







1. 神经元与激活函数
- 神经元:下图有d个输入,我们可以认为当d是净输入的时候,d就是神经元的输入,让净输入加权求和并加上偏执项,并最终求和,得到一个输出,将这个输出作为激活函数的输入,其会对加权和再做一次运算最后输出a。这就是一个典型的神经元。

- 激活函数:对于上图右部分即激活函数,其主要作用就是加强网络的表达能力,还有学习能力。我们要求激活函数是:
1. 连续的,可以允许个别点不可导,但绝大多数都是可导的,并且是非线性的。这样的函数是可以让参数是可学习的
2. 我们还希望激活函数是尽可能简单。
3. 还希望激活函数的治愈是在一个比较小的区间内。
常用的激活函数有:
- Sigmoid:是一个s型的函数,两端是饱和的,即在负无穷和正无穷的时候,导数都趋近于0
- logistics:下图红色的曲线,值域在(0,1)间。可以看成一个挤压的函数,不管输入是多少,我都可以把区间挤压到(0,1)之间,当x趋近于0的时候,基本都是一个线性,导数是很明显的。可以看成是一个软性门(softGATE),控制输入的量。
- tanh:黑色虚线,值域在(-1,1)之间。是0中心化的。非0中心化的输出会使得其后一层神经元的输入发生偏移,会导致收敛速度降低。

ReLU神经元:
 好处:
好处:
- 只采用加乘的计算,使得训练过程变得简单。计算更加高效。
- 单侧抑制,款兴奋边界。
- 因为样本中往往只有较少的是有用的,而ReLU是一个稀疏的网络,只让少数神经元起作用。
- 在一定程度上缓解了梯度消失的问题。
坏处:因为稀疏性,也会使某些神经元死亡,不再起作用,就会误杀。因此有很多优化版本
2. 全连接神经网络(前馈神经网络/多层感知器)介绍
前馈神经网络:各神经元分别属于不同的层,层内无连接。而是层与层之间的连接。整个网络无反馈,信号从输入层向输出层单向传播。
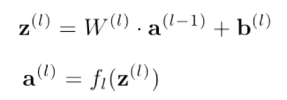
他的信息是单向的,经过每层网络提取不同的特征,最终的到结果。
通用近似定理:因为前馈神经网络具有很强的拟合能力。只要至少有一个隐藏层,一些常见的连续的非线性函数都可以使用前馈神经网络近似。

将通用近似定理应用到机器学习上,神经网络就可以当做一个万能函数来使用,可以用来进行复杂的特征转换,或逼近一个复杂的条件分布。

每一个函数f都是可以进行一个特征转换,直到最后经过分类器g。最后得到我们需要的参数。他们都可以作为激活函数。中间的激活函数一般用ReLU。
3. 反向传播算法
先说训练参数的方法,再先就是确定损失函数。

其中![]() 是一个正则化项。是一个F范数,是用来减轻过拟合的。F范数是矩阵范数的一种,他是矩阵元素绝对值平方和再开方。
是一个正则化项。是一个F范数,是用来减轻过拟合的。F范数是矩阵范数的一种,他是矩阵元素绝对值平方和再开方。
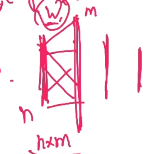
加入上图是一个神经网络,第一层有n个神经元,第二层有m层神经元。则这两层间的W有n*w个。第三个又有多少神经元……从最左到最优,所有的W就会组成一个矩阵,对于这个矩阵,我们可以用F范数作为他的正则化项。 是一个正超参数,当他越大,W越接近于0。
在定义了损失函数后,我们就可以通过梯度下降法来优化参数。
当有l层时,我们需要对每一层的W都有一个更新。

用链式法则逐一的对参数求导是很低效率的。可以采用反向传播算法来高效的实现求导。
链式法则:

反向传播也是在链式法则的基础上实现的。

假如现在的神经网络是上图这样,当我们按照 ![]() 经过一层输入层,再经过隐藏层进行正向传播后,我们就可以开始反向传播了。
经过一层输入层,再经过隐藏层进行正向传播后,我们就可以开始反向传播了。
设总体的误差为两个神经元的和。Et = E1 + E2。分别算出两个神经元的误差后,得出总体的误差。
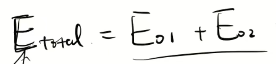



反向传播算法看了很多网课,我也很难了解本质。之后再总结。
4. 自动梯度计算
1. 在进行数值微分的时候,为了减少舍入的误差。将deta x 扩大为两倍。

2. 符号微分:先化简再求导。
3. 自动微分:利用链式法则自动计算复合函数的梯度。
比如把公式转为图的形式解释:
公式: 


如果一个参数有多条路径,则要把每个路径相加。

因为输入到输出过程中,维度可能增加也可能减少,当减少时,适合反向传播,增加则适合正向传播,我们一般都是减少为维度的过程,因此一般都是用反向传播。
5. Himmelblau函数求极小值(实战)
import tensorflow as tf
import numpy as np
import matplotlib.pyplot as plt
from mpl_toolkits.mplot3d import Axes3D
from matplotlib import cm
def himmelblau(x):
# x : [x[0],x[1]]
return (x[0]**2 + x[1] - 11)**2 + (x[0]+x[1]**2 - 7)**2
x = np.arange(-6,6,0.1)
y = np.arange(-6,6,0.1)
x.shape,y.shape
X,Y = np.meshgrid(x,y) #形成坐标矩阵
Z = himmelblau([X,Y])
Z
fig = plt.figure('himmelblau')
ax = fig.gca(projection='3d')
ax.plot_surface(X,Y,Z)
ax.view_init(60,30)
plt.show()
# 参数初始化
x = tf.constant([4.,0.0])
lr = 0.01
for t in range(100):
with tf.GradientTape() as tape:
tape.watch(x)
y = himmelblau(x)
grads = tape.gradient(y,x)
x = x - lr*grads
x,y6. 全连接神经网络MNIST分类(实战)
建立了三层网络模型,输入层784个神经元,第一个隐藏层256个神经元,第二个隐藏层128个神经元,输出层10。标签通过one-hot编码,转变为一个向量。
权重和偏执的维度:

完整代码:
import tensorflow as tf
import matplotlib.pyplot as plt
tf.__version__
#输入层 h0 784
# w1
#隐藏层 h1 256
# w2
#隐藏层 h2 128
# w3
#输出层 h3 10
# 初始化参数
w1 = tf.Variable(tf.random.truncated_normal([784,256] , stddev = 0.1) ) #truncated_normal 有截断的正态分布
w2 = tf.Variable(tf.random.truncated_normal([256,128] , stddev = 0.1))
w3 = tf.Variable(tf.random.truncated_normal([128,10] , stddev = 0.1))
b1 = tf.Variable(tf.zeros([256]))
b2 = tf.Variable(tf.zeros([128]))
b3 = tf.Variable(tf.zeros([10]))
b1.shape
(x_train, y_train), (x_test, y_test) = tf.keras.datasets.mnist.load_data()
x_train.shape , y_train.shape , x_test.shape , y_test.shape
#x值都是0-255之间的,我们想让他先变为0到1之间。并且想数据类型为浮点数。
x_train = tf.convert_to_tensor(x_train , dtype = tf.float32)/255.
y_train = tf.convert_to_tensor(y_train,dtype=tf.int32)
# 把训练集拉平,并且转换为tensor类型。
x_train = tf.reshape( x_train ,[-1,784] )
max(x_train[0])
# h1: net(z = wx+b ) out1( ReLU(z) )
# [60000,784]@[784,256] + [256]
net1 = x_train@w1 + tf.broadcast_to(b1 , [x_train.shape[0],256])
# net1是输入层的输出,其作为输入再次进入第一个隐藏层的特征
out1 = tf.nn.relu(net1)
# [60000,256]@[256,128] + [128]
net2 = out1@w2 + b2
out2 = tf.nn.relu(net2)
# [60000,128]@[128,10] + [10]
net3 = out2@w3 + b3
out3 = tf.nn.softmax(net3)
y_train = tf.one_hot(y_train,depth=10)
loss = tf.nn.softmax_cross_entropy_with_logits(labels = y_train,logits = out3)
loss
#原本是在每个值上做了个对比,我们想求出一个平均
loss = tf.reduce_mean(loss)
loss
with tf.GradientTape() as tape:
tape.watch([w1,b1,w2,b2,w3,b3])
out1 = tf.nn.relu(x_train@w1 + b1)
out2 = tf.nn.relu(out1@w2 + b2)
out3 = tf.nn.softmax(out2@w3 + b3)
loss = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(labels = y_train,logits = out3))
grads = tape.gradient(loss , [w1,b1,w2,b2,w3,b3])
lost_list = []
lr = 0.1
#更新参数
#w = w - lr*grads
w1.assign_sub(lr*grads[0])
b1.assign_sub(lr*grads[1])
w2.assign_sub(lr*grads[2])
b2.assign_sub(lr*grads[3])
w3.assign_sub(lr*grads[4])
b3.assign_sub(lr*grads[5])
for step in range(3000):
with tf.GradientTape() as tape:
tape.watch([w1,b1,w2,b2,w3,b3])
out1 = tf.nn.relu(x_train@w1 + b1)
out2 = tf.nn.relu(out1@w2 + b2)
out3 = tf.nn.softmax(out2@w3 + b3)
loss = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(labels = y_train,logits = out3))
grads = tape.gradient(loss , [w1,b1,w2,b2,w3,b3])
#更新梯度
w1.assign_sub(lr*grads[0])
b1.assign_sub(lr*grads[1])
w2.assign_sub(lr*grads[2])
b2.assign_sub(lr*grads[3])
w3.assign_sub(lr*grads[4])
b3.assign_sub(lr*grads[5])
#输出
lost_list.append(loss)
if step % 100 == 1:
print(step ,"loss: ",float(loss))
plt.plot(lost_list)
x_test = tf.convert_to_tensor(x_test , dtype=tf.float32)/255
y_test = tf.convert_to_tensor(y_test , dtype=tf.int32)
x_test = tf.reshape(x_test , [-1,784])
out1 = tf.nn.relu(x_test@w1 + b1)
out2 = tf.nn.relu(out1@w2 + b2)
out3 = tf.nn.softmax(out2@w3 + b3)
y_predict = tf.math.argmax(out3,axis=-1)
y_predict = tf.cast(y_test,tf.int32)
result = tf.equal(y_predict,y_test)
result = tf.cast(result , dtype=tf.int32)
true_sum = tf.reduce_sum(result)
accuracy = true_sum/len(y_test)
accuracy最后在测试集上的正确率为 100%。注意此代码用的是批量随机梯下降法。
因此计算速度偏低
可以使用小批量随机梯度下降法
在tensorflow中有专门的batch方式
# batch_size
batchDataset = tf.data.Dataset.from_tensor_slices((x_train , y_train)).batch(128)
train_iter = iter(batchDataset)
sample = next(train_iter) #取值
sample[0].shape, sample[1].shape













 1598
1598











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









