




背景:
我们在点外卖的场景中,经常会看到菜品A+菜品B+菜品C的组合,这种组合的产生主要是为了节省用户的点餐时间,方便客户从海量菜品中找到理想菜品,通过引入Apriori推荐算法,得到菜品之间的关联度指标,找到最有可能的"啤酒和尿不湿"的组合,以供运营可以为商家的菜品组合套餐作为参考。
1.Apriori算法简介
选择物品间的关联规则也就是要寻找物品之间的潜在关系。要寻找这种关系,有两步,以超市为例
找出频繁一起出现的物品集的集合,我们称之为频繁项集。比如一个超市的频繁项集可能有{{啤酒,尿布},{鸡蛋,牛奶},{香蕉,苹果}}
在频繁项集的基础上,使用关联规则算法找出其中物品的关联结果。
简单点说,就是先找频繁项集,再根据关联规则找关联物品。
关联分析的几个概念
1.1 支持度
支持度(Support):支持度可以理解为物品当前流行程度。计算方式是:
支持度 = (包含物品A的记录数量) / (总的记录数量)
用上面的超市记录举例,一共有五个交易,牛奶出现在三个交易中,故而{牛奶}的支持度为3/5。{鸡蛋}的支持度是4/5。牛奶和鸡蛋同时出现的次数是2,故而{牛奶,鸡蛋}的支持度为2/5。
1.2 置信度
置信度(Confidence):置信度是指如果购买物品A,有较大可能购买物品B。计算方式是这样:
置信度( A -> B) = (包含物品A和B的记录数量) / (包含 A 的记录数量)
举例:我们已经知道,(牛奶,鸡蛋)一起购买的次数是两次,鸡蛋的购买次数是4次。那么Confidence(牛奶->鸡蛋)的计算方式是Confidence(牛奶->鸡蛋)=2 / 4。
1.3提升度
提升度(Lift):提升度指当销售一个物品时,另一个物品销售率会增加多少。计算方式是:
提升度( A -> B) = 置信度( A -> B) / (支持度 A)
举例:上面我们计算了牛奶和鸡蛋的置信度Confidence(牛奶->鸡蛋)=2 / 4。牛奶的支持度Support(牛奶)=3 / 5,那么我们就能计算牛奶和鸡蛋的支持度Lift(牛奶->鸡蛋)=0.83
当提升度(A->B)的值大于1的时候,说明物品A卖得越多,B也会卖得越多。而提升度等于1则意味着产品A和B之间没有关联。最后,提升度小于1那么意味着购买A反而会减少B的销量。
更多关于Apriori的信息,可以查阅相关文献,这种文献现在挺多的。
2.基于Python的实现
第一步,首先要清洗菜品数据,有很多菜品因为规格不一样,而成为了一个单独的sku,例如衬衫XL,衬衫L是两只sku,但是其实是同一个spu,对此我们进行一部分数据清洗,
这里需要用 到正则表达式,
另外,由于商家的标准sku里面会有米饭,可乐,单点不送,锅底这种非正常菜品的sku,为了将其排除在外,对单价小于5快钱的菜品(参考了可乐,米饭等菜品的集中价格)做了过滤。但是后来发现,对于一些品类例如冒菜,麻辣香锅这种,他的菜品由于都是低价格的单品(例如青菜一份2.5元这种,因此,单纯的按照价格就会导致过滤错了较多的菜品,因此最后在价格的基础上还要加上品类的限制做为排除条件,另外考虑到部分订单是多人餐使用场景,点的菜比较多,也会造成菜品的虚高关联度,因此在组合套餐的时候我们筛选了只有2个菜品的订单和只有3个菜品的订单,最终得到待计算关联度的菜品订单数据集。
import pandas as pd
import numpy as np
import os
import re
def loadDataSet(data):
ordpro_dict={}
for index ,i in data.iterrows():
if i.order_id not in ordpro_dict:
ordpro_dict[i.order_id]=[i.item_name]
else:
ordpro_dict[i.order_id].append(i.item_name)
proset=[]
for k,v in ordpro_dict.items():
proset.append(v)
return proset
def createC1(dataSet):
C1 = []
for transaction in dataSet:
for item in transaction:
if not [item] in C1:
C1.append([item])
C1.sort()
return map(frozenset, C1)#use frozen set so we
#can use it as a key in a dict
def createCK(Lk, k): #creates Ck
retList = []
lenLk = len(Lk)
for i in range(lenLk):
for j in range(i+1, lenLk):
L1 = list(Lk[i])[:k-2]; L2 = list(Lk[j])[:k-2]
L1.sort(); L2.sort()
if L1==L2: #if first k-2 elements are equal
retList.append(Lk[i] | Lk[j]) #set union
return retList
def scanD(D, Ck, minSupport):
ssCnt = {}
for tid in D:
for can in Ck:
if can.issubset(tid):
if can not in ssCnt.keys(): ssCnt[can]=1
else: ssCnt[can] += 1
numItems = float(len(D))
retList = []
supportData = {}
for key in ssCnt:
support = ssCnt[key]/numItems
if support >= minSupport:
retList.insert(0,key)
supportData[key] = support
return retList,supportData,ssCnt
if __name__=='__main__':
df1=pd.read_excel(r'C:\Users\77202\Desktop\sql\新建文件夹\apriori_items.xlsx')
proset=loadDataSet(df1)
c1_map=createC1(proset)#map
#单项频繁项集
c1=list(c1_map)
result1,sp1,ss1=scanD(proset,c1,minSupport=0.05)
spd1=pd.DataFrame.from_dict(sp1,orient='index',columns=['supportrate'])
ssd1=pd.DataFrame.from_dict(ss1,orient='index',columns=['order_cnt'])
ssd1=ssd1.reset_index().rename(columns={'index':'pro'})
ssd1['ProS']=ssd1['pro'].apply(lambda x:list(x)[0])
#二项频繁集
c2=createCK(c1,2)
#二项集关联度
result2,sp2,ss2=scanD(proset,c2,minSupport=0)
spd2=pd.DataFrame.from_dict(sp2,orient='index',columns=['supportrate'])
ssd2=pd.DataFrame.from_dict(ss2,orient='index',columns=['order_cnt'])
ssd2=ssd2.reset_index().rename(columns={'index':'proAB'})
ssd2['proA']=ssd2['proAB'].apply(lambda x:re.sub('\\[','',list(x)[0]))
ssd2['proB']=ssd2['proAB'].apply(lambda x:re.sub('\\]','',list(x)[1]))
#三项频繁集
c3=createCK(c2,3)
result3,sp3,ss3=scanD(proset,c3,minSupport=0)
spd3=pd.DataFrame.from_dict(sp3,orient='index',columns=['supportrate'])
ssd3=pd.DataFrame.from_dict(ss3,orient='index',columns=['order_cnt'])
ssd3=ssd3.reset_index().rename(columns={'index':'proABC'})
ssd3['proA']=ssd3['proABC'].apply(lambda x:re.sub('\\[','',list(x)[0]))
ssd3['proB']=ssd3['proABC'].apply(lambda x:re.sub('\\]','',list(x)[1]))
ssd3['proC']=ssd3['proABC'].apply(lambda x:re.sub('\\]','',list(x)[2]))
#sp_result=pd.concat([spd1,spd2,spd3],axis=0)
###二二组合商品相关度
result22_1=pd.merge(ssd2,ssd1,how='left',left_on='proA',right_on='ProS')
result22_2=pd.merge(result22_1,ssd1,how='left',left_on='proB',right_on='ProS')
result22=result22_2[['proA','proB','order_cnt_x','order_cnt_y','order_cnt']]
result22=result22.rename(columns={'order_cnt_x':'order_cnt_AB','order_cnt_y':'order_cnt_A','order_cnt':'order_cnt_B'})
#result22.head()
###三三组合商品相关度####
result33_1=pd.merge(ssd3,ssd1,how='left',left_on='proA',right_on='ProS')
result33_2=pd.merge(result33_1,ssd1,how='left',left_on='proB',right_on='ProS')
result33_3=pd.merge(result33_2,ssd1,how='left',left_on='proC',right_on='ProS')
resultt33=result33_3[['proA','proB','proC','order_cnt_x','order_cnt_y','order_cnt']]#需修改
#result33=result33.rename(columns={})
#数据存储,生成excel
# writer=pd.ExcelWriter(r'C:\Users\77202\Desktop\sp2.xlsx')
# sp_result.to_excel(writer)
# writer.save()
第三步,结果分析
如下图所示,麻婆豆腐+葱香烤鸡的关联度以及卷心菜+葱香烤鸡的关联度明显比较高,用户同时买这两个菜品的概率比较大,建议组套餐卖。
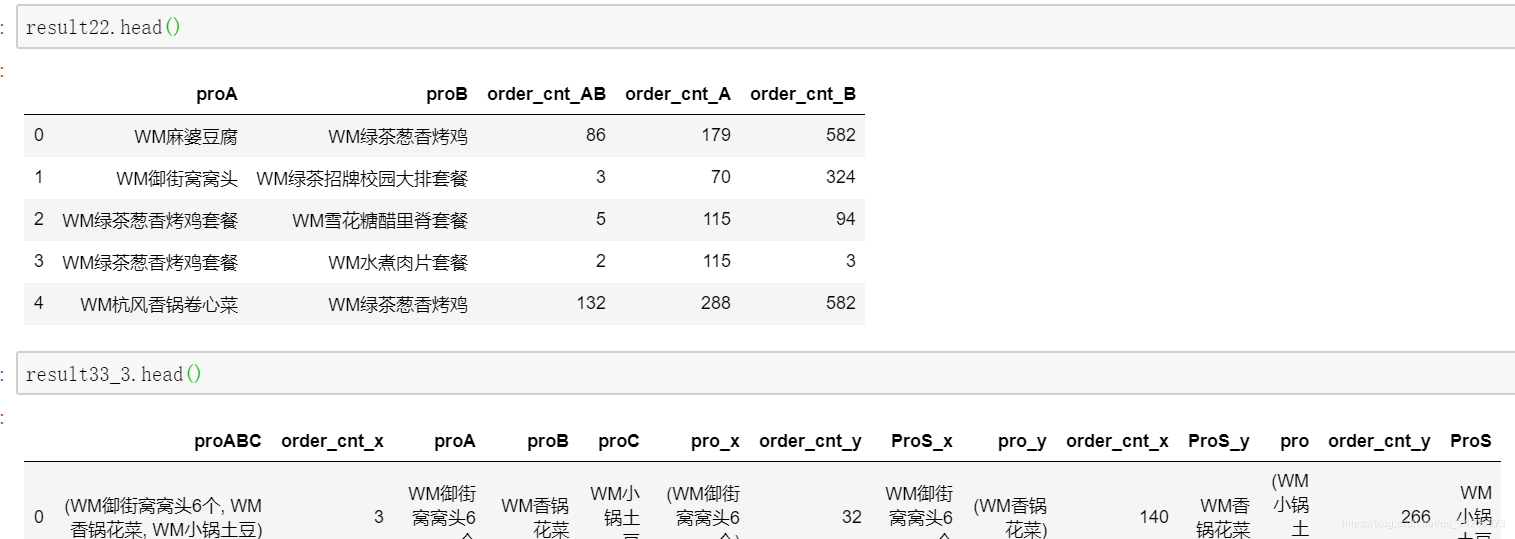
另外,其中,minsuppor参数是自己需要传入的参数,本例中使用的是0.05,可以根据情况提高该值,排除一些低关联度的商品组合。
最后,在有了菜品的二二组合和三三组合的置信度和支持度之后,再组套餐的时候我们还需要考虑菜品的价格,如果菜品A+菜品B的总价远远高于改商户的客单价水平,那么用户买的几率会特别低,同时,在组合套餐的时候我们还需要考虑具体的用户的用餐场景,因此我们要选出的是关联度高,符合用户定位的菜品,也可以加入菜品利润最大化的考虑进去。
其中支持度和Apriori相关,而置信度和提升度是下一篇寻找物品关联规则的时候会用到。

















 1162
1162

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









