









0 前言
写接口自动化之前往往需要对一个接口进行仔细的了解,需要模拟请求并构造不同请求参数来初步验证接口的功能,目前在这个过程中发现直接使用python的requests来构造http请求是非常方便和轻量的方案,并且对后续返回参数的自定义校验所需要的成本也很低,无论是直接返回的json,pb化后的数据还是jsonp,都可以很好的支持。相对postman来说是不错的替代方案。
为此利用alfred搞了个快速生成python请求代码的工具。下面是详细介绍
1.工程基本结构

1.1调试接口请求的函数放在一个文件里
pyPostman.py大致结构如下
import requests
import time
# 接口请求的函数代码在此定义
def get_example():
url = ''
params = {
}
headers = {
}
resp = requests.get(url=url, params=params, headers=headers)
print(resp.content)
def post_example():
url = ''
params = {
}
body = {
}
headers = {
}
resp = requests.post(url=url, params=params, data=body, headers=headers)
print(resp.content)
# 在此执行函数
get_example()
post_example()1.2一些常用的函数放在另一个文件里
提供一些扩展的能力,reqUtils.py大致结构如下
import json
import subprocess
import time
import unittest
import lvideo_api_pb2
import video_danmaku_pb2
# 重构解析json字符串,去除转义
def getJsonDict(jsonData: dict):
if type(jsonData) != dict:
return
for i in jsonData.keys():
try:
jsonData[i] = json.loads(jsonData[i])
getJsonDict(jsonData[i])
except TypeError:
if (type(jsonData[i])) == dict:
getJsonDict(jsonData[i])
if (type(jsonData[i])) == list:
for index in range(len(jsonData[i])):
try:
jsonData[i][index] = json.loads(jsonData[i][index])
getJsonDict(jsonData[i][index])
except TypeError:
if (type(jsonData[i][index])) == dict:
getJsonDict(jsonData[i][index])
except json.decoder.JSONDecodeError:
if (type(jsonData[i][index])) == dict:
getJsonDict(jsonData[i][index])
except json.decoder.JSONDecodeError:
if (type(jsonData[i])) == dict:
getJsonDict(jsonData[i])
if (type(jsonData[i])) == list:
for index in range(len(jsonData[i])):
try:
jsonData[i][index] = json.loads(jsonData[i][index])
getJsonDict(jsonData[i][index])
except TypeError:
if (type(jsonData[i][index])) == dict:
getJsonDict(jsonData[i][index])
except json.decoder.JSONDecodeError:
if (type(jsonData[i][index])) == dict:
getJsonDict(jsonData[i][index])
# 根据pb文件反序列化返回的接口数据
def printIDL(psm, attr, serializeString):
print('反序列化解析数据:')
if (psm == 'toutiao.lvideo.api'):
try:
streamResponse = getattr(lvideo_api_pb2, attr)()
streamResponse.ParseFromString(serializeString)
print(streamResponse)
return streamResponse
except Exception:
print('反序列化失败,继续输出bytes')
print(serializeString)
return serializeString
if (psm == 'toutiao.danmaku.api'):
try:
streamResponse = getattr(video_danmaku_pb2, attr)()
streamResponse.ParseFromString(serializeString)
print(streamResponse)
return streamResponse
except Exception:
print('反序列化失败,继续输出bytes')
print(serializeString)
return serializeString
else:
print('暂时不支持此psm的反序列化')
print(serializeString)
return serializeString
# 获取当前时间戳
def getCurrentTS():
# print(int(time.time()))
return str(int(time.time()))
# 根据curl执行命令
def getShellExecuteReturn(shellString):
print(shellString)
sub = subprocess.Popen(shellString, shell=True, stdout=subprocess.PIPE)
string = sub.stdout.read()
results = string.decode().split('\n')
results1 = []
for i in results:
if i is not None and i != '':
results1.append(i)
return results1
# 根据路径返回json getJsonByRoute('data.1.content.title',jsonResponse)
def getJsonByRoute(keyRoute, result):
keyRoutes = keyRoute.split('.')
for i in keyRoutes:
try:
i = int(i)
except ValueError:
pass
result = result[i]
return result
# 根据路径返回Message getMessageByRoute('data.1.text',streamResponse)
def getMessageByRoute(keyRoute, message):
keyRoutes = keyRoute.split('.')
for i in keyRoutes:
try:
i = int(i)
message = message[i]
except ValueError:
for j in message.ListFields():
if j[0].name == i:
message = j[1]
return message
# 往文件写入字符串
def writeFileWithString(mode='a+',string='', route=''):
with open(route, mode) as f:
f.write(string)
f.close()1.3一些已经编译好pb文件示例
idlList文件夹可以倒入工程目录后直接import使用,注意在pycharm中构建的时候需要将文件夹设置为source:
2.利用Alfrd工具快速生成python代码,进行接口调试
alfred工具下载:
链接: https://pan.baidu.com/s/1av6RGfNwQ_4byfWSh9t0Qw 密码: k5d7
2.1 生成python代码过程演示
curlToReq工具演示
charles抓包 - 复制curlrequest - 呼出alfred工具快速生成一段完整的可执行的代码 - 复制到pycharm中执行
2.2生成代码的结构分析
根据抓包结果的curl request字符串将一个请求的请求url,请求参数,post请求的body,请求头封装成了一个json,使用requests库发起get或post(暂只支持这辆请求)请求进行调试。
很多时候,请求参数并不是都是有意义的,可以通过注释掉某些参数来找到那些必要的参数。或者是将某些参数(时间戳)改成动态的由python代码生成也是非常方便的,对于执行结果也可以进行快捷方便的规则验证。以及一些业务场景涉及多个接口先后请求,也可以快速组建请求链路。
def test():
getData = {
"url": "https://slamdunk.sports.sina.cn/api",
"params": {
"p": "radar",
"s": "leaders",
"a": "players",
"callback": "jQuery33108884994167071085_1616238380231",
"page": "1",
"limit": "15",
"season_type": "reg",
"item": "points",
"item_type": "average",
"_": "1616238380232"
},
"headers": {
"Host": "slamdunk.sports.sina.cn",
"Cookie": "ustat=__10.83.234.78_1616235699_0.16723900; genTime=1616235699; vt=4; Apache=1585052768675.2368.1616235701971; SINAGLOBAL=1585052768675.2368.1616235701971; ULV=1616235701976:1:1:1:1585052768675.2368.1616235701971:; recent_visited=[{\"t\":1616235701981,\"u\":\"https://nba.sina.cn/\"}]; statuid=__119.139.167.138_1616235713_0.93602600; statuidsrc=Mozilla/5.0+(Linux;+Android+10;+V1962A;+wv)+AppleWebKit/537.36+(KHTML,+like+Gecko)+Chrome/62.0.3202.84+Mobile+Safari/537.36+VivoBrowser/9.1.10.1`119.139.167.138`http://slamdunk.sports.sina.cn/?vt=4`https://nba.sina.cn/`__119.139.167.138_1616235713_0.93602600; SLAMDUNK-SPORTS-SINA-COM-CN=; historyRecord={\"href\":\"https://slamdunk.sports.sina.cn/\",\"refer\":\"https://nba.sina.cn/\"}",
"accept": "text/javascript, application/javascript, application/ecmascript, application/x-ecmascript, */*; q=0.01",
"x-requested-with": "XMLHttpRequest",
"user-agent": "Mozilla/5.0 (Linux; Android 10; V1962A; wv) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/62.0.3202.84 Mobile Safari/537.36 VivoBrowser/9.1.10.1",
"referer": "https://slamdunk.sports.sina.cn/?vt=4&key=tongji",
"accept-language": "zh-CN,en-US;q=0.9"
}
}
resp = requests.get(url=getData['url'], params=getData['params'], headers=getData['headers'])
print('状态码:', end='')
print(resp.status_code)
print('响应头:', end='')
print(json.dumps(dict(resp.headers)))
if 'json' in resp.headers['Content-Type']:
print('响应JSON字符串:', end='')
jsonResponse = json.loads(resp.content.decode())
getJsonDict(jsonResponse)
print(json.dumps(jsonResponse, ensure_ascii=False))
if 'javascript' in resp.headers['Content-Type']:
regex = ".*?\\(({.*?)\\);.*?"
results = re.findall(regex, resp.text, re.S)
print('响应JSONP字符串:', end='')
jsonResponse = json.loads(results[0])
getJsonDict(jsonResponse)
print(json.dumps(jsonResponse, ensure_ascii=False))
for i in jsonResponse['result']['data']['players']:
print(i['last_name'] + '得分:' + str(i['points']))
if 'octet-stream' in resp.headers['Content-Type']:
print('响应bytes:')
print(resp.content)
# printIDL('xxx.lvideo.api', 'ChannelResponse' , resp.content)
# printIDL('xxx.lvideo.api', 'InfoResponse' , resp.content)
# printIDL('xxx.danmaku.api', 'GetDanmakuResponse' , resp.content)
# printIDL('xxx.danmaku.api', 'SendDanmakuResponse' , resp.content)
# printIDL('xxx.danmaku.api', 'DanmakuReportResponse' , resp.content)2.3执行结果分析
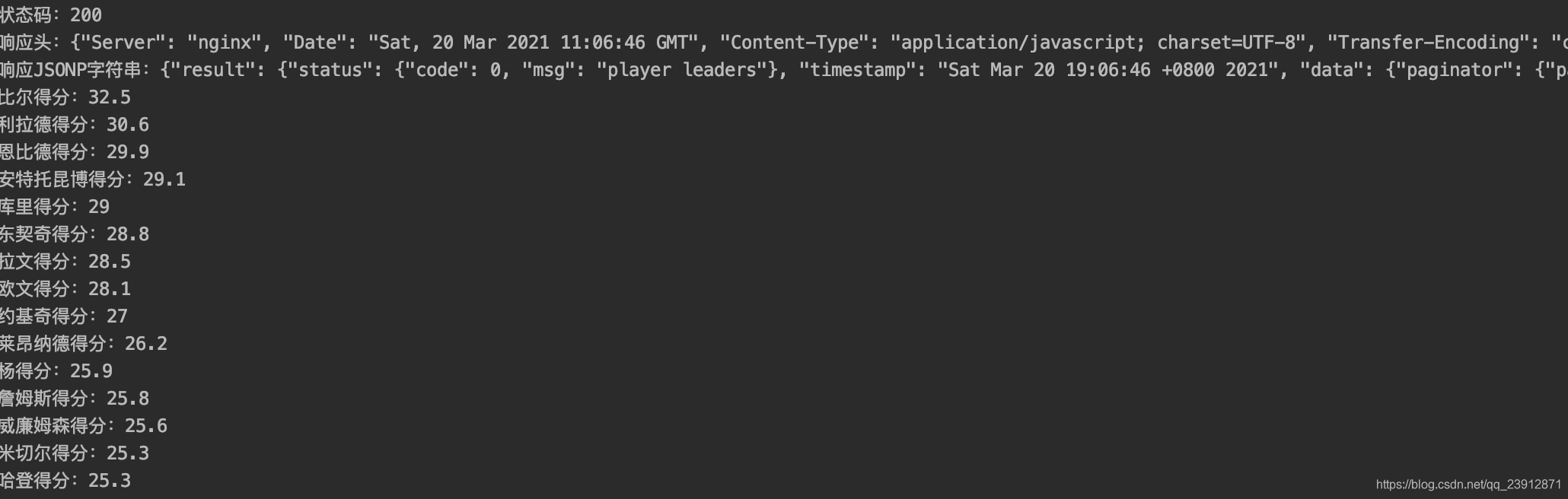
自动生成的代码会输出状态码,响应头,响应数据三个部分,通过导入上文说到的reqUtils.py还可以得到被反转义的json字符串,可以复制到http://www.bejson.com/jsonviewernew/查看详细数据结构,也可以通过代码分析响应数据结构或制定验证规则。
导入上文提到的idlList文件夹和reqUtils.py文件,可以将某些返回数据反序列化,使得可读性更高,并能制定返回数据验证规则。当然也可以自己去做更多场景的适配,














 984
984











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









