







pytorch里的LSTM原理:
主要是它的ht-1和xt不是直接拼在一起的。

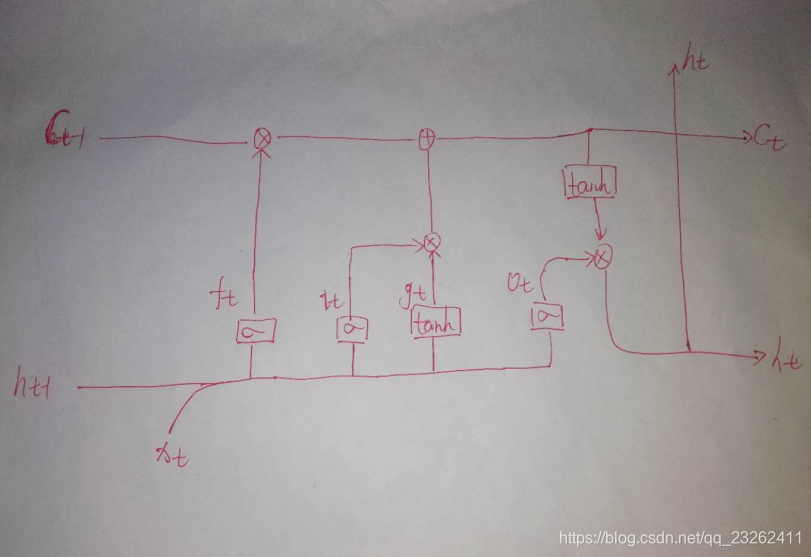

LSTM学习的参数:
.. math::
\begin{array}{ll} \\
i_t = \sigma(W_{ii} x_t + b_{ii} + W_{hi} h_{(t-1)} + b_{hi}) \\
f_t = \sigma(W_{if} x_t + b_{if} + W_{hf} h_{(t-1)} + b_{hf}) \\
g_t = \tanh(W_{ig} x_t + b_{ig} + W_{hg} h_{(t-1)} + b_{hg}) \\
o_t = \sigma(W_{io} x_t + b_{io} + W_{ho} h_{(t-1)} + b_{ho}) \\
c_t = f_t * c_{(t-1)} + i_t * g_t \\
h_t = o_t * \tanh(c_t) \\
\end{array}
Attributes:
weight_ih_l[k] : the learnable input-hidden weights of the :math:`\text{k}^{th}` layer
`(W_ii|W_if|W_ig|W_io)`, of shape `(4*hidden_size, input_size)` for `k = 0`.
Otherwise, the shape is `(4*hidden_size, num_directions * hidden_size)`
weight_hh_l[k] : the learnable hidden-hidden weights of the :math:`\text{k}^{th}` layer
`(W_hi|W_hf|W_hg|W_ho)`, of shape `(4*hidden_size, hidden_size)`
bias_ih_l[k] : the learnable input-hidden bias of the :math:`\text{k}^{th}` layer
`(b_ii|b_if|b_ig|b_io)`, of shape `(4*hidden_size)`
bias_hh_l[k] : the learnable hidden-hidden bias of the :math:`\text{k}^{th}` layer
`(b_hi|b_hf|b_hg|b_ho)`, of shape `(4*hidden_size)`
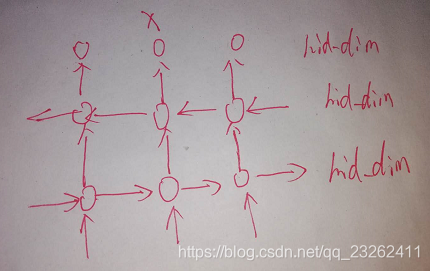
双层LSTM:
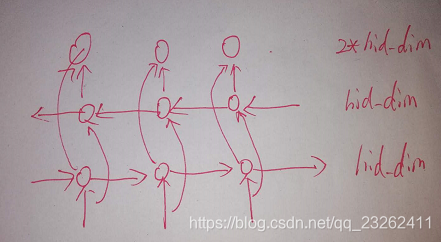
双向LSTM:
双层加双向LSTM:
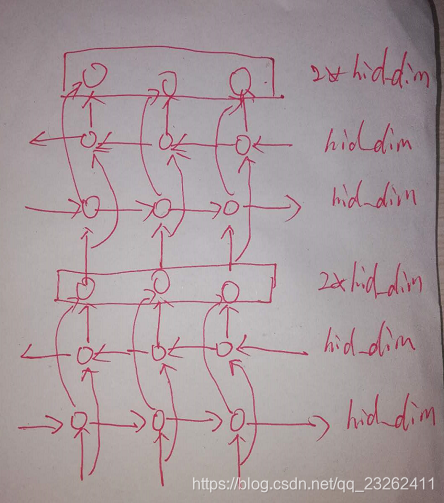
对于LSTM cell内部c,h都是hid_dim维度的。就是说除了和输入x有关的矩阵,其他的矩阵都是hid_dim维度的。
Attributes:
k=0 的层是x直接输入的层,所以在这个层的Wi(和输入有关的矩阵),形状为(4*hidden_size, input_size)。
其他层,比如双向加双层LSTM的网络,第一个双向LSTM的输出维度就是num_directions * hidden_size,所以第二个双向LSTM和输入有关的矩阵维度就是num_directions * hidden_size。
weight_ih_l[k] : the learnable input-hidden weights of the :math:`\text{k}^{th}` layer
`(W_ii|W_if|W_ig|W_io)`, of shape `(4*hidden_size, input_size)` for `k = 0`.
Otherwise, the shape is `(4*hidden_size, num_directions * hidden_size)`
weight_hh_l[k] : the learnable hidden-hidden weights of the :math:`\text{k}^{th}` layer
`(W_hi|W_hf|W_hg|W_ho)`, of shape `(4*hidden_size, hidden_size)`
bias_ih_l[k] : the learnable input-hidden bias of the :math:`\text{k}^{th}` layer
`(b_ii|b_if|b_ig|b_io)`, of shape `(4*hidden_size)`
bias_hh_l[k] : the learnable hidden-hidden bias of the :math:`\text{k}^{th}` layer
LSTM代码实现:
import torch
import torch.nn as nn
from torch.nn import Parameter
from torch.nn import init
from torch import Tensor
import math
class NaiveLSTM(nn.Module):
"""Naive LSTM like nn.LSTM"""
def __init__(self, input_size: int, hidden_size: int):
super(NaiveLSTM, self).__init__()
self.input_size = input_size
self.hidden_size = hidden_size
# input gate
self.w_ii = Parameter(Tensor(hidden_size, input_size))
self.w_hi = Parameter(Tensor(hidden_size, hidden_size))
self.b_ii = Parameter(Tensor(hidden_size, 1))
self.b_hi = Parameter(Tensor(hidden_size, 1))
# forget gate
self.w_if = Parameter(Tensor(hidden_size, input_size))
self.w_hf = Parameter(Tensor(hidden_size, hidden_size))
self.b_if = Parameter(Tensor(hidden_size, 1))
self.b_hf = Parameter(Tensor(hidden_size, 1))
# output gate
self.w_io = Parameter(Tensor(hidden_size, input_size))
self.w_ho = Parameter(Tensor(hidden_size, hidden_size))
self.b_io = Parameter(Tensor(hidden_size, 1))
self.b_ho = Parameter(Tensor(hidden_size, 1))
# cell
self.w_ig = Parameter(Tensor(hidden_size, input_size))
self.w_hg = Parameter(Tensor(hidden_size, hidden_size))
self.b_ig = Parameter(Tensor(hidden_size, 1))
self.b_hg = Parameter(Tensor(hidden_size, 1))
self.reset_weigths()
def reset_weigths(self):
"""reset weights
"""
stdv = 1.0 / math.sqrt(self.hidden_size)
for weight in self.parameters():
init.uniform_(weight, -stdv, stdv)
def forward(self, inputs: Tensor, state: Tuple[Tensor]) \
-> Tuple[Tensor, Tuple[Tensor, Tensor]]:
"""Forward
Args:
inputs: [1, 1, input_size]
state: ([1, 1, hidden_size], [1, 1, hidden_size])
"""
# seq_size, batch_size, _ = inputs.size()
if state is None:
h_t = torch.zeros(1, self.hidden_size).t()
c_t = torch.zeros(1, self.hidden_size).t()
else:
(h, c) = state
h_t = h.squeeze(0).t()
c_t = c.squeeze(0).t()
hidden_seq = []
seq_size = 1
for t in range(seq_size):
x = inputs[:, t, :].t()
# input gate
i = torch.sigmoid(self.w_ii @ x + self.b_ii + self.w_hi @ h_t +
self.b_hi)
# forget gate
f = torch.sigmoid(self.w_if @ x + self.b_if + self.w_hf @ h_t +
self.b_hf)
# cell
g = torch.tanh(self.w_ig @ x + self.b_ig + self.w_hg @ h_t
+ self.b_hg)
# output gate
o = torch.sigmoid(self.w_io @ x + self.b_io + self.w_ho @ h_t +
self.b_ho)
c_next = f * c_t + i * g
h_next = o * torch.tanh(c_next)
c_next_t = c_next.t().unsqueeze(0)
h_next_t = h_next.t().unsqueeze(0)
hidden_seq.append(h_next_t)
hidden_seq = torch.cat(hidden_seq, dim=0)
return hidden_seq, (h_next_t, c_next_t)
def reset_weigths(model):
"""reset weights
"""
for weight in model.parameters():
init.constant_(weight, 0.5)
### test
inputs = torch.ones(1, 1, 10)
h0 = torch.ones(1, 1, 20)
c0 = torch.ones(1, 1, 20)
print(h0.shape, h0)
print(c0.shape, c0)
print(inputs.shape, inputs)
# test naive_lstm with input_size=10, hidden_size=20
naive_lstm = NaiveLSTM(10, 20)
reset_weigths(naive_lstm)
output1, (hn1, cn1) = naive_lstm(inputs, (h0, c0))
print(hn1.shape, cn1.shape, output1.shape)
print(hn1)
print(cn1)
print(output1)
out:














 1164
1164











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









