









【Kafka系列】大禹治水——谈谈Kafka的高性能
欢迎关注,分享更多原创技术内容~
微信公众号:ByteRaccoon、知乎:一只大狸花啊、稀土掘金:浣熊say
微信公众号海量Java、数字孪生、工业互联网电子书免费送~
大禹为什么要治水?——MQ面临的性能压力
相传上古时期,也就是大概公元前4000多年吧,咱们的大水神”共工“,也就是后来撞“不周山”那位哥们,不知道为啥就很气,把天庭中的大禹水库给撞了。咱们这位水神气消没消我不知道,但是凡人就遭殃了,人间洪水泛滥,黄河的水暴涨了500多倍,沿河居民苦不堪言。幸亏有大禹,这位炎帝的儿子,人民的救星,有着三过家门而不入的敬业精神,把这水给治了,拯救了黎民苍生。
那在我们的计算机应用里面,有没有这样的“水神”能引发这样的灾难呢?答案是肯定的,但是在说水神之前我先梳理一下咱们的世界观,在计算机系统里面你可以将数据看作是水,而MQ(Message Queue,消息队列)看作是蓄水的三峡大坝,大禹你就把它看作是修建三峡大坝的工程师吧(我不信大禹是靠人治水的)。
所有角色就绪之后,那么水神怎么样才能引发计算机系统里面的滔天大洪水呢?这里还是不得不举用烂了的例子,就是咋们的双11,天猫淘宝在00:00:00左右所面临的访问压力,这时候的订单数据就跟洪水一样涌进来。这种时候要是我们的水利工程没做好,三峡大坝拦不住这么多水,直接冲到下游整个计算机系统都得瘫痪。
所以,我们说有一个脾气好的“水神”是多么重要,但是现实世界里面的水神那脾气就好不了,随时都可能给你整出个洪水滔天。那我们只能放弃幻想,强化我们的三峡大坝,增加它的处理水的能力才比较靠谱。主要有2个方面,第一是上游的水来了能接得住,不能说水量太大直接把你大坝都给干没了。第二个方面是周转快(吞吐量),就是水流进来了不能老在我大坝这里攒着,还是得分给下游处理掉,根据下游的能力分得越快越好。
咱们大禹治水采用的也是分而治之的方法,堵不如疏。MQ说俺也一样,首先自己扛得住这么多水,其次赶快把多余的洪水分发掉,这就是MQ在面临海量数据时面临的2个挑战,也可以说是性能压力。
高性能核心原理
Kafka Broker线程模型
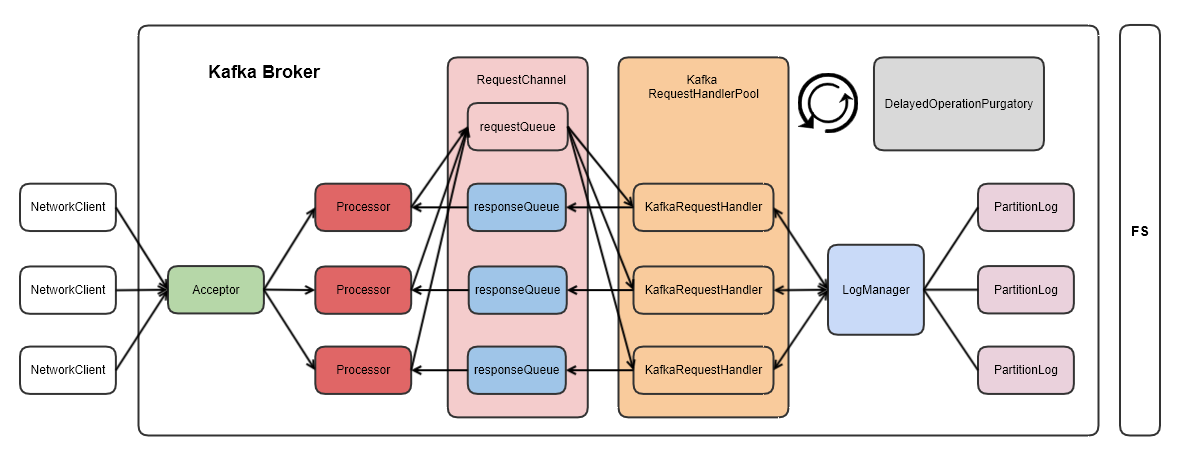
Kafka的Broker线程模型采用了一种经典的设计,其中包括三个主要组件:Acceptor、Processor、和KafkaRequestHandler。这种模型在其他一些网络框架(如Netty、Tomcat、Nginx等)中也有类似的设计。
-
Acceptor(接收器): 在模型中,有一个单独的Acceptor组件负责监听和接收网络连接。每个EndPoint(对应一个网卡)都有一个独立的Acceptor。其主要任务是接收客户端的连接请求,并将连接委托给后续的处理组件。
-
Processor(处理器): 模型中包含多个Processor,其数量由参数N(num.networker.threads)决定。每个Processor都负责处理从客户端发来的请求。这是一种典型的多线程并行处理机制,使得系统能够同时处理多个请求,提高了并发性能。
-
KafkaRequestHandler(Kafka请求处理器): 在Processor中,包含多个KafkaRequestHandler,其数量由参数M(num.io.threads)决定。每个KafkaRequestHandler负责实际处理和解析客户端的请求。这是一个专门用于处理Kafka协议请求的组件。
整体线程模型的设计如下:
- 每个EndPoint(网卡)都有一个独立的Acceptor。
- 有多个Processor,每个Processor处理一个或多个连接,N为Processor的数量。
- 在每个Processor中,有多个KafkaRequestHandler,M为KafkaRequestHandler的数量。
这种设计的优势在于能够充分利用多核CPU的优势,通过并行处理多个请求提高系统的吞吐量。同时,Acceptor的单一性保证了每个网卡的独立性,避免了不必要的竞争。
在具体实现中,这种线程模型也类似于其他一些高性能网络框架,采用了分工明确、多线程协作的方式,使得Kafka能够有效地处理大量的请求并保持高吞吐量。Kafka存储模型
Kafka 文件结构
log文件
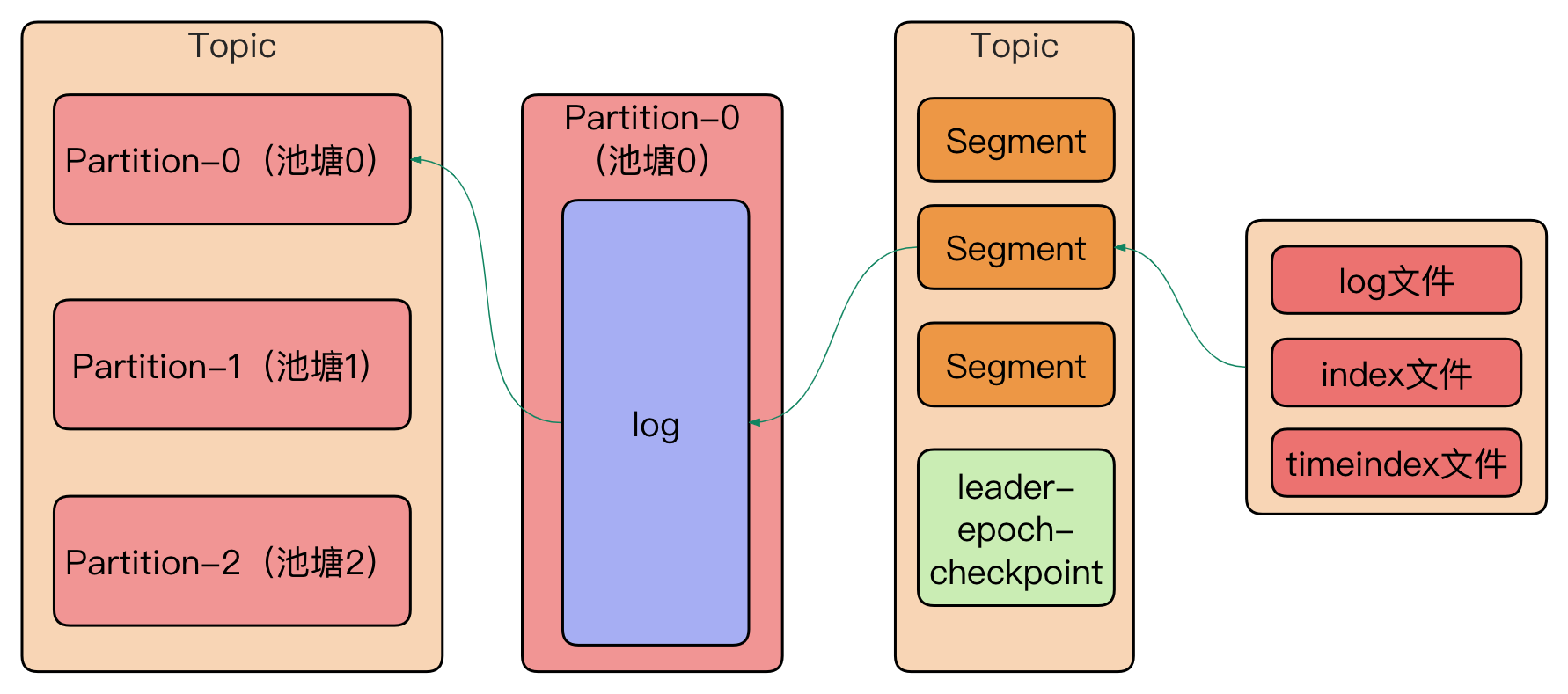
在Kafka节点上,每个Partition都对应一个磁盘目录,这个目录下包含多个LogSegment。每个LogSegment由一个日志文件和一个索引文件组成。日志文件的命名规则为[baseOffset].log,其中baseOffset是该LogSegment中第一条消息的offset。这种组织结构有助于提高Kafka的性能和可靠性。
具体描述如下:
-
Partition目录: Kafka节点上的每个Partition都有一个对应的磁盘目录。这个目录用于存储该Partition的所有日志数据。
-
LogSegment: 每个Partition目录下包含多个LogSegment。LogSegment由一个日志文件(以.log为扩展名)和一个索引文件组成。每个LogSegment都有一个baseOffset,即其中第一条消息的offset。这样的设计允许Kafka在恢复时从特定的offset开始重新读取消息。
-
日志文件: 每个LogSegment的日志文件采用[baseOffset].log的命名规则。写入新消息时,数据直接以追加(append)的方式添加到日志文件的末尾。由于是追加写入,无论文件多大,写入的时间复杂度都是O(1)。
-
索引文件: 每个LogSegment的索引文件用于提供快速的消息查找。索引文件的设计有助于加速消息的检索和定位。通过索引文件,Kafka可以快速定位到消息在日志文件中的位置,提高读取性能。
这种日志文件的组织结构和写入方式使得Kafka能够以高效的方式处理大量的消息数据。同时,通过分割成多个LogSegment,Kafka实现了较好的数据组织和管理,支持快速的消息检索和恢复。这对于一个分布式、高吞吐的消息系统来说是非常重要的。
索引文件
在Kafka索引文件采用了分段和稀疏索引的方式。这种设计使得通过二分查找快速定位到日志位点成为可能,而且返回的是低位点。与日志文件不同,由于索引文件相对较小,Kafka使用了mmap的方式进行操作,以提高速度。
具体描述如下:
-
分段和稀疏索引: 索引文件采用了分段和稀疏索引的方式。这意味着索引文件被划分为多个段,每个段中包含一些索引项。而且,索引项不是每个消息都有,而是按照一定规律设置,使得索引文件的大小相对较小。
-
二分查找: 采用二分查找的方式,通过索引文件快速定位到特定的日志位点。这样的查找算法具有较高的效率,能够在日志文件很大的情况下快速定位到目标位置。
-
返回低位点: 在查找时,索引文件返回的是低位点,即最接近但不超过目标位点的索引项。这样的设计有助于准确定位到目标位置,从而提高读取的准确性。
-
mmap方式操作: 由于索引文件相对较小,Kafka使用mmap(内存映射)的方式进行操作。mmap将文件映射到虚拟内存,使得文件的读取和访问可以直接在内存中进行,避免了磁盘IO的开销,提高了操作速度。
通过以上设计,Kafka的索引文件能够在高效地支持日志文件的查找和定位。这对于快速检索消息,进行高效的读取操作以及提高整体系统性能都是至关重要的。
Kafka高性能原理
Page Cache(页缓存)
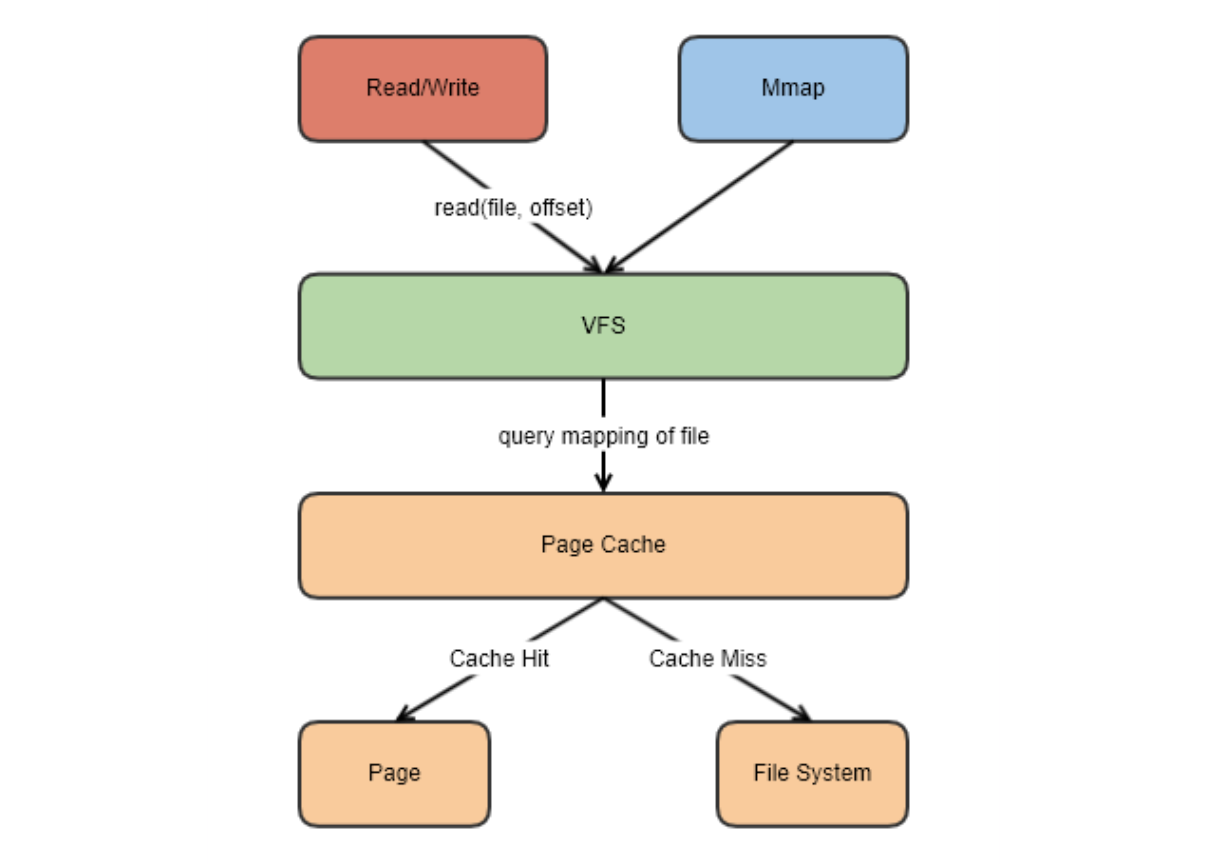
Kafka并不太依赖JVM内存规模,而更注重充分发挥Page Cache的作用,所谓Page Cache其实是操作系统中的一种内存管理技术,它通过将磁盘上的数据块缓存在内存中,提供了对数据的快速访问。如果使用应用层缓存(JVM堆内存)可能会加重垃圾回收GC的负担,导致额外的停顿和延迟增加。
而Page Cache则将磁盘上的数据块缓存在Page Cache中,使得读取操作能够直接在Page Cache上进行,而无需每次都访问物理磁盘。这样的设计在消费和生产速度相当时尤为有效,甚至在某些情况下可以避免直接在物理磁盘上进行数据交换。当数据块已存在于Page Cache中时,读写操作可以在内存中直接进行,避免了较慢的物理磁盘访问。当Page Cache写满的时候,才会由Kafka进行统一的刷盘操作,来完成数据写入磁盘。
另外,即使Kafka发生重启,Page Cache仍然可用,因为Page Cache是由操作系统管理的,而不是由应用程序控制的。这使得Kafka在重启后能够迅速恢复读取性能,而不必等待缓存重新加载。
零拷贝
在Kafka中,大量的网络数据经过两个关键过程进行持久化和传输,直接影响了整个系统的吞吐量。生产者(Producer)将数据通过网络传输到Broker,并在Broker端进行持久化到磁盘的操作。经过磁盘文件,这些数据再通过网络发送给消费者(Consumer)。这两个环节的性能对Kafka整体的吞吐量产生直接而深刻的影响。
传统四次拷贝
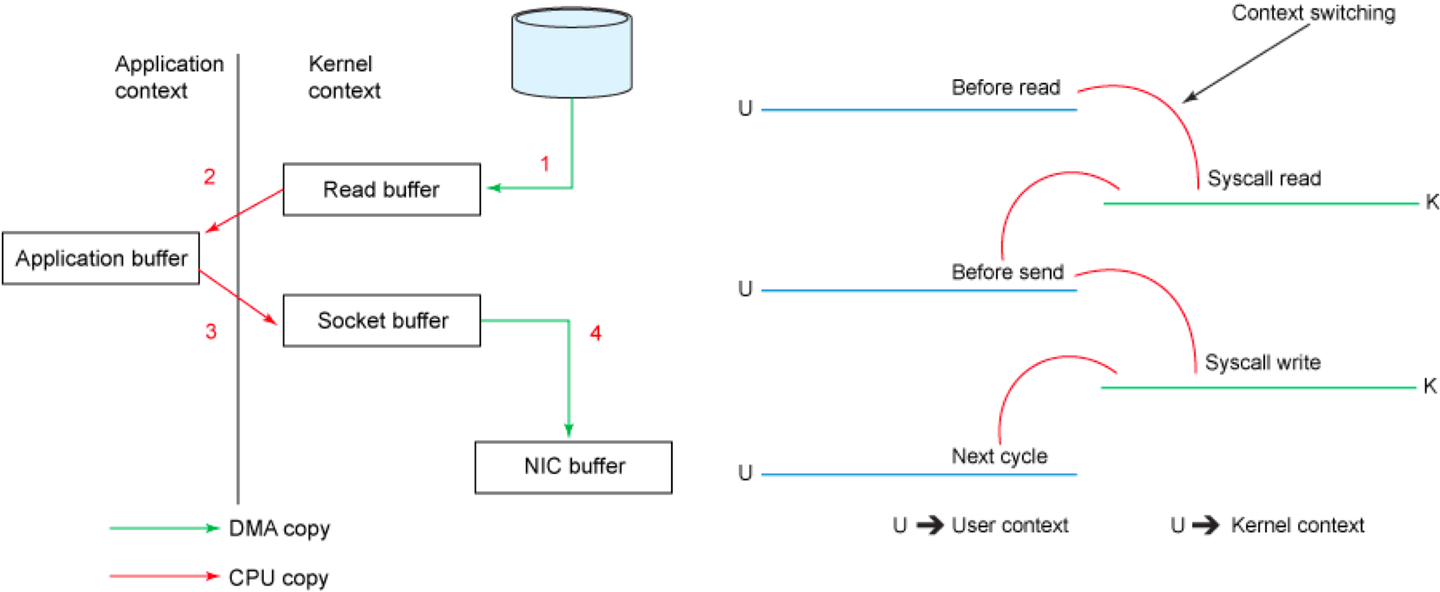
以将磁盘文件通过网络发送为例。传统模式下,一般使用如下伪代码所示的方法先将文件数据读入内存,然后通过Socket将内存中的数据发送出去。
buffer = File.read
Socket.send(buffer)
在传统模式下,将磁盘文件通过网络发送的过程涉及多次数据拷贝和上下文切换,这会导致额外的系统开销和性能的浪费,详细流程如下:
-
DMA拷贝: 通过系统调用将文件数据从磁盘读入内核态Buffer时,可能会使用DMA(直接内存访问)来实现,以避免CPU的过多介入。这是第一次数据拷贝。
-
CPU拷贝: 然后,应用程序将内核态Buffer中的数据复制到用户态Buffer,这是因为内核态和用户态有不同的内存空间,需要进行一次CPU拷贝。这是第二次数据拷贝。
-
CPU拷贝: 在数据通过Socket发送之前,用户程序还需要将数据从用户态Buffer复制到内核态Buffer,以便网络传输。这是第三次数据拷贝。
-
DMA拷贝: 最后,通过DMA拷贝将数据从内核态Buffer发送到网络接口卡(NIC)的Buffer。这是第四次数据拷贝。
同时,每次进行数据拷贝都可能伴随着上下文切换,从用户态到内核态的切换以及反之。这些上下文切换可能会引入额外的开销,特别是在高并发或大规模文件传输的情况下,可能导致系统性能下降。
为了优化这个过程,现代系统通常采用零拷贝技术,通过操作系统和硬件的支持,尽量减少数据在内存之间的复制。这可以通过使用mmap系统调用、sendfile系统调用(在某些系统上支持零拷贝)、直接内存访问(DMA)等技术来实现,从而减少不必要的数据拷贝和上下文切换,提高整体性能。
sendfile和transferTo实现零拷贝
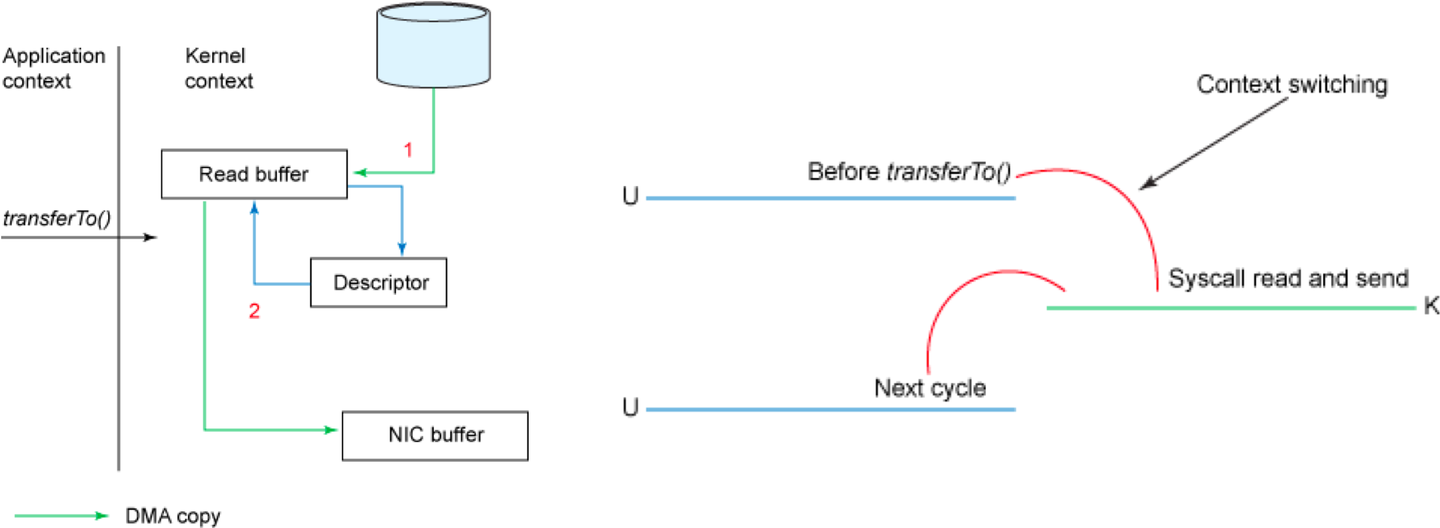
Linux 2.4+内核引入的sendfile系统调用为零拷贝提供了强大支持。一旦数据通过DMA拷贝到内核态Buffer,sendfile直接通过DMA拷贝将数据传输到网络接口卡(NIC)的Buffer,无需涉及CPU拷贝。这是零拷贝这一术语的来源。通过将整个文件读取和网络发送的过程合并到一个sendfile调用中,整个操作只需进行两次上下文切换,显著提高了性能。
具体来说,Kafka的数据传输通过TransportLayer来完成,而PlaintextTransportLayer作为其子类,则利用Java NIO的FileChannel的transferTo和transferFrom方法实现零拷贝。以下是一个简化的代码片段:
@Override
public long transferFrom(FileChannel fileChannel, long position, long count) throws IOException {
return fileChannel.transferTo(position, count, socketChannel);
}
但是,transferTo和transferFrom并不能保证一定能使用零拷贝。是否能够使用零拷贝与操作系统相关。如果操作系统提供了类似sendfile这样的零拷贝系统调用,这两个方法会通过这样的系统调用充分利用零拷贝的优势。否则,它们可能无法通过这两个方法本身实现零拷贝。因此,在不同的操作系统环境下,零拷贝的可行性可能会有所不同。
磁盘顺序写入
磁盘顺序写入在Kafka的设计中起到了关键作用,即使在使用普通的机械磁盘的情况下,顺序访问速率也逼近了内存的随机访问速率。而Kafka每条消息的append操作,确保了磁盘上的顺序写入。不进行中间写入和删除操作有助于维护磁盘的顺序访问特性。
即使进行顺序读写,频繁的大量小IO操作同样可能导致磁盘成为性能瓶颈,这时系统可能会经历随机读写的情况。为了解决这个问题,Kafka采用了上文提到的Page Cache策略,即将消息集合在一起,批量发送,以尽可能减少对磁盘的访问。通过将多个消息进行批量操作,Kafka有效地减少了对磁盘的随机IO,提高了整体性能和效率。
此外,Kafka在设计中建议控制Topic和Partition的数量,以避免过多的分片数。一篇阿里云中间件团队的文章指出,超过64个Topic/Partition后,Kafka性能可能会急剧下降。这是因为过多的Topic和Partition数量可能导致更频繁的元数据更新和分布式计算,从而对系统性能产生不利影响。
全异步
Kafka采用全异步的设计,确保在发送和接收消息、以及复制数据等操作中基本上没有阻塞操作:
- 异步发送: 在Kafka中,调用发送方法(send)会立即返回,而不会等待消息实际被发送到服务器。发送的消息会首先被放入生产者的缓冲区(buffer)中。
ProducerRecord<String, String> record = new ProducerRecord<>("my_topic", "key", "value");
producer.send(record); // 异步发送,立即返回
-
缓冲区管理: 缓冲区管理是异步操作的关键。Kafka使用一个内部的缓冲区来暂时保存待发送的消息,当缓冲区满了或者达到一定的条件时,消息会被批量发送。这样可以最大程度地减少网络开销和提高吞吐量。
-
轮询机制: 发送和接收消息、以及复制数据的过程都是通过NetworkClient封装的poll方式进行的。这种轮询机制是异步操作的关键。在生产者和消费者内部,都有一个后台线程负责轮询缓冲区中的消息并将其发送到目标。这种方式充分利用了异步I/O的特性,不阻塞主线程的执行。
-
回调机制: 在异步发送的过程中,Kafka提供了回调机制,允许你注册回调函数以处理消息发送的结果。这样,你可以在消息成功发送或发送失败时执行相应的逻辑。
producer.send(record, (metadata, exception) -> {
if (exception == null) {
// 处理发送成功的逻辑
} else {
// 处理发送失败的逻辑
}
});
总的来说,Kafka的全异步设计确保了高效的消息处理,使得生产者和消费者能够在异步操作中以高吞吐量和低延迟的方式处理大量的消息。这对于构建大规模、高性能的消息系统非常有益。
批量操作
批量操作在Kafka中是非常关键的性能优化策略之一。结合磁盘顺序写入和异步发送,批量操作可以显著提高Kafka的性能和吞吐量,以下是一些关于批量操作的更详细的解释:
- RecordAccumulator: 在Kafka中,RecordAccumulator是一个用于聚合记录(records)的缓冲区。当生产者发送消息时,消息会首先进入RecordAccumulator,而不是立即发送到服务器。这个缓冲区的存在允许多个消息被批量处理,以减少网络开销。
ProducerRecord<String, String> record = new ProducerRecord<>("my_topic", "key", "value");
producer.send(record); // 消息首先进入 RecordAccumulator
- 批量压缩: Kafka支持在消息发送时进行批量压缩,以减小网络传输的数据量。这通过配置Producer的压缩类型(例如snappy、gzip等)来实现。批量压缩可以减轻网络负担,特别是在处理大量数据时,能够显著提高效率。
Properties properties = new Properties();
properties.put("compression.type", "snappy");
Producer<String, String> producer = new KafkaProducer<>(properties);
- 批量刷盘: Kafka的生产者通常会有一个配置,控制消息何时被批量刷写到磁盘。这可以通过配置batch.size参数,表示RecordAccumulator中的消息数量达到一定阈值时触发批量刷盘。
Properties properties = new Properties();
properties.put("batch.size", 16384); // 设置批量大小
Producer<String, String> producer = new KafkaProducer<>(properties);
总的来说,批量操作有助于减少网络开销、提高磁盘顺序写入效率,并在一定程度上降低了系统的延迟。这种机制充分利用了Kafka的异步和缓冲特性,是构建高性能、高吞吐量消息系统的关键设计之一。
文件压缩
文件压缩是Kafka中的一个重要性能优化策略,通过减小数据的存储空间和降低网络传输的数据量,可以提高整体系统的效率。以下是有关Kafka文件压缩的一些关键概念和实现:
- 压缩类型: Kafka支持多种压缩算法,例如snappy、gzip、lz4等。你可以根据具体的需求选择合适的压缩类型。这可以在Producer和Consumer的配置中进行设置。
// Producer配置中设置压缩类型
properties.put("compression.type", "snappy");
// Consumer配置中设置解压缩类型
properties.put("compression.type", "snappy");
- Producer端压缩: 在Producer端,你可以配置消息在发送时进行压缩。这可以通过设置Producer的compression.type属性来实现。压缩后的消息将占用更小的存储空间,并在网络上传输时减小数据量。
// 设置Producer的压缩类型
properties.put("compression.type", "snappy");
Producer<String, String> producer = new KafkaProducer<>(properties);
// 发送消息时会使用指定的压缩算法
producer.send(new ProducerRecord<>("my_topic", "key", "compressed_value"));
-
Consumer端解压缩: 在Consumer端,Kafka会自动解压缩消息,无需额外的配置。Consumer从Broker接收到的消息已经是解压缩后的原始数据。这意味着Consumer不需要关心消息是否经过了压缩。
-
Broker配置: 在Broker端,你可以配置允许或禁止消息压缩。在Kafka的Broker配置文件中,你可以设置compression.type属性,以决定Broker是否接受和存储压缩后的消息。
# 设置Broker允许的压缩类型
compression.type=snappy
- 性能权衡: 尽管压缩可以减小存储和网络开销,但也需要考虑压缩和解压缩的计算开销。不同的压缩算法在性能和压缩比方面可能存在差异,因此需要根据具体的场景和需求进行权衡。
总结
Kafka作为一个高性能、分布式的消息系统,在其设计和实现中采用了多种关键性能优化策略,以保证系统的高吞吐量、低延迟和稳定性。以下是一些关键的优化策略和设计原理:
-
Broker线程模型: Kafka的Broker线程模型采用了经典的设计,包括Acceptor、Processor和KafkaRequestHandler。这种设计充分利用多核CPU,通过并行处理多个请求提高系统吞吐量。
-
Kafka存储模型: Kafka采用了基于日志文件的存储模型,其中每个Partition对应一个磁盘目录,包含多个LogSegment。索引文件采用了分段和稀疏索引的方式,通过二分查找快速定位消息。这样的设计支持高效的消息查找和恢复。
-
Page Cache(页缓存): Kafka充分发挥操作系统的Page Cache,将磁盘上的数据块缓存在内存中,提供对数据的快速访问。这减轻了对磁盘的频繁读写,提高了读取性能。
-
零拷贝: 通过使用零拷贝技术,Kafka尽量减少数据在内存之间的复制,提高了数据传输效率。sendfile系统调用和FileChannel的transferTo和transferFrom方法在实现零拷贝中发挥了关键作用。
-
磁盘顺序写入: Kafka通过顺序写入磁盘,避免了随机IO,结合Page Cache策略,提高了磁盘的顺序访问特性,减小了系统的延迟。
-
全异步设计: Kafka采用全异步的设计,包括异步发送、缓冲区管理、轮询机制和回调机制。这确保了高效的消息处理,使得生产者和消费者能够以高吞吐量和低延迟的方式处理大量的消息。
-
批量操作: 使用RecordAccumulator进行批量操作,Kafka充分利用了批量压缩、批量刷盘等机制,减少了网络开销和提高了磁盘顺序写入效率。
-
文件压缩: Kafka支持多种压缩算法,可以在Producer和Consumer配置中进行设置。压缩可以减小存储和网络传输的数据量,提高整体系统的效率。
这些优化策略共同构成了Kafka作为一个高性能消息系统的核心原理。综合利用这些设计原理,Kafka能够在处理大规模消息数据时表现出色,适用于各种复杂的分布式应用场景。















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









