







想自己做一个 AI 应用,比如聊天机器人、智能问答助手?
那第一步,就是要给你的应用接入一个“大脑”——也就是 大模型。
今天,我就带你手把手实操,教你在 Dify 平台上快速完成模型配置!
小白也能一次学会!
📚 什么是 Dify 模型?为什么要配置?
在 Dify 里,模型就像你应用的大脑,不同模型擅长的领域也不同。常见有这几类:
| 类型 | 简单理解 | 例子 |
|---|---|---|
| 系统推理模型 | 聊天、写文章、问答的主力模型 | OpenAI、Claude、文心一言 |
| Embedding 模型 | 让文档能被“读懂”和向量检索 | OpenAI Embedding、智谱 AI |
| Rerank 模型 | 搜索后重新排序,结果更准 | Cohere、Jina AI |
| 语音转文字模型 | 把语音转成文字 | OpenAI Whisper |
✅ 小结:
-
聊天机器人的话,至少要配置【系统推理模型】。
-
做文档问答,还要加【Embedding模型】。
🛠️ 动手操作!Dify 配置模型全流程
下面开始正式操作啦,一步步超简单:
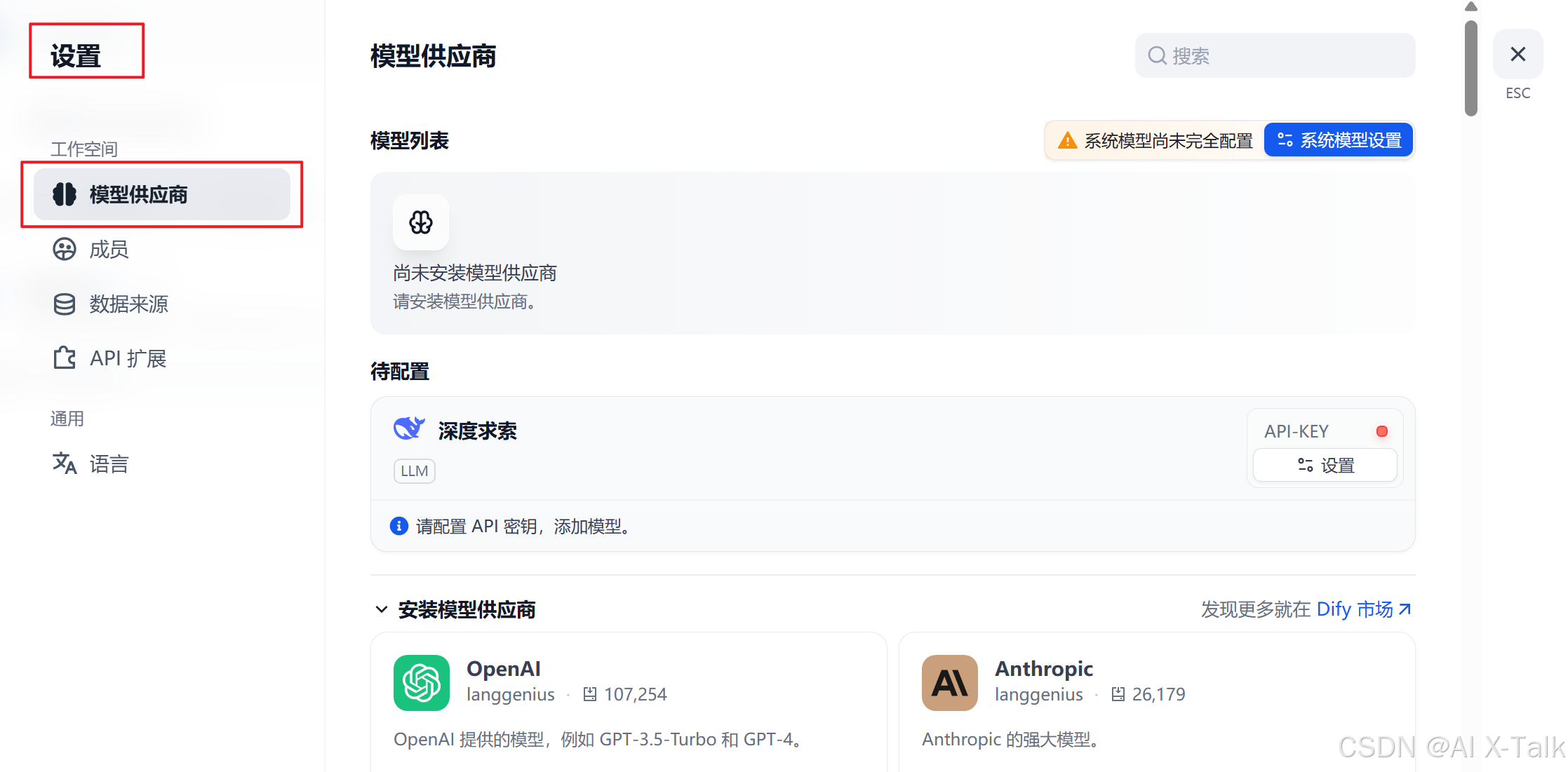
📋 第一步|打开 Dify 后台,进入设置
-
登录你的 Dify 后台,右上角点击【头像】找到 【设置】。
-
左侧菜单栏找到【设置】,点开【模型供应商】。
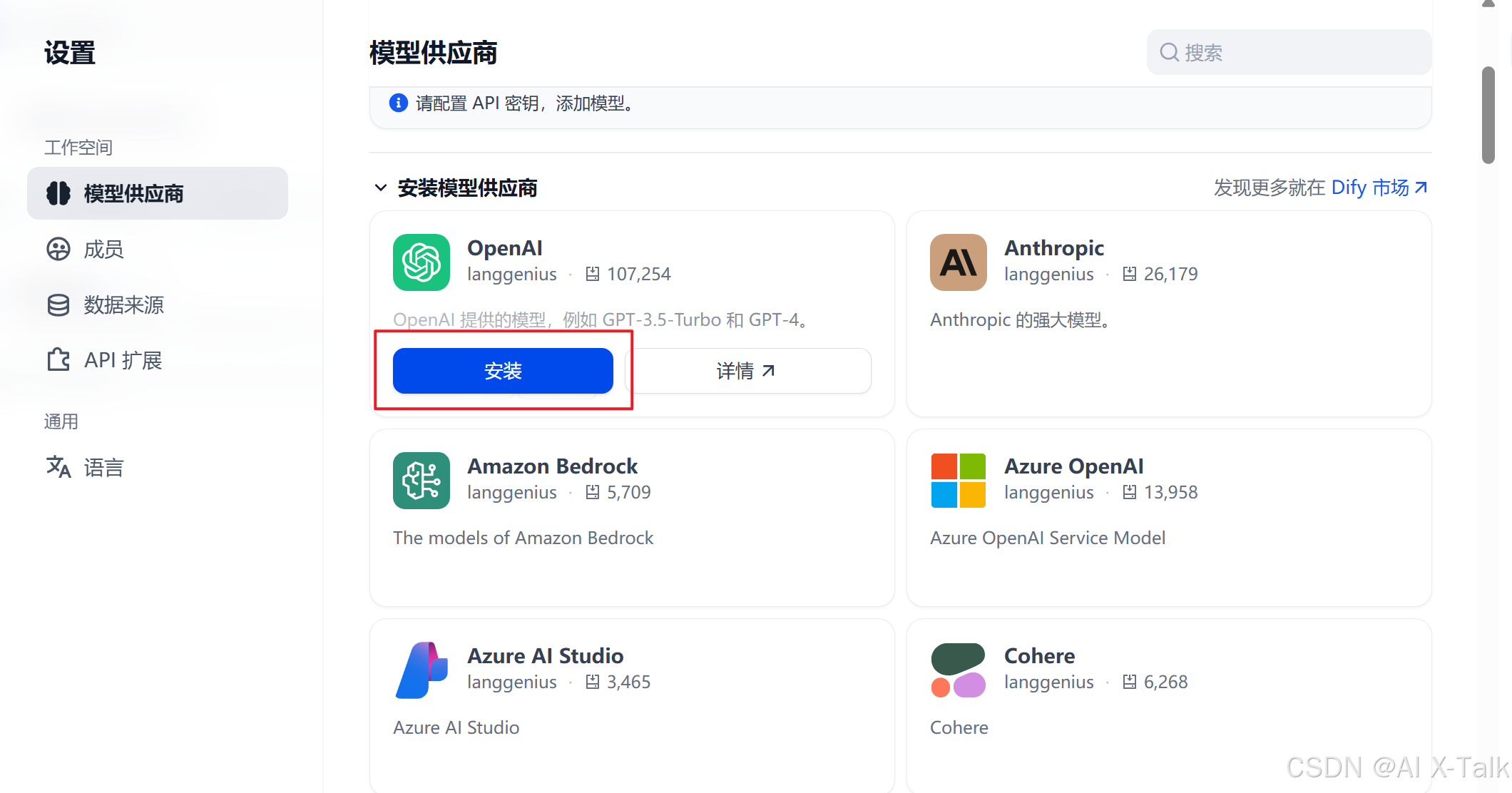
🏢 第二步|选择你要接入的模型平台
Dify 支持超多模型供应商,比如:
-
OpenAI(ChatGPT)
-
Claude(Anthropic 出品)
-
文心一言(百度)
-
星火认知大模型(讯飞)
-
通义千问(阿里)
-
智谱 ChatGLM 等
👀 按自己的需要选择一个,比如我们选择【OpenAI】。
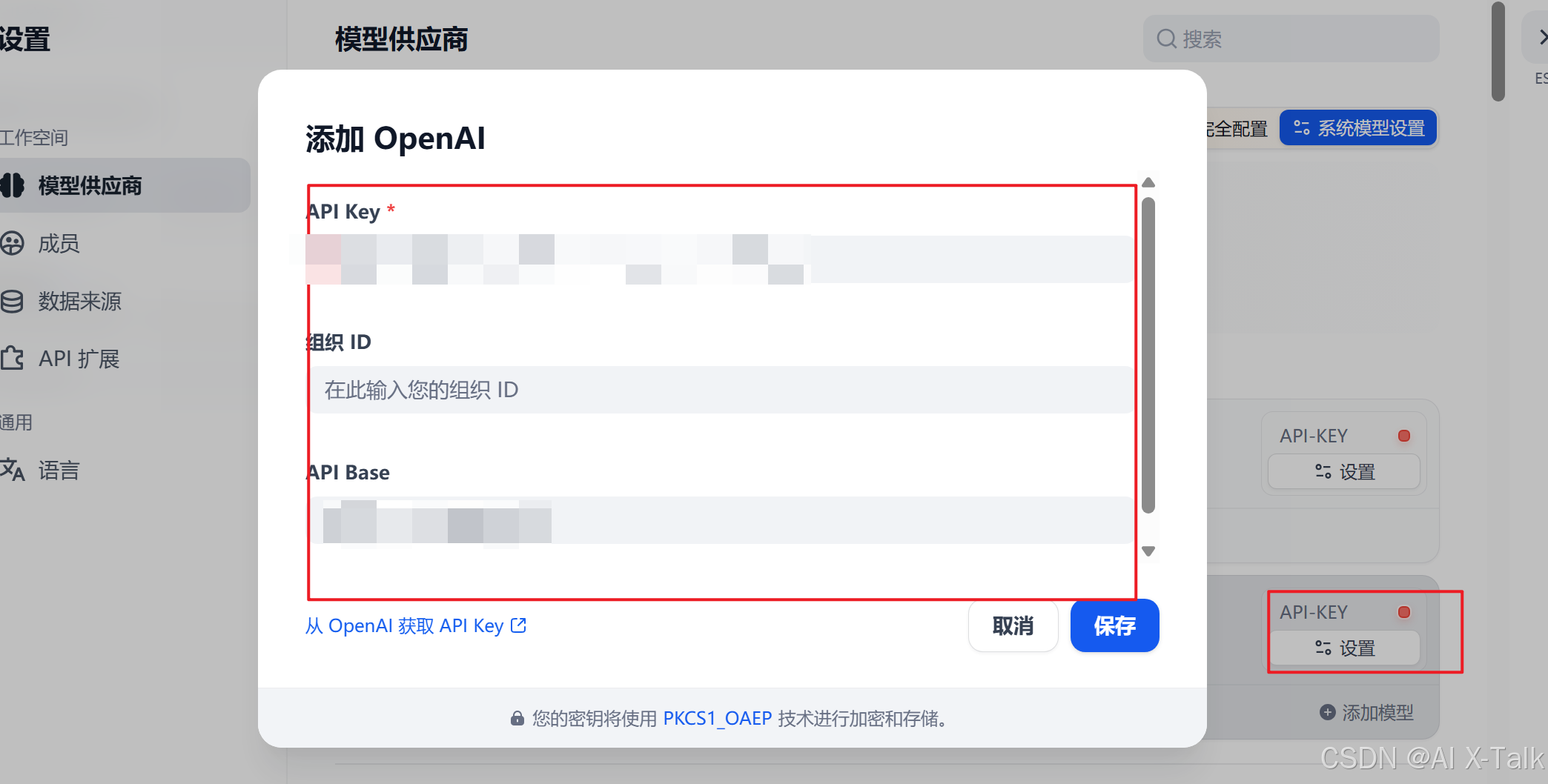
🔑 第三步|填写 API Key
-
每个模型平台都会给你一个 API Key,就像开门的钥匙。
-
直接复制你的 Key,粘贴到对应输入框里。
-
其他选项可以用默认,或者按需要调整。
-
填好后,点击【保存】!
🔒 小提醒:Dify 后台是加密存储 Key 的,不怕泄露,放心用!
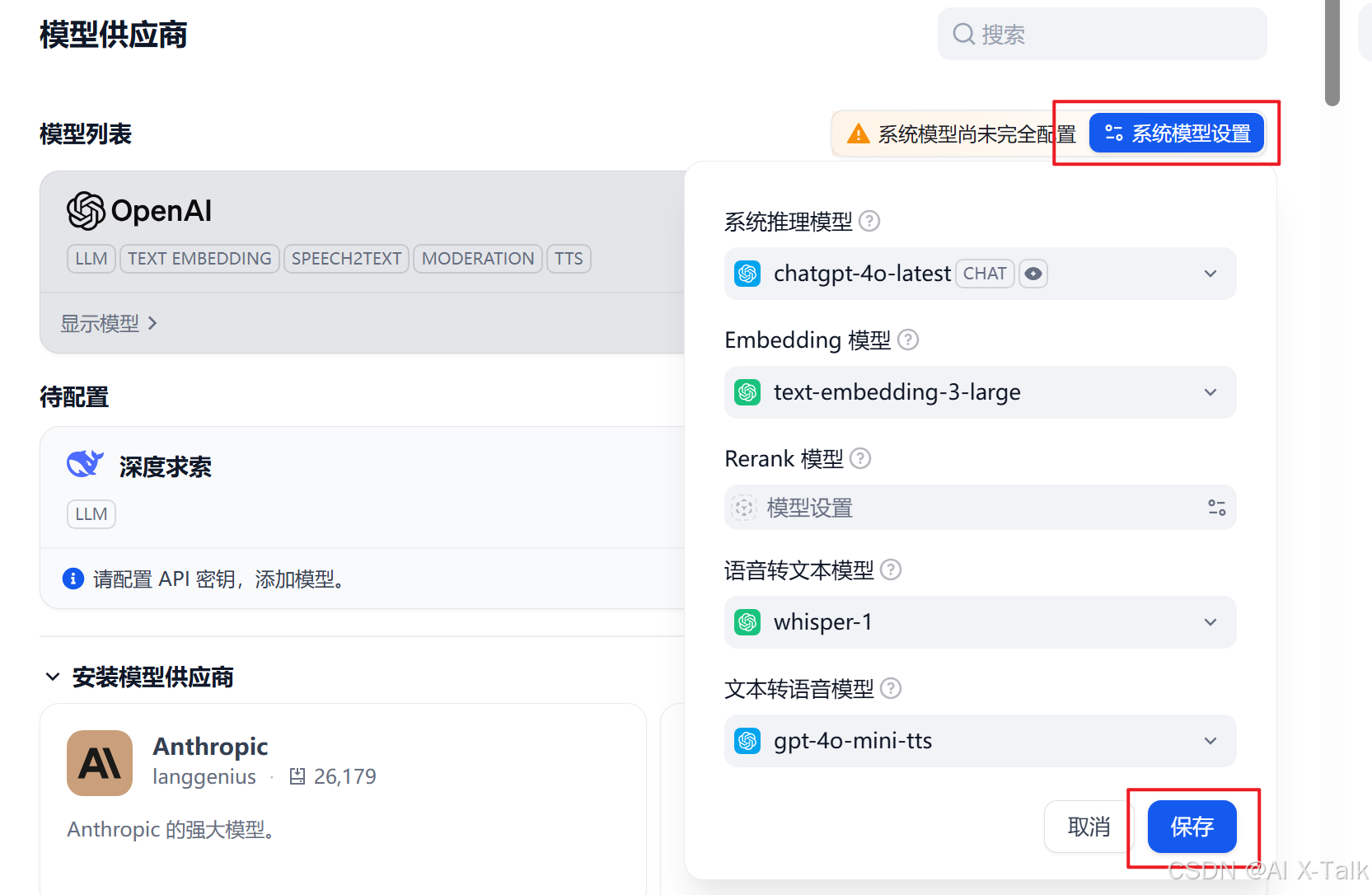
🎯 第四步|配置系统模型!
保存成功后,你就能在模型列表里看到你刚添加的模型啦!
将其设定为系统配置!
🎯 补充:实用小 Tips
Tip 1:可以接多个模型
聊天可以用 OpenAI,搜索可以用 ChatGLM,Dify 支持灵活切换!
Tip 2:不同应用能指定不同默认模型
比如:
-
【客服机器人】默认用 GPT-4
-
【知识库问答】默认用 Claude 3
Tip 3:托管平台也能连
像 HuggingFace、Replicate 上的模型也能接入,操作方法差不多~
✨ 总结一句话
配置 Dify 模型真的超级简单!
选供应商 ➡️ 填 API Key ➡️ 保存 ➡️ 完成
动动手,3分钟就能搞定!
搭建你的 AI 应用,从这里起步,超级轻松!

















 790
790

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









