









欢迎关注微信公众号:ByteRaccoon、知乎:一只大狸花啊、稀土掘金:浣熊say,分享更多原创技术内容~
Kafka消息传输保障3个层级
Kafka和其它的消息中间件的消息传输保障都分为三个层级,At Most Once、At Least Once、Exactly Once)以及 Kafka 在实现这些语义上的一些机制。下面我对您的陈述进行进一步的解释和澄清:
-
At Most Once (最多一次):消息可能会丢失,但不会重复,消息生产者发送消息,但不确保消息是否成功到达,因此可能会发生消息丢失的情况。
-
At Least Once (最少一次):这消息绝不会丢失,但可能会重复。在 Kafka 中,生产者使用 ACK 机制确保消息至少传递一次。即使生产者收到了部分的 ACK,它也可能会重新发送消息,导致消息可能被消费者多次处理。
-
Exactly Once (恰好一次):消息传输保障,确保每条消息都会被传输一次且仅传输一次。对于 Kafka 生产者,确保消息的 ACK 机制配合幂等性和事务特性,以实现精确一次处理的语义。
At Most Once (最多一次)语义无需任何额外配置,生产者在无ACK的机制下保证消息最多发送一次,因此消息可能存在丢失的情况
At Least Once (最少一次) 语义可以由Kafka 生产者的 ACK 机制确保消息至少一次地被传递。这种机制确保了消息至少传递一次,但可能导致消息重复。
Exactly Once (恰好一次) 语义则由Kafka的幂等性和事务性来保障,以实现精确一次处理的语义。生产者的幂等性确保相同消息的多次发送不会导致数据不一致,而事务机制提供了端到端的一次语义,确保消息要么全部成功,要么全部失败。
什么是Kafka的事务机制?
Kafka 的事务机制是一种保证消息系统中一组相关操作要么全部成功,要么全部失败的机制。它其实类似于分布式事务的概念,旨在提供端到端的一次语义(End-to-End Exactly-Once Semantics),确保消息在传输过程中不会被重复、丢失或不一致。
具体体现在当生产者发送一组消息时,可以随时决定是否要撤回这段消息,而被撤回的消息消费者那边也不能消费到该消息。以下是 Kafka 的事务机制的关键要点:
-
Transactional Producer(事务性生产者): Kafka 提供了事务性的生产者,它允许将一组消息作为一个事务进行发送。生产者可以将消息事务性地写入多个 topic 和 partition。
-
Transactional Consumer(事务性消费者): 在事务性的场景中,通常会有相应的事务性消费者,用于以事务性的方式读取和处理生产者发送的消息。这确保了消息的原子性。
-
Exactly-Once Semantics(一次且仅一次语义): Kafka 的事务机制旨在提供一次且仅一次的语义,确保消息在整个传输过程中要么全部成功,要么全部失败。这包括消息的生产、传输、和消费阶段。
-
Atomic Multi-Partition Writes(原子多分区写入): 事务机制允许将消息原子性地写入多个 topic 的多个 partition,确保在同一个事务中的所有消息要么全部成功写入,要么全部回滚。
-
Idempotent Producer(幂等生产者): 事务机制在底层依赖于幂等生产者。生产者的幂等性确保相同的消息在被重复发送时不会引起状态变更,从而防止因为消息重复导致的数据不一致。
-
Automatic Idempotence with Transactions(事务中的自动幂等性): 当开启 Kafka 事务时,系统会自动启用幂等性。这确保了在事务中的消息发送是幂等的,进一步增强了系统的稳定性和可靠性。
Kafka 的事务机制为分布式消息系统提供了一种可靠的方式,确保消息的一致性和可靠性,适用于需要确保端到端处理的原子性操作的场景。
Kafka事务机制的简单使用
实际上在Java代码中,实现Kafka的事务机制非常简单,当使用 Spring Boot 来实现 Kafka 事务机制时,通常会利用 Spring Kafka 提供的支持,直接使用@Transactional,Kafka就会帮我们开启一个事务。
@Transactional
配置KafkaTemplate 和 KafkaTransactionManager:
- 添加 Kafka 相关依赖: 在您的 Spring Boot 项目的 Maven 或 Gradle 配置文件中,确保已经添加了 Spring Kafka 相关的依赖。例如,在 Maven 项目中,可以添加以下依赖:
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-kafka</artifactId>
</dependency>
- 配置 Kafka 连接信息: 在 application.properties 或 application.yml 中添加 Kafka 连接信息的配置,包括 Kafka 服务器地址、组 ID 等:
spring.kafka.bootstrap-servers=your-kafka-bootstrap-server
spring.kafka.consumer.group-id=your-group-id
- 配置 KafkaTemplate Bean: 在 Spring Boot 项目的配置类(通常是带有 @Configuration 注解的类)中,创建 KafkaTemplate 的 Bean。确保正确配置序列化器等参数:
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.kafka.core.KafkaTemplate;
import org.springframework.kafka.core.ProducerFactory;
@Configuration
public class KafkaConfig {
@Bean
public KafkaTemplate<String, String> kafkaTemplate(ProducerFactory<String, String> producerFactory) {
return new KafkaTemplate<>(producerFactory);
}
}
- 配置 KafkaTransactionManager Bean(可选): 如果您需要使用事务机制,还需要配置 KafkaTransactionManager 的 Bean。确保正确配置 ProducerFactory 和 TransactionIdPrefix:
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.kafka.core.DefaultKafkaProducerFactory;
import org.springframework.kafka.core.ProducerFactory;
import org.springframework.kafka.transaction.KafkaTransactionManager;
@Configuration
public class KafkaConfig {
@Bean
public KafkaTransactionManager<String, String> kafkaTransactionManager(ProducerFactory<String, String> producerFactory) {
KafkaTransactionManager<String, String> transactionManager = new KafkaTransactionManager<>(producerFactory);
transactionManager.setTransactionSynchronization(AbstractPlatformTransactionManager.SYNCHRONIZATION_ON_ACTUAL_TRANSACTION);
return transactionManager;
}
@Bean
public ProducerFactory<String, String> producerFactory() {
// 配置 ProducerFactory,包括序列化器等参数
return new DefaultKafkaProducerFactory<>(producerConfigs());
}
// 其他配置方法
}
生产者(Transactional Producer)启动事务:
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.kafka.core.KafkaTemplate;
import org.springframework.kafka.core.ProducerFactory;
import org.springframework.kafka.transaction.KafkaTransactionManager;
import org.springframework.transaction.annotation.Transactional;
public class KafkaTransactionalProducerService {
@Autowired
private KafkaTemplate<String, String> kafkaTemplate;
@Transactional
public void produceMessagesInTransaction() {
// 在事务中发送消息到多个 topic 和 partition
kafkaTemplate.send("topic1", "key", "Message for topic1");
kafkaTemplate.send("topic2", "key", "Message for topic2");
}
}
在上述代码中,@Transactional 注解表示该方法应该在一个事务中执行。Spring Kafka 将会自动检测并管理 Kafka 事务。
消费者(Transactional Consumer)启动事务:
import org.springframework.kafka.annotation.KafkaListener;
import org.springframework.stereotype.Service;
import org.springframework.transaction.annotation.Transactional;
@Service
public class KafkaTransactionalConsumerService {
@KafkaListener(topics = "topic1")
@Transactional
public void consumeMessage(String message) {
// 在事务中处理消费到的消息
System.out.println("Received message: " + message);
// 处理消息的业务逻辑
}
}
在上述代码中,使用 @KafkaListener 注解标记的方法表示这是一个 Kafka 消费者。同样,通过 @Transactional 注解来确保消费消息的过程在事务中执行。
这里提供的是一个基本的示例,具体的配置和实现可能会因项目的需求而有所不同。在实际应用中,请根据具体情况进行适当的配置和调整。
Kafka事务机制的原理
Transaction Coordinator 和 Transaction Log 组件
为了支持事务机制,Kafka 引入了两个关键的组件:Transaction Coordinator(事务协调器)和 Transaction Log(事务日志)。以下是有关这两个组件的详细信息:
Transaction Coordinator(事务协调器)
Transaction Coordinator 是一个运行在每个 Kafka Broker 上的模块,它是 Kafka Broker 进程的新功能之一,它并不是一个独立的新进程,而是与 Kafka Broker 集成的一部分。Transaction Coordinator 的主要责任是协调和管理事务的生命周期,它与 Producer 和 Consumer 之间进行通信,主要负责分配PID,记录事务状态等操作,确保事务的正确执行,每个事务协调器负责一组Partition的事务协调工作。
Transaction Log(事务日志):
Transaction Log 是 Kafka 的一个内部 Topic,类似于大家熟悉的 __consumer_offsets,也是一个内部 Topic。
Transaction Log 由多个Partition组成,每个Partition有一个 Leader。每个 Leader 对应于一个 Kafka Broker,该 Broker 上的 Transaction Coordinator 负责管理这些分区的写操作。通过内部的复制协议和选举机制,Kafka 确保 Transaction Coordinator 的可用性和 Transaction State 的持久性,确保了即使其中一个 Broker 发生故障,事务仍然可以正确进行。
Transaction Log Topic 内部存储的是事务的最新状态和相关的元数据信息,而不是存储原始消息。事务状态包括 “Ongoing”(进行中)、“Prepare commit”(准备提交)和 “Completed”(已完成)。Kafka Producer 生产的原始消息仍然存储在 Producer 指定的目标 Topic 中,Transaction Log Topic 主要用于跟踪和管理事务的状态,确保它们的一致性和可靠性。
执行流程
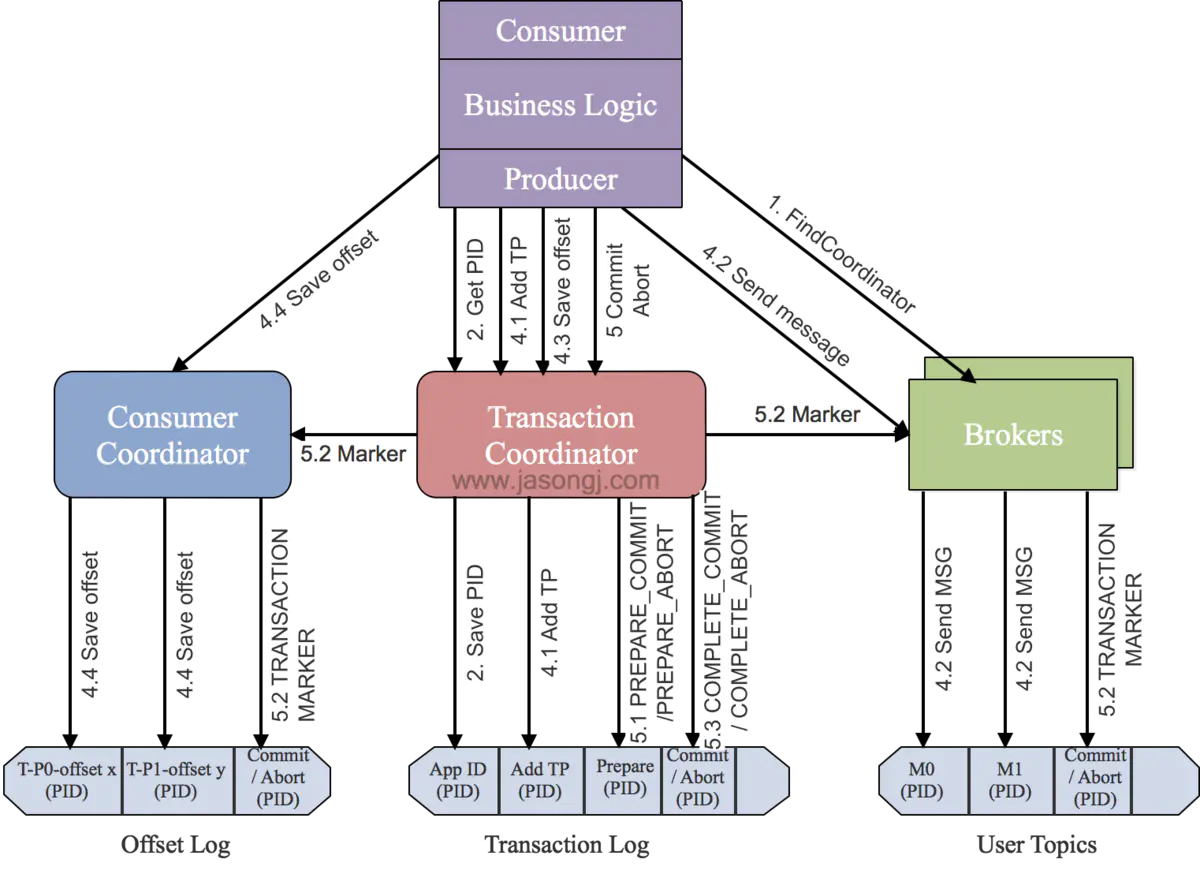
如Kafka的执行流程图所示,Kafka事务机制的执行原理流程大概如下:
-
查找 Transaction Coordinator:
Producer 通过向任意一个 Broker 发送 FindCoordinatorRequest 请求,获取 Transaction Coordinator 的地址,Transaction Coordinator 负责协调和管理事务的生命周期。
-
初始化事务(initTransaction):
Producer 发送 InitPidRequest 给 Transaction Coordinator,获取 PID(Producer ID)。 Transaction Coordinator 记录 PID 和 Transaction ID 的映射关系,并执行一些额外的初始化工作,包括恢复之前未完成的事务和递增 PID 对应的 epoch。
-
开始事务(beginTransaction):
Producer 执行 beginTransaction() 操作,本地记录该事务的状态为开始。此时,Transaction Coordinator 尚未被通知,只有在 Producer 发送第一条消息后,Transaction Coordinator 才认为事务已经开启。
-
Read-Process-Write 流程:
当Producer 开始发送消息,Transaction Coordinator 将消息存储于 Transaction Log 中,并将其状态标记为 BEGIN。如果该事务是第一个消息,Transaction Coordinator 还会启动事务的计时器(每个事务都有自己的超时时间)。注册到 Transaction Log 后,Producer 继续发送消息,即使事务未提交,消息已经保存在 Broker 上。即使后续执行了事务回滚,消息也不会删除,只是状态字段标记为 abort。
-
事务提交或终结(commitTransaction/abortTransaction):
在 Producer 执行 commitTransaction 或 abortTransaction 时,Transaction Coordinator 执行两阶段提交:
- 第一阶段,将 Transaction Log 中该事务的状态设置为 PREPARE_COMMIT 或 PREPARE_ABORT。
- 第二阶段,将 Transaction Marker 写入事务涉及到的所有消息,即将消息标记为 committed 或 aborted。这一步 Transaction Coordinator 会发送给每个事务涉及到的 Leader。Broker 收到请求后,将对应的 Transaction Marker 控制信息写入日志。
一旦 Transaction Marker 写入完成,Transaction Coordinator 将最终的 COMPLETE_COMMIT 或 COMPLETE_ABORT 状态写入 Transaction Log,标明该事务结束。
-
Consumer消费:
Consumer 在 read_committed 模式下只需做一些消息的过滤,即过滤掉回滚了的事务和处于 open 状态的事务的消息。过滤这些消息时,Consumer 利用消息中的元数据信息,不需要与 Transactional Coordinator 进行 RPC 交互。
Kafka事务机制的容错性
Kafka 事务机制的容错性是指系统在面对各种故障和异常情况时,仍能够保持数据的一致性和可靠性。Kafka 通过一系列的设计和机制来保障事务的容错性,主要如下:
-
Transaction Coordinator 的运行位置:
Transaction Coordinator 是运行在每个 Kafka Broker 上的一个模块,而不是一个独立的新进程。每个 Broker 承载一个 Transaction Coordinator,负责协调和管理属于自己的事务。
-
事务状态的保存和持久化:
Transaction Coordinator 将事务的状态保存在内存中,并将其持久化到 Transaction Log 中。这确保了事务状态的持久性,即使 Broker 进程重启,也能够从 Transaction Log 恢复事务状态。
-
Transaction Log 的内部 Topic:
Transaction Log 是 Kafka 的一个内部 Topic,类似于大家熟悉的 consumer_offsets。它有多个分区,每个分区有一个 Leader,该 Leader 对应于一个 Kafka Broker。每个 Broker 上的 Transaction Coordinator 负责对分配给自己的分区进行写操作。
-
容错机制 - Coordinator 故障处理:
如果某个 Broker 宕机,导致其上的 Transaction Coordinator 不可用,其负责的 Transaction Log Partitions 将失去对应的 Leader。在这种情况下,通过选举机制会选择一个新的 Coordinator,新的 Coordinator 将从其他节点的副本中恢复 Transaction Log Partitions 的状态数据。
-
复制协议和选举机制的应用:
由于 Transaction Log 是 Kafka 的内部 Topic,Kafka 利用内部的复制协议和选举机制确保对事务状态的持久化存储和对 Transaction Coordinator 的容错。这确保了即使某个节点发生故障,系统仍然能够保持对事务状态的可靠性和一致性。
总体而言,Kafka 在事务机制下通过 Transaction Coordinator 和 Transaction Log 的结合,以及复制协议和选举机制的应用,实现了对事务状态的持久化存储和对 Coordinator 故障的容错处理。这些机制为 Kafka 提供了高可用性和强大的容错性。感谢您的详细解释!
Kafka事务机制对Producer和Consumer性能的影响
对 Producer 的性能影响:
-
写放大问题:
在事务开始前,Producer 需要将生产的消息的 partition 注册到 Transaction Coordinator(rpt 调用)。在事务结束时,Transaction Coordinator 需要注入 Transaction Marker 到消息对应的 Partition(rpt 调用)。事务进行过程中,Transaction Coordinator 需要将事务状态如 “prepare_commit”、“complete_commit” 持久化到 Transaction Log,涉及到磁盘写操作。
-
性能影响控制:
由于写操作的时间复杂度主要与消息涉及到的分区个数相关,而不是具体消息条数。Kafka 通过批处理机制尽量减小 RPC 调用次数,从而减小了对 Producer 性能的影响。根据 Confluent 官网的性能测试,对于 1KB 大小的消息,在最大吞吐量下,每 100 毫秒提交一次事务仅导致性能下降约 3%。
对 Consumer 的性能影响:
-
轻量级高吞吐:
Consumer 在 read_committed 模式下只需做一些消息的过滤,即过滤掉回滚了的事务和处于 open 状态的事务的消息。过滤这些消息时,Consumer 利用消息中的元数据信息,不需要与 Transactional Coordinator 进行 RPC 交互。
-
元数据信息支持:
消息中包含足够的元数据信息,支持 Consumer 进行消息过滤。Consumer 不需要缓存读取的消息以等待事务的结束,而且仍然可以使用 zero-copy 机制来读取消息。
-
几乎没有性能下降:相对于没有开启事务的 Consumer,性能几乎没有任何明显的下降。
总体而言,开启事务对 Producer 的性能影响相对较小,而对 Consumer 的影响更为微小,尤其在 read_committed 模式下。这样的设计使得 Kafka 在支持事务的同时,保持了较高的性能水平。感谢您的详细解释!
参考文献
[1] https://blog.csdn.net/jy02268879/article/details/106023273
[2] https://zhuanlan.zhihu.com/p/411171789
[3] https://www.lilinchao.com/archives/1550.html















 7563
7563











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









