






在文本处理中,经常用到TF-IDF,其英文是Term Frequency - Inverse Document Frequency,词频-逆文档频率。
作用是提取文档的关键词,思路是文档的出现最多的词,乘以逆文档作为权重的结果。
然后按照数值进行排序,就能得到文档的关键词从高到低的顺序。
基于每篇的词频向量,计算余弦相似度,就等得到文件之间的相似度。
从而完成相似文章推荐,相似文章添加评论。
TF-IDF基本步骤:
1、统计词频,标准化处理(考虑文章字数长短不一)。
2、计算逆文档频率,需要参考语料库,词频越常见,逆文档频率越接近于0.
3、计算TF-IDF,排序。得到文档的关键词向量组合。
有了上述关键词向量组合,除了计算文章相似度,还可以用于信息检索。
在用户输入检索信息时,对每篇文档计算搜索值词的TF-IDF值(对每个检索词TF-IDF值相加),得到整个文档的TF-IDF,然后排序,取最大值TF-IDF即为最匹配搜索词的文档。
特点:TF-IDF计算词频,速度快,对于大多数情况效果都很好。缺点是没有考虑词出现的位置,没有词的权重,各个词的权重与位置信息无关。比如,可能一段的开头句中,词的重要性高,这是另外需要考虑的问题。
余弦相似度:
1、通过TF-IDF得到文档的词频向量。
2、通过余弦公司求相似度。
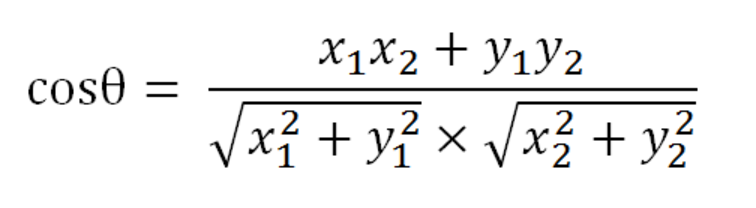
参考文章
1、http://www.ruanyifeng.com/blog/2013/03/tf-idf.html
2、http://www.ruanyifeng.com/blog/2013/03/cosine_similarity.html
3、http://www.ruanyifeng.com/blog/2015/07/monte-carlo-method.html(关于蒙特卡洛的入门介绍)















 355
355

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









