









 TF-IDF是一种常用的文本特征表示方法,用于衡量词在文档中的重要性。TF表示词频,IDF则反映了词的稀有程度。本文详细介绍了TF-IDF的计算公式,包括TF、IDF和TF-IDF的定义,并通过信息论角度解释了其数学原理。
TF-IDF是一种常用的文本特征表示方法,用于衡量词在文档中的重要性。TF表示词频,IDF则反映了词的稀有程度。本文详细介绍了TF-IDF的计算公式,包括TF、IDF和TF-IDF的定义,并通过信息论角度解释了其数学原理。
TF-IDF是Term Frequency - Inverse Document Frequency的缩写,即“词频-逆文本频率”。它由两部分组成,TF和IDF。在前期的关键词提取和文本one-hot的时候使用较多
1、TF-IDF 算法
TF(词频):表示词w在文档Di中出现的频率,计算公式如下

其中count(w)为关键词w出现的次数,|Di| 为文档Di中所有词的数量。
IDF(逆文档频率):)反映关键词的普遍程度——当一个词越普遍(即有大量文档包含这个词)时,其IDF值越低;反之,则IDF值越高。计算公式如下:

其中,N为所有的文档总数,I(w,Di)表示文档Di是否包含关键词,若包含则为1,若不包含则为0。若词w在所有文档中均未出现,则IDF公式中的分母为0,因此实践中需要对IDF做平滑

词w在文档Di的TF-IDF值计算如下:
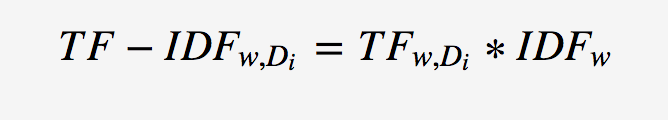
2、TF-IDF代码实现
from sklearn.feature_extraction.text import TfidfVectorizer
corpus=["I come to China to travel",
"This is a car polupar in China",
"I love tea and Apple ",
"The work is to write some papers in science"]
#如果是中文需要对文本进行分词,去掉停用词
tfidf2 = TfidfVectorizer()
re = tfidf2.fit_transform(corpus)
print re
3、TF-IDF的数学原理
TF-IDF虽然广泛应用到NLP,信息检索等领域,但是它出现之初,是没有数学原理支撑的,解释性很差。吴军老师在《数学之美》中对于TF-IDF从信息论的角度进行了解释。
在信息论中,我们可以用query中关键词(key word)的信息量来表示这个关键词所含有信息的多少,所以我们可以用关键词的信息量来表示这个词的权重,可以用公式表示
因为N为整个语料库的大小,所以N是一个常数,然后我们可以把公式表示成如下所示:
但是有个缺陷:两个词的TF相同,一个是某篇特定文章中的常见词,而另一个词是分散在多篇文章中的,那么显然第一个词有更高的分辨率,它应该有更大的权重。
吴军博士对此做出了以下的理想假设:
1.每篇文章的大小基本相同,均为M个词那么
2.一个关键词在文章中出现,不管出现多少次,贡献都等同,这样一个词要么在一个文献中出现c(w)=TF(w)/D(w)次,要么是0(c(w) < M)。所以从上面得到的公式我们可以推导出:
所以,由这个公式可以知道,TF-IDF和信息量之间的差异,因为上式随着c(w)的增加而递减,所以我们将上述公式继续进行推导可以得到:
所以可以得到:
所以由上述式子可以知道,当关键词的信息量I(w)越大,那么他的TF-IDF(w)的值就越大;同时query命中文章中的w次数越多,c(w)越大,TF-IDF(w)也越大。所以在信息论的角度,可以合理的解释TF_IDF的数据原理。





















 2622
2622

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









