









这个程序起因来自于我自己的想法。
以前写作文要写满800字,但是符号也占了字数,所以我想统计是否是中文真的写了800字,因此写这个程序
思路:
思路是这样子的,通过文件依次读取,可以获得每一个字节,其中中文是占两个字节的,而中文的ASCII码通常都是负的,因此,可以据此写出统计代码,其中我的中文都是存储在结构体里面的,统计也是通过对结构体进行二重循环做的,牵涉的小技巧有布尔数组定义之类的。。。
txt文件:
源码:
#include <iostream>
#include <fstream>
using namespace std;
struct ch{
char temp[3];
int num;
}C[10000];
bool trek[10000];
int select[10000];
int word[256];
void main(){
char num[10000];
int int_res[300];
int hanzi = 0;
int fuhao = 0;
memset(int_res,0,sizeof(int_res));
memset(trek,true,sizeof(trek));
memset(select,0,sizeof(select));
memset(word,1,sizeof(word));
char char_res[256];
int count = 0,ch_count=0;
fstream f("d:\\郑勇军.txt",ios::in);
if(!f) cout<<"mistake";
while(f>>num[count]&&!f.eof()){
// cout<<num[count]<<' ';
int a = (int)num[count];
if(a>0){
int_res[a]++;
// cout<<int_res[a]<<endl; //输出某位置
}
count++;
}
cout<<endl;
for(int i=0;i<count;i++){ //count代表了字节数
int k = (int)num[i];
if(k>0){
cout<<num[i]<<" "<<int_res[num[i]]<<endl;
fuhao++; //统计符号
}
else{
C[ch_count].temp[0] = num[i];
C[ch_count].temp[1] = num[i+1];
C[ch_count].temp[2] = '\0';
cout<<C[ch_count].temp<<endl;
ch_count++;
i++;
hanzi++;
for(int t=0;t<ch_count;t++){
if(strcmp(C[t].temp,C[ch_count-1].temp)==0 && t!=ch_count-1){
select[t]++;
trek[ch_count-1] = false;
break;
}
else if(t==ch_count-1){
select[ch_count-1]++;
break;
}
}
}
//cout<<i<<" "<<(int)num[i]<<endl;
}
cout<<endl<<endl<<endl;
for(int m=0;m<ch_count;m++){
if(trek[m]){
cout<<C[m].temp<<" "<<select[m]<<endl;
}
}
cout<<endl<<endl<<endl;
cout<<"汉字:"<<hanzi<<" 符号:"<<fuhao<<endl;
cout<<endl<<"字节数:"<<count<<endl; //count代表了字节数
}结果:
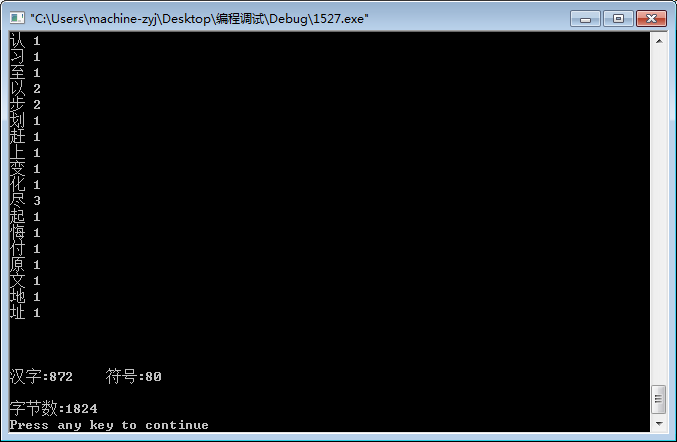
统计出了各种汉字的分布,以及多少,还统计出了字节数以及符号
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









