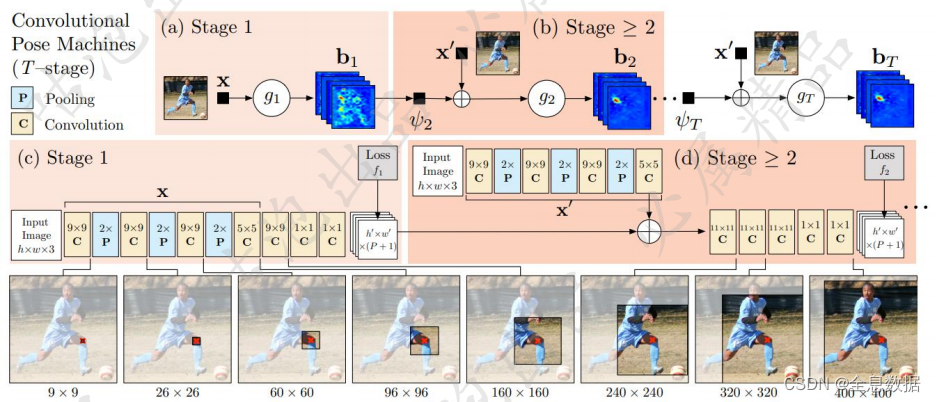
4、CPM(Convolutional Pose Machines)模型
为OpenPose后面的工作奠定了基础,也可以当作基础框架,通过多个stage来不断优化关键点位置(stage1预测完全错误,2和3在纠正)
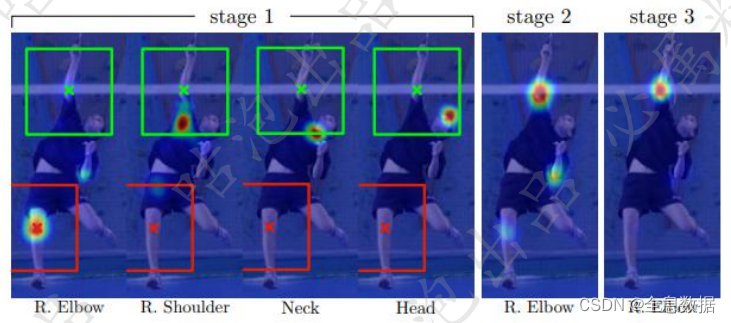
stage越多相当于层数越深,模型感受野越大,姿态估计需要更大的感受野,因为进行关键点检测需要更多关于人体的信息,所以感受野越大则人体的信息越多,关键点检测越能检测准确
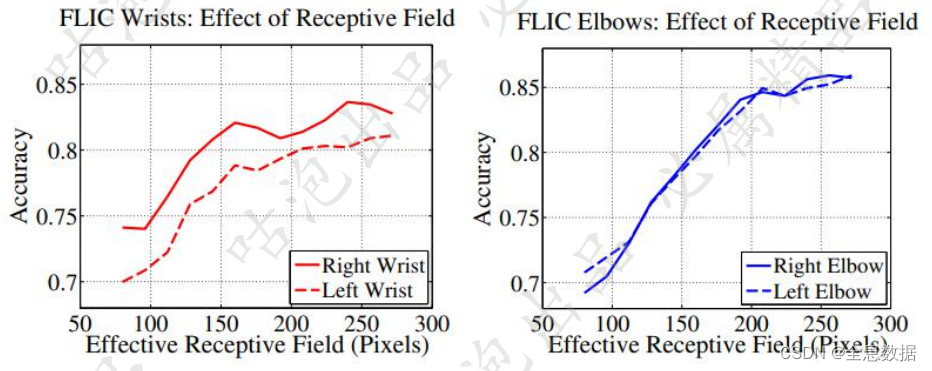
使用多个stage级联的思想,每个stage都加损失函数,也就是中间过程也得做的好才行
5、Openpose所使用的卷积神经网络
- 两个网络结构分别搞定:1、关键点预测;2、姿势的‘亲和力’向量(关键点方向)
- 使用多个stage级联的思想,2个网络结构输出之后再进行特征融合,因为方向的预测离不开关键点的位置信息,关键点的位置信息也与方向有关
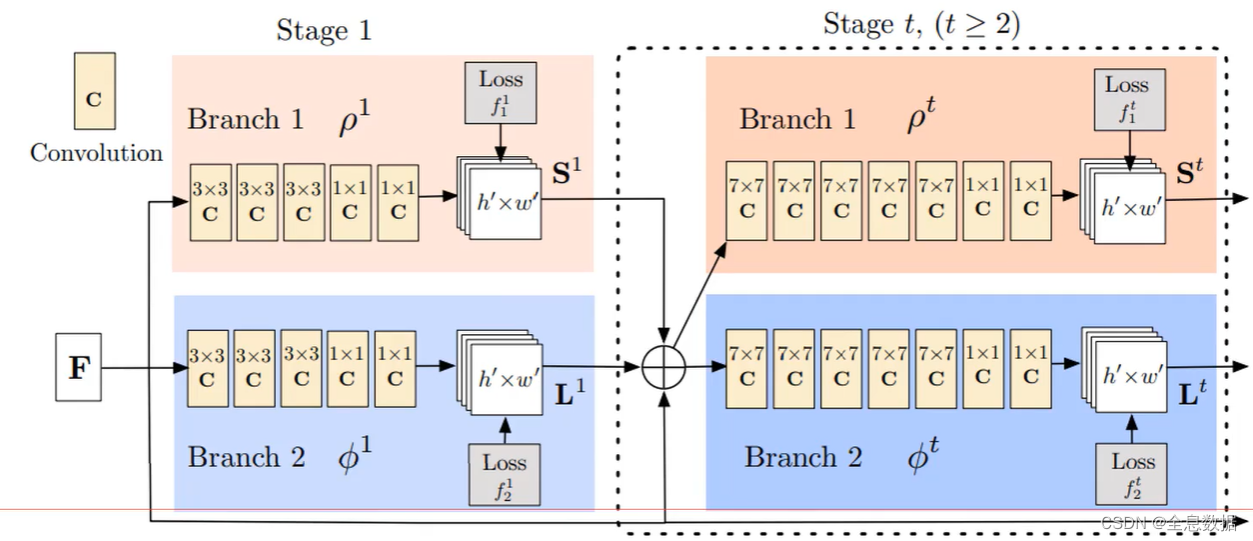
5.1 序列的作用
多个stage,相当于纠正的过程,不断调整预测结果,
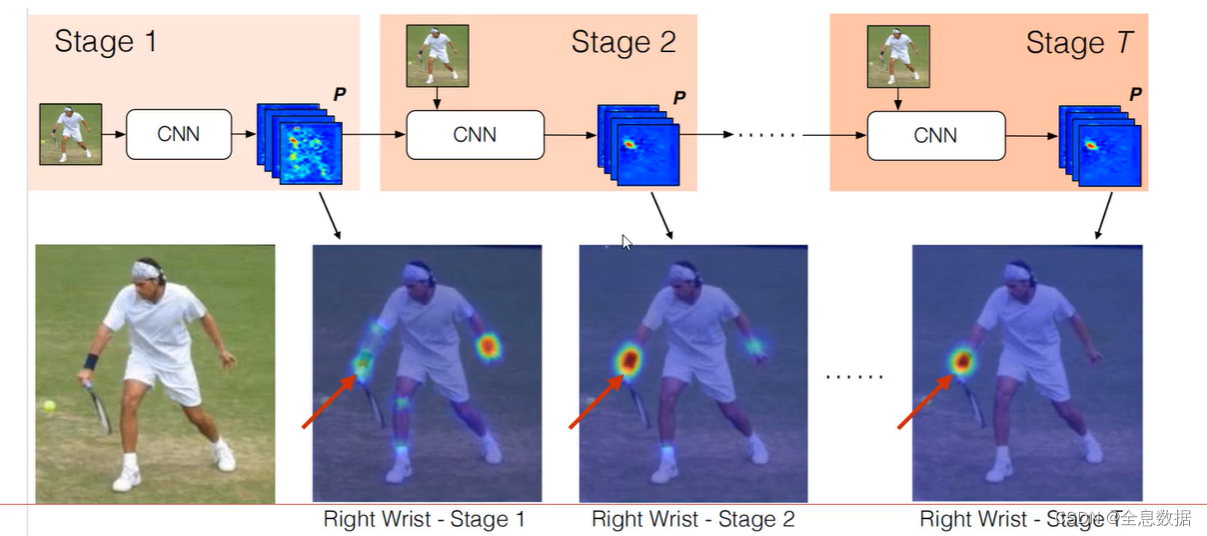
5.2 整体框架
两个分支都要经过多个阶段,注意每个阶段后要把特征拼接一起
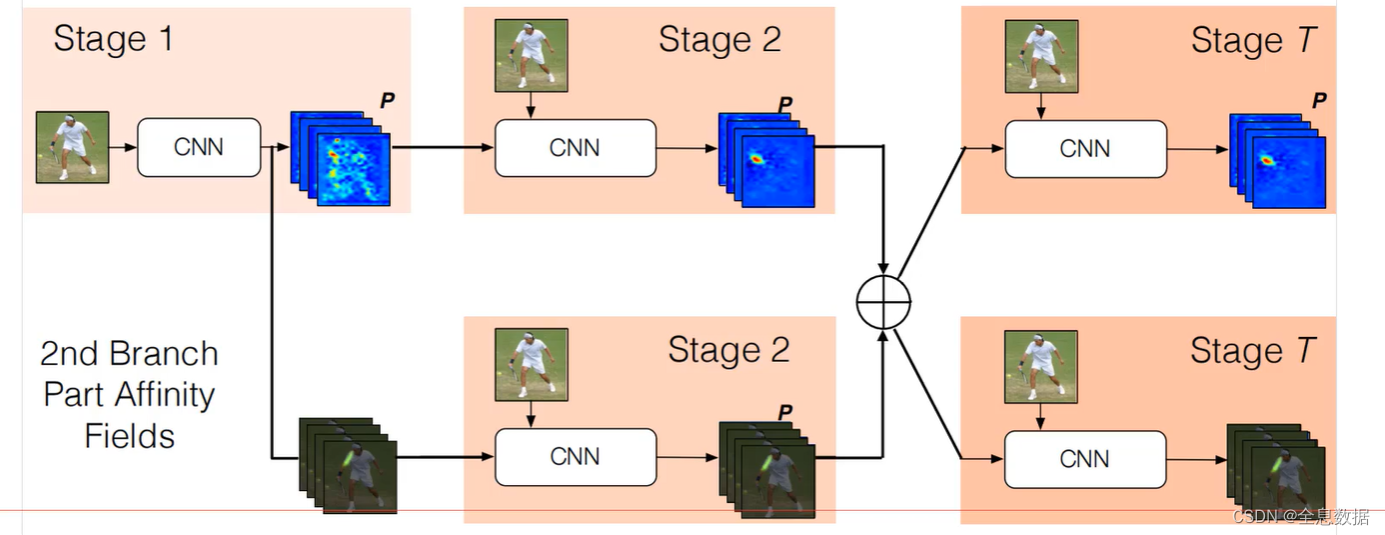
代码:
def forward(self, x):
print(x.shape)
saved_for_loss = []
out1 = self.model0(x) # 46*46的特征图
print(out1.shape)
out1_1 = self.model1_1(out1) # PAF输出
print(out1_1.shape)
out1_2 = self.model1_2(out1) # 关键点输出
print(out1_2.shape)
out2 = torch.cat([out1_1, out1_2, out1], 1)
print(out2.shape)
saved_for_loss.append(out1_1)
saved_for_loss.append(out1_2)
out2_1 = self.model2_1(out2)
out2_2 = self.model2_2(out2)
out3 = torch.cat([out2_1, out2_2, out1], 1)
saved_for_loss.append(out2_1)
saved_for_loss.append(out2_2)
out3_1 = self.model3_1(out3)
out3_2 = self.model3_2(out3)
out4 = torch.cat([out3_1, out3_2, out1], 1)
saved_for_loss.append(out3_1)
saved_for_loss.append(out3_2)
out4_1 = self.model4_1(out4)
out4_2 = self.model4_2(out4)
out5 = torch.cat([out4_1, out4_2, out1], 1)
saved_for_loss.append(out4_1)
saved_for_loss.append(out4_2)
out5_1 = self.model5_1(out5)
out5_2 = self.model5_2(out5)
out6 = torch.cat([out5_1, out5_2, out1], 1)
saved_for_loss.append(out5_1)
saved_for_loss.append(out5_2)
out6_1 = self.model6_1(out6)
out6_2 = self.model6_2(out6)
saved_for_loss.append(out6_1)
saved_for_loss.append(out6_2)
print(out6_1.shape)
print(out6_2.shape)
return (out6_1, out6_2), saved_for_loss
6、训练openpose所需要的数据集格式
key为“keypoints”的后面的内容就是标注的关键点数据,前面2列数据分别是x和y坐标,最后一列的0表示没有被标注,1表示遮挡,2表示没有被遮挡,在实际应用中选用1(标注但被遮挡)和2(标注未遮挡),
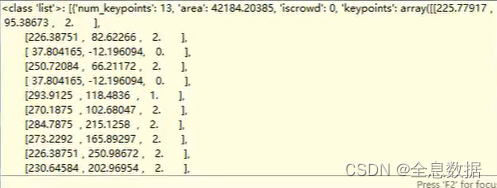
6.1 制作ground truth(重点)
- 比如输入图片的像素是368*368,经过backbone之后的3次下采样特征图变为(368/8)*(368/8),即46*46,预测的结果为了和ground truth比较,所以ground truth的坐标也要除以8,
- 首先制作关键点的ground truth,一共有(18+1)个特征图,18个关键点和1个背景,比如制作右肩的特征图,在右肩的中心点标注为1,然后逐渐递减0.9,0.8一直到0,如下图所示,
- 需要注意如果发生不同的人的关键点的重合,采取相加的策略,然后再与1比较大小,大于1则为1,小于1则不改变,
- 需要注意到,训练数据只标注了17个关键点,没有标注脖子关键点,所以还需要对左肩和右肩的关键点坐标进行处理得到脖子这个关键点坐标,
- 同制作关键点的标签一样,关键点之间的方向需要制作19*2个特征图,如果不同的关键点方向重合,采取相加求平均值,比如一个躯干方向的x值为2.9,另一个躯干方向的x值为3.1,那么在这一个点上的x值为(2.9+3.1)/ 2 = 3,

代码:
def putGaussianMaps(center, accumulate_confid_map, sigma, grid_y, grid_x, stride):
start = stride / 2.0 - 0.5 # 3.5
y_range = [i for i in range(int(grid_y))]
x_range = [i for i in range(int(grid_x))]
xx, yy = np.meshgrid(x_range, y_range)
xx = xx * stride + start
yy = yy * stride + start
d2 = (xx - center[0]) ** 2 + (yy - center[1]) ** 2
exponent = d2 / 2.0 / sigma / sigma
mask = exponent <= 4.6052
cofid_map = np.exp(-exponent)
cofid_map = np.multiply(mask, cofid_map)
accumulate_confid_map += cofid_map # 多个点会叠加的
accumulate_confid_map[accumulate_confid_map > 1.0] = 1.0
return accumulate_confid_map
def putVecMaps(centerA, centerB, accumulate_vec_map, count, grid_y, grid_x, stride):
centerA = centerA.astype(float)
centerB = centerB.astype(float)
thre = 1 # limb width
centerB = centerB / stride # 映射到特征图中
centerA = centerA / stride
limb_vec = centerB - centerA
norm = np.linalg.norm(limb_vec) # 求范数
if norm == 0.0:
# print 'limb is too short, ignore it...'
return accumulate_vec_map, count
limb_vec_unit = limb_vec / norm # 单位向量
# print 'limb unit vector: {}'.format(limb_vec_unit)
# To make sure not beyond the border of this two points
min_x = max(int(round(min(centerA[0], centerB[0]) - thre)), 0) # 得到所有可能区域
max_x = min(int(round(max(centerA[0], centerB[0]) + thre)), grid_x)
min_y = max(int(round(min(centerA[1], centerB[1]) - thre)), 0)
max_y = min(int(round(max(centerA[1], centerB[1]) + thre)), grid_y)
range_x = list(range(int(min_x), int(max_x), 1))
range_y = list(range(int(min_y), int(max_y), 1))
xx, yy = np.meshgrid(range_x, range_y)
ba_x = xx - centerA[0] # the vector from (x,y) to centerA 根据位置判断是否在该区域上(分别得到X和Y方向的)
ba_y = yy - centerA[1]
# 下面2行代码判断特征图上的点是不是在关键点之间的躯干上
limb_width = np.abs(ba_x * limb_vec_unit[1] - ba_y * limb_vec_unit[0]) # 向量叉乘根据阈值选择赋值区域,任何向量与单位向量的叉乘即为四边形的面积
mask = limb_width < thre # mask is 2D # 小于阈值的表示在该区域上
vec_map = np.copy(accumulate_vec_map) * 0.0 # 本次计算
vec_map[yy, xx] = np.repeat(mask[:, :, np.newaxis], 2, axis=2)
vec_map[yy, xx] *= limb_vec_unit[np.newaxis, np.newaxis, :] # 在该区域上的都用对应的方向向量表示(根据mask结果表示是否在)
mask = np.logical_or.reduce(
(np.abs(vec_map[:, :, 0]) > 0, np.abs(vec_map[:, :, 1]) > 0)) # 在特征图中(46*46)中 哪些区域是该躯干所在区域
accumulate_vec_map = np.multiply(
accumulate_vec_map, count[:, :, np.newaxis]) # 每次返回的accumulate_vec_map都是平均值,现在还原成实际值
accumulate_vec_map += vec_map # 加上当前关键点位置形成的向量
count[mask is True] += 1 # 该区域计算次数都+1
mask = count == 0
count[mask is True] = 1 # 没有被计算过的地方就等于自身(因为一会要除法)
accumulate_vec_map = np.divide(accumulate_vec_map, count[:, :, np.newaxis]) # 算平均向量
count[mask is True] = 0 # 还原回去
return accumulate_vec_map, count
def get_ground_truth(self, anns):
grid_y = int(self.input_y / self.stride)
grid_x = int(self.input_x / self.stride)
channels_heat = (self.HEATMAP_COUNT + 1) # 多出一个背景
channels_paf = 2 * len(self.LIMB_IDS) # 2*19,38个特征图表示关键点之间的连接方向
heatmaps = np.zeros((int(grid_y), int(grid_x), channels_heat))
pafs = np.zeros((int(grid_y), int(grid_x), channels_paf))
keypoints = []
for ann in anns:
single_keypoints = np.array(ann['keypoints']).reshape(17, 3)
single_keypoints = self.add_neck(single_keypoints)
keypoints.append(single_keypoints)
keypoints = np.array(keypoints)
keypoints = self.remove_illegal_joint(keypoints)
# confidence maps for body parts
for i in range(self.HEATMAP_COUNT):
joints = [jo[i] for jo in keypoints] # 每一种关节点
for joint in joints: # 遍历每一个点
if joint[2] > 0.5: # 1是标注被遮挡 2是标注且没被遮挡
center = joint[:2] # 点坐标
gaussian_map = heatmaps[:, :, i]
heatmaps[:, :, i] = putGaussianMaps(
center, gaussian_map,
7.0, grid_y, grid_x, self.stride)
# pafs
for i, (k1, k2) in enumerate(self.LIMB_IDS):
# limb
count = np.zeros((int(grid_y), int(grid_x)), dtype=np.uint32) # 表示该位置是否被计算了多次(计算的数量)
for joint in keypoints:
if joint[k1, 2] > 0.5 and joint[k2, 2] > 0.5:
centerA = joint[k1, :2]
centerB = joint[k2, :2]
vec_map = pafs[:, :, 2 * i:2 * (i + 1)] # 每一个躯干位置,选择x和y两个方向
pafs[:, :, 2 * i:2 * (i + 1)], count = putVecMaps(
centerA=centerA,
centerB=centerB,
accumulate_vec_map=vec_map,
count=count, grid_y=grid_y, grid_x=grid_x, stride=self.stride
)
# background
heatmaps[:, :, -1] = np.maximum(
1 - np.max(heatmaps[:, :, :self.HEATMAP_COUNT], axis=2),
0.
)
return heatmaps, pafs
参考:
1、哔站


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









