







使用sklearn提取文本tfidf特征
参考

或者:


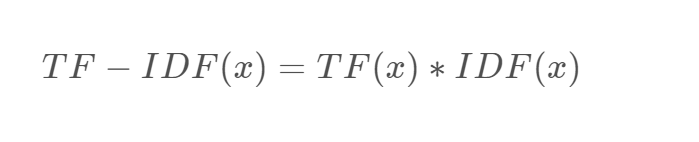
语料库:
corpus = [
'this is the first document',
'this is the second second document',
'and the third one',
'is this the first document'
]
from sklearn.feature_extraction.text import TfidfVectorizer
tfidf_vec = TfidfVectorizer()
tfidf_matrix = tfidf_vec.fit_transform(corpus)
# 得到语料库所有不重复的词
print(tfidf_vec.get_feature_names())
# 得到每个单词对应的id值
print(tfidf_vec.vocabulary_)
# 得到每个句子所对应的向量
# 向量里数字的顺序是按照词语的id顺序来的
print(tfidf_matrix.toarray())
[输出]:
['and', 'document', 'first', 'is', 'one', 'second', 'the', 'third', 'this']
{'this': 8, 'is': 3, 'the': 6, 'first': 2, 'document': 1, 'second': 5, 'and': 0, 'third': 7, 'one': 4}
[[0. 0.43877674 0.54197657 0.43877674 0. 0.
0.35872874 0. 0.43877674]
[0. 0.27230147 0. 0.27230147 0. 0.85322574
0.22262429 0. 0.27230147]
[0.55280532 0. 0. 0. 0.55280532 0.
0.28847675 0.55280532 0. ]
[0. 0.43877674 0.54197657 0.43877674 0. 0.
0.35872874 0. 0.43877674]]
python提取文本的tfidf特征
corpus = [
'this is the first document',
'this is the second second document',
'and the third one',
'is this the first document'
]
#对语料进行分词
word_list = []
for i in range(len(corpus)):
word_list.append(corpus[i].split(' '))
print(word_list)
[输出]:
[['this', 'is', 'the', 'first', 'document'],
['this', 'is', 'the', 'second', 'second', 'document'],
['and', 'the', 'third', 'one'],
['is', 'this', 'the', 'first', 'document']]
#统计词频
countlist = []
for i in range(len(word_list)):
count = Counter(word_list[i])
countlist.append(count)
countlist
[输出]:
[Counter({'document': 1, 'first': 1, 'is': 1, 'the': 1, 'this': 1}),
Counter({'document': 1, 'is': 1, 'second': 2, 'the': 1, 'this': 1}),
Counter({'and': 1, 'one': 1, 'the': 1, 'third': 1}),
Counter({'document': 1, 'first': 1, 'is': 1, 'the': 1, 'this': 1})]
#定义计算tfidf公式的函数
# word可以通过count得到,count可以通过countlist得到
# count[word]可以得到每个单词的词频, sum(count.values())得到整个句子的单词总数
def tf(word, count):
return count[word] / sum(count.values())
# 统计的是含有该单词的句子数
def n_containing(word, count_list):
return sum(1 for count in count_list if word in count)
# len(count_list)是指句子的总数,n_containing(word, count_list)是指含有该单词的句子的总数,加1是为了防止分母为0
def idf(word, count_list):
return math.log(len(count_list) / (1 + n_containing(word, count_list)))
# 将tf和idf相乘
def tfidf(word, count, count_list):
return tf(word, count) * idf(word, count_list)
#计算每个单词的tfidf值
import math
for i, count in enumerate(countlist):
print("Top words in document {}".format(i + 1))
scores = {word: tfidf(word, count, countlist) for word in count}
sorted_words = sorted(scores.items(), key=lambda x: x[1], reverse=True)
for word, score in sorted_words[:]:
print("\tWord: {}, TF-IDF: {}".format(word, round(score, 5)))
[输出]:
Top words in document 1
Word: first, TF-IDF: 0.05754
Word: this, TF-IDF: 0.0
Word: is, TF-IDF: 0.0
Word: document, TF-IDF: 0.0
Word: the, TF-IDF: -0.04463
Top words in document 2
Word: second, TF-IDF: 0.23105
Word: this, TF-IDF: 0.0
Word: is, TF-IDF: 0.0
Word: document, TF-IDF: 0.0
Word: the, TF-IDF: -0.03719
Top words in document 3
Word: and, TF-IDF: 0.17329
Word: third, TF-IDF: 0.17329
Word: one, TF-IDF: 0.17329
Word: the, TF-IDF: -0.05579
Top words in document 4
Word: first, TF-IDF: 0.05754
Word: is, TF-IDF: 0.0
Word: this, TF-IDF: 0.0
Word: document, TF-IDF: 0.0
Word: the, TF-IDF: -0.04463















 8万+
8万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









