







cache相关概念及工作原理介绍
笔者这篇文章主要从使用者的角度介绍cache的相关概念和工作原理。
一. cache是什么,为什么要用它
关于cache是什么,为什么要用它。我们从这个表格说起。下图是典型的memory大小和访问时间
| memory类型 | 典型大小 | 典型的访问时间(周期) |
|---|---|---|
| 寄存器(r0-r15等) | 128B | 1 |
| L1 cache | 32KB | 1~2 |
| L2 cache | 256KB | 8 |
| DDR等主memory | MB | 30~100 |
| flash等掉电存储 | MB~GB | >500 |
从上表可以明显的看出,cpu在访问主存(SDRAM、DDR等memory)时,由于主存的读写速度较慢,严重影响了cpu的执行效率。所以便在主存与cpu之间加了读写速度较快的cache.用它来缓存住存的部分内容,以提高cpu的执行效率。(如果有人问为啥不直接提高主存的访问速度,其实这就是谈钱伤感情的事了–成本太高)。
高速缓冲存储器cache是一种容量小、速度快的缓存。计算机程序执行不是随机的,它在执行过程中会频繁的运行小范围的循环代码,这些循环代码会对存储器中的局部区域反复的访问。cache的作用就是在cpu第一次访问存储器时,将相关的数据和程序指令加载到cache中,使随后的访问速度大大提高。
二. cache的分类
cache按放置在MMU的前后位置分为:
逻辑cache:它位于MMU之前。处理器直接通过逻辑地址访问cache的数据。典型代表为ARM7-ARM10.物理cache:它位于MMU之后。处理器先通过MMU将逻辑地址转为物理地址,然后通过物理地址访问cache的数据。典型代表为ARMv7结构的处理器。当然如果处理器没有MMU,那它肯定就是物理cache.
下图是逻辑cache与物理cache关系图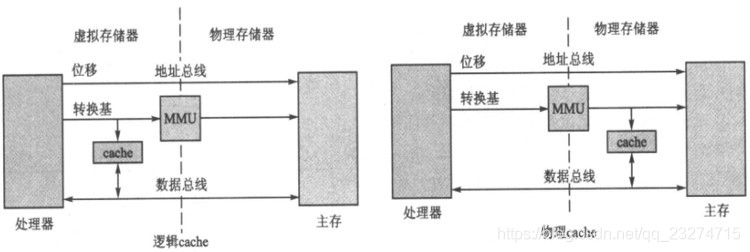
对于哈佛总线结构的处理器,数据和指令总线分离,所以存在两种cache:指令cache(I-cache)和数据cache(D-cache).
当然,在L1 chache(一级cache)中一般是分离的,而在二级cache中使用混合cache.
对于冯-诺依曼总线结构,由于数据和指令共用总线,所以只存在混合cache。
三. cache结构
下图是最简单的cache结构图: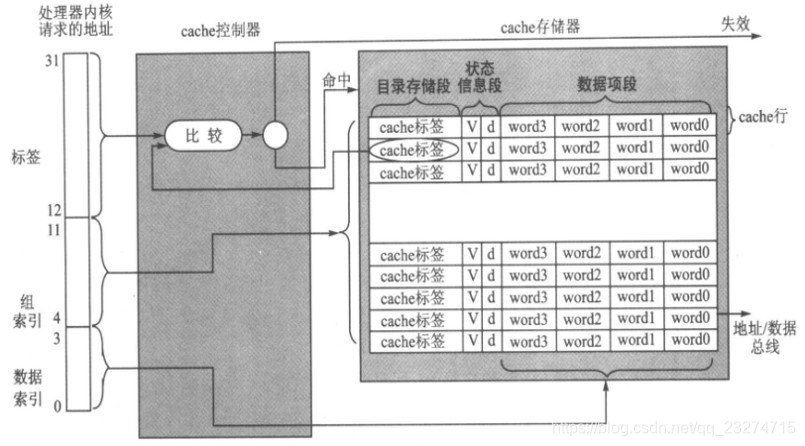
根据cache的结构,将其分为下面几个部分:
cache存储器:它由n个cache行组成,每个cache行都有下面3个部分组成:目录存储段(directory store):cache使用目录存储段来记录当前行对应主存中的位置。也就是我们常说的cache标签(cache-tag).数据项段(data section):此段就是用来缓存主存内容的。我们通常所说的32K的cache指的就是数据项段的大小。状态信息段(status infomation):用来记录数据项段的状态信息。常见的状态位有有效位(valid bit):标记当前cache行内容是最初从主存中获取到的数据,可以为cpu使用。脏位(dirty bit):标记cache行的内容与主存中相应的内容是否一致。
cache控制器:它根据cpu的读写命令自动完成查找、缓存等工作。它将cpu的访问地址分为了下面3个部分:标签域(tag field):用来与目录存储段比较,查找此地址中的内容是否在cache中存在.组索引域(set index filed):当命中时,用来定位命中(hit)在具体的那一cache行上。数据索引域(data index field):当命中时,用来定位命中在具体中行的哪个字节里。
四. cache的基本工作原理
先明确一些概念:
- 通常所说的32K的cache指的就是cache存储器
数据项段的大小。 - cache的行由多个字节组成,常见的有16字节、32字节等。
- 对于32K、行大小16字节的cache,那么它就拥有32K/16=256个行。
cpu(32bit)发送读/写内存的请求后,会被cache控制器截获。cache控制器根据截获的请求地址,将其分为标签域、组索引域、数据索引域。然后做了三部分工作:
- 将控制器
标签域的值与存储器目录存储段cache-tag比较.查看是否有相应的存在:- 如果存在,首先通过
组索引域确定具体的cache行(cache line)。然后根据标签域中的状态位确定行是否有效.有效则为命中(hit).则为失效(miss).命中后,再根据数据索引域确定cache行中的具体字,进行对应的读/写操作(具体的写操作由写策略决定)。 - 如果不存在,则为失效(miss).失效后控制器从主存中拷贝整个cache行的数据到存储器的某个cache行中(具体选择哪个行是
替换策略决定,何时进行替换由分配策略决定。后面会介绍这几种策略)。
- 如果存在,首先通过
五. cache工作时用到的相关策略
- 写策略:决定处理器执行写操作时数据存放的位置。
直写法:cache命中写请求地址时,将同时修改cache和主存中地址对应的内容,以确保cache和主存数据的一致性。回写法(writeback):cache命中写请求地址时,只修改cache中的数据(此cache行的状态信息段的脏位将置1),而不立即修改主存相应地址的内容。当将这个带脏位的cache行替换出cache时,此数据会自动写到主存中。
替换策略:当cache访问失效时,需要从cache存储器踢出某个cache行来缓存新的要访问的数据。关于如何确定这个要被踢出cache行(丢弃者 victim)))就是替换策略要做的事。轮询法(Round Robin):又称循环替换法。伪随机替换法:从特定位置上随机的选出一行替换出去。
分配策略:cache未命中时,决定cache控制器何时分配cache行。读操作分配(read-allocate):如果cache未命中,只有进行存储器读操作时,才分配cache行。如果是写操作未命中,直接更新主存中的内容。读/写操作分配(read-write-allocate):读操作/写操作cache未命中时,都分配cache行。
六. 清除和清理cache
flush(清除):清除就是使cache中的缓存数据作废(invalidate)。clean(清理):把脏的数据写入到主存中。cache行中的脏位将被清除。清理cache操作可以重健cache和主存之间的数据一致性。此操作仅使用于回写策略的D-cache.
七. cache与主存之间的映射关系
上面一直说,cache的作用是缓存主存中的内容。但cache到底是如何缓存的了。也就是说,它和主存之间总有一定的映射关系吧。
其实,它们之间的映射关系非常简单。由于主存远大于cache的大小,所以它们之间的映射关系是一对多的。也就是一个cache的cache行对应多个主存的地址。下面将通过直接映射的方式介绍它们的映射关系。
1. 直接映射
用一个例子讲述直接映射:
现有一个总大小为4KB,行大小为16字节的cache与内存大小为512M的映射关系。此处假设内存在控制器的起始地址为0x20000000.cpu为32位的cpu处理器。
首先计算32bit地址在标签域、组索引域、数据索引域所占的bit位。(32位处理器是按字(4字节对齐)为单位访问数据的)
- 因为行大小为16字节=16/4=4word.所以
数据索引域为4bit([3:0]).用来指定行中第的0~3个字。 - cache共有4kB/16byte=256个cache行.所以
组索引域为8bit([11:4]).用来指定第0~255行中的具体行。 - 剩下的20bit([31:12])为
标签域.也就是说共有2^20个主存地址对应一个cache行。根据标签域来匹配确定具体对应的哪一个地址。
根据上面的规划我们可以推出:主存地址0x20000010、0x20010010、0x20020010、…、0x3FFFF010被映射到了cache的第1行。以此内推,cache的第100(0x64)行对应主存地址的0x20000640、0x20010640、0x20020640、…、0x3FFFF640。
提一个问题:主存地址的0x20000320能映射到cache的第1行吗?第2行了?答案是否定的。他只能映射到cache的第50(0x32)行.因为主存地址的组索引域[11:4]bit决定缓存在cache的第几行。
下面是对应关系图: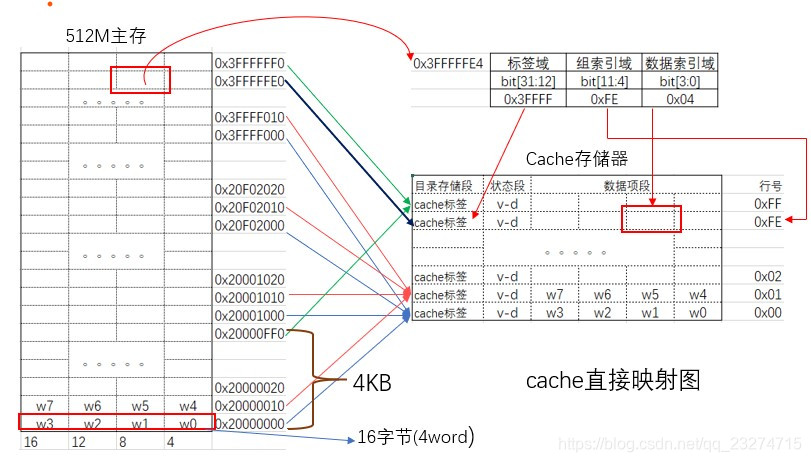
直接映射的缺点
上面的问题也引出了一个问题:如果一个函数A_fun()程序的起始地址在0x20000010,函数B_fun()程序的起始地址在0x20010010(这两个地址只能映射到同一cache行),而在程序中连续调用它俩。如:
while(1){
A_fun();
B_fun();
}那么cache的此行就会被频繁的替换。从而使程序的性能大幅度下降(这就是直接映射的颠簸(thrashing)问题)。为解决这个问题,提出了下面要说的组相联映射。
2. 组相联映射
为了减少cache的颠簸频率,提出了路(way)的概念:将cache存储器分成多个容量相同的小单元。每个小单元为一个路(way)。
加入路(way)后,cache的包含关系为:
- cache存储器包含W个路
- 每个路中又包含L个行
- 每个行里面又包含N个字节。
组相联cache特点在组相联cache中,主存中的一个地址可以映射到cache的任意一路(注意:同一时刻,主存的地址只能映射到某一路。也就是说,同样的地址不能被重复的放在其他路).
用一个例子讲述组相联映射:
现有一个总大小为4KB,4路,行大小为16字节的cache与内存大小为512M的映射关系。此处假设内存在控制器的起始地址为0x20000000.cpu为32位的cpu处理器。
首先计算32bit地址在标签域、组索引域、数据索引域所占的bit位。(32位处理器是按字(4字节对齐)为单位访问数据的)
- 因为行大小为16字节=16/4=4word.所以
数据索引域为4bit([3:0]).用来指定行中第的0~3个字。 - cache共有4kB/4way/16byte=64个cache行.所以
组索引域为6bit([9:4]).用来指定第0~63行中的具体行。 - 剩下的22bit([31:10])为
标签域.也就是说共有2^22个主存地址对应一个cache行。根据标签域来匹配确定具体对应的哪一个地址。
根据上面的规划我们可以推出:主存地址0x20000010、0x20010010、0x20020010、…、0x3FFFFC10被映射到了cache的x路的第1行(x代表0~3的任意一路)。以此内推,cache
提2个问题:
- 主存地址的0x20000320能映射到cache的第1行吗?第2行了?答案是否定的。他只能映射到cache的第50(0x32)行.因为主存地址的
组索引域[9:4]bit决定缓存在cache的第几行。 - 主存地址的0x20000010被映射到cache的第一路第1行。哪么主存地址的0x20010010能被映射到cache的第2路第1行吗?
答案是肯定能映射到。这也就是组相联映射映射能大大降低了cache的颠簸频率的原因。
下面是对应关系图: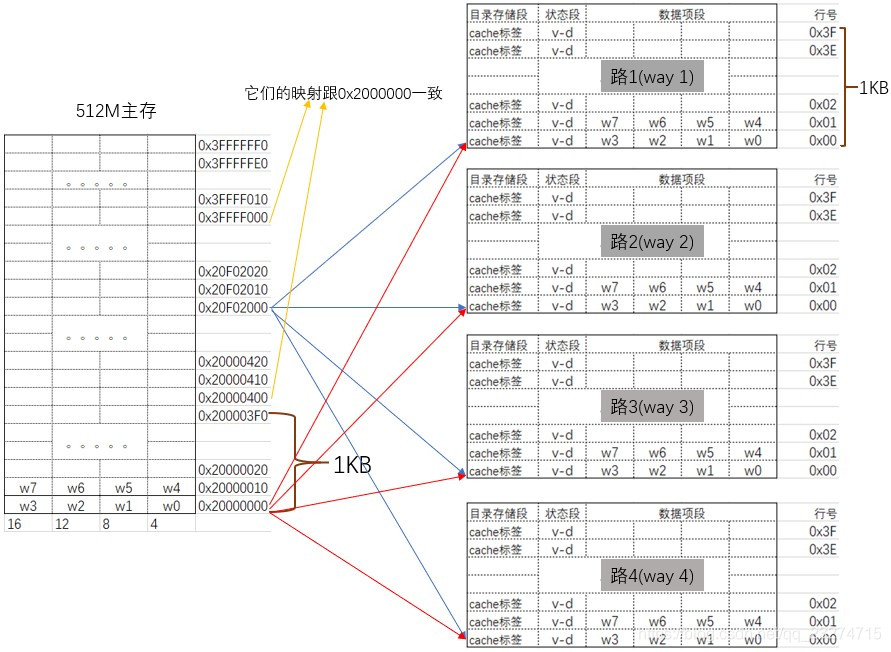
总结
终于写完了,关机睡觉。
参考资料
关于技术交流
此处后的文字已经和题目内容无关,可以不看。
qq群:825695030
微信公众号:嵌入式的日常
如果上面的文章对你有用,欢迎打赏、点赞、评论。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











