







本文基于题库查重需求实现过程及《NLP自然语言处理原理与实践》学习过程总结得出。定有不足之处,恳请指出。
介绍
中文分词是自然语言处理(NLP)在中文环境下,首要解决的问题。主要难点为中文不同于英文,存在明确的分隔符(如空格)用于切分词语,且不同的切分方式,不一定存在语病,举个例子:
- 结婚的/和尚/未结婚的人。
- 结婚的和尚未结婚的人
基本概念
评价指标
一般,中文分词从Precision、Recall、F-score三个维度评价。一般我们比较关注的是F-score。如下图(图片来源 https://github.com/lancopku/pkuseg-python),该图描述了三种中文分词工具的三个指标,便于用户比较三个工具关于某特定数据集合进行分词的结果评价指标。
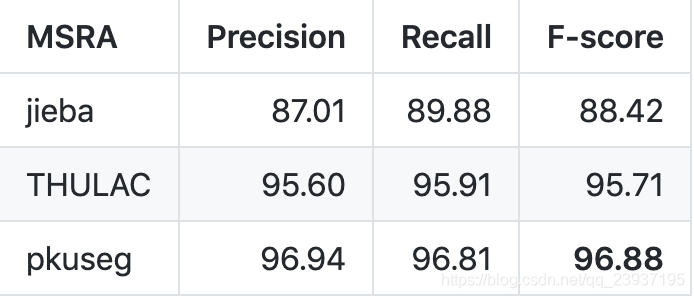
有时 F-score 也被描述为 F1-Measure,这两者是同一概念。
模型评价标准
对于模型(包括语义模型、分类/聚类模型等),一般有四个指标判断模型效果:
- Accuracy(准确率)——总样本数中被正确判定数占比
- Recall(召回率)——总正确数中被正确判定数占比
- Precision(精确度、精确率)——总结果数中被正确判定数占比
- F1-Measure——Precision与Recall的harmonic mean(调和平均数; 倒数平均数),意义在于同时关联被正确判定数、被错误判定
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1552
1552











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









