






注:本文翻译自一位国外NLP在读博士Sebastian Ruder的博客。因为前一阵子知乎举办的“看山杯”比赛的第一名作者在他的比赛心得知乎“看山杯”夺冠记中提及这篇博文是对他夺冠帮助最大的两篇文章之一。对于原文中一些不是非常重要的语句,我在译文中可能并没有翻译,一切为了更方便的阅读。文章段落较多,建议读者先看目录,理清文章结构再做阅读。原文中的Task-specific best practices这里没做翻译,忙完这段时间会补全。若大家发现有翻译错误或者不妥之处,还望不吝指正。
原文地址:Deep Learning for NLP Best Practices
Introduction
这篇文章是神经网络在自然语言处理领域的最佳实践的集合。因为新的见解会不断被提出,我们对自然语言理解的程度也会不断深入,所以这篇文章也会不断被更新。
NLP社区一直有句“玩笑话”,使用一个LSTM + Attention的模型,便可以在任何NLP任务上产生state-of-the-art的表现。虽然在过去两年中一直是如此,但NLP社区开始逐渐远离这个standard baseline,并向一些更加有趣的模型进发。
然而,我们不想花费未来两年时间去发现下一个LSTM + Attention的模型,我们不想重新发明那些已经被证明是有效的技巧或者方法。虽然许多现有的深度学习库已经编码了使用神经网络的best practices,但许多其他细节,特别是在特定领域或任务上的考虑因素都留给了开发者。
本文的目的并不是想要追踪那些state-of-the-art的方法,而是收集与各种任务相关的最佳实践。换句话说,我们不会描述一个特定的模型架构,而是去收集那些能够使得模型表现得非常优秀的做法。本文的主要目的是让您快速掌握相关的最佳做法,以便尽快做出有意义的贡献。
若读者对神经网络和自然语言处理不是很了解的话,推荐阅读Yoav Goldberg的excellent primer。
Best practices
Word embeddings
Word embeddings可以说是NLP最近历史上最广为人知的优秀方法,大家都知道使用预训练的embeddings对模型很有帮助(Kim, 2014)。word embedding的最优维度要视具体任务而定,较小的维度在句法任务上表现得更好,比如命名实体识别(Melamud et al., 2016),part-of-speech (POS) tagging(Plank et al., 2016)等。而更大的维度在语义任务上更加有效,比如情感分析(Ruder et al., 2016)等。
Depth
尽管NLP领域的神经网络暂时还不能达到其在计算机视觉领域的深度,但它已经变得越来越深。State-of-the-art的方法是使用深层的Bi-LSTMs,通常由3-4层组成。例如,对于POS tagging(Plank et al., 2016),对于语义角色标注(He et al., 2017)。一些任务的模型的层次可以更深,比如Google的NMT模型有8个encoder和8个decoder层(Wu et al., 2016)。然而,在大多数情况下,使得模型深度超过2层对模型性能的提升是极小的(Reimers & Gurevych, 2017)。
这些结论适用于大多数序列标记和结构预测问题。对于分类问题,深层或者非常深层的模型仅仅在字符级输入的时候表现良好,浅层的词级模型依然是表现非常优秀的(Zhang et al., 2015; Conneau et al., 2016; Le et al., 2017)。
Layer connections
对于训练深层神经网络,一些避免梯度消失问题的技巧至关重要。已经提出了不同的层和连接, 这里我们讨论三种:1)highway layers,2)residual connections,3)dense connections.
Highway layers
Highway layers(Srivastava et al., 2015)灵感来自于LSTM的门(gates)。首先让我们假设一个一层的MLP(多层感知机),对输入x先进行一个仿射变换,后接一个非线性函数g:
h = g(Wx + b)
highway layer计算下面的函数作为替代:
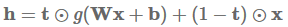
其中⊙是elementwise multiplication(对应位置元素相乘),称为转换门(transform gate),(1 - t)称为进位门(carry gate)。我们可以看到,highway layers和LSTM的gates类似,因为它们自适应地将输入的一些维度直接传递给输出。
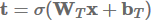
Highway layers已被主要用于实现语言建模的state-of-the-art的结果(Kim et al., 2016;Jozefowicz et al., 2016; Zilly et al., 2017),但也可用于其他任务,比如语音识别(Zhang et al., 2016)。 Sristava's page包含有关highway layers的更多信息和代码。
Residual connections
Residual connections(He et al., 2016)首先被提出用于计算机视觉 ,并且是赢得ImageNet 2016的主要因素。Residual connections比highway layers更直接,学习以下函数:
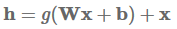
它通过一个快捷连接简单地将当前层的输入添加到其输出。这个简单的改动减轻了梯度消失问题,因为如果the layer is not beneficial,模型可以默认使用恒等函数(identity function)。
Dense connections
不仅仅是从每一层添加层到下一层,dense connections(Huang et al., 2017)(best paper award at CVPR 2017)增加了从每个层到所有后续层的直接连接。若h是层的输出,x是层的输入,l代表当前的层。Dense connections将所有先前层的级联输出作为输入提供给当前层:

Dropout
虽然计算机视觉中的batch normalization使得其他正则化器在大多数应用中都已过时,但dropout (Srivasta et al., 2014)仍然是NLP深层神经网络中的正则化器。在大多数情况下,dropout率选择为0.5已被证明很有效(Kim, 2014)。近年来,已经提出了诸如adaptive dropout(Ba & Frey, 2013)和evolutional dropout(Li et al., 2016)的dropout变体,但这些都没有被广泛应用于社区。NLP任务中阻碍dropout的主要问题是,它不能应用于循环连接,因为聚合的dropout掩码实际上会随着时间的推移将embedding清零。
Recurrent dropout
循环dropout(Gal & Ghahramani, 2016)通过在l层应用相同的dropout掩码(across timesteps)来解决这个问题。这避免了放大序列的dropout噪声,并使得序列模型能够有效的正则化。循环dropout已经被用于实现语义角色标注(He et al., 2017)和语言建模中(Melis et al., 2017)的state-of-the-art的结果。
Multi-task learning
如果有其他的数据可用,通常可以使用多任务学习(MTL)来提高目标任务的性能。了解MTL的更多信息,看看this blog post。
Auxiliary objectives
我们经常可以找到对我们关心的目标任务有用的辅助任务(Ruder, 2017)。我们已经可以使用预训练的word embeddings来预测周围的词(Mikolov et al., 2013),我们也可以在训练过程中把这作为一个辅助任务(Rei, 2017)。(Ramachandran et al., 2016)已经在sequence-to-sequence模型上应用这一想法。
Task-specific layers
虽然NLP的MTL的标准方法是hard parameter共享,但是允许模型学习特定任务的层也是有益的。可以通过将一个任务的输出层放置在更低的level上来实现(Søgaard & Goldberg, 2016)。另一种方法是induce private和共享子空间(Liu et al., 2017; Ruder et al., 2017)。
Attention
Attention最常用于sequence-to-sequence模型以关注编码器状态,但也可以用于任何序列模型以回顾过去的状态。使用attention,我们基于隐藏状态得到一个上下文向量
,可以和当前的隐藏状态
一起被用来做预测。 上下文向量
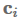
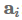

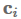
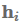
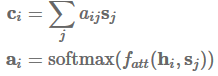
attention函数计算当前隐藏状态
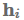
的非规范化对齐得分。接下来,我么那讨论四种attention的变体:1)additive attention 2)multiplicative attention 3)self_attention 4)key-value attention.
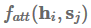

Additive attention
最初的attention机制(Bahdanau et al., 2015)使用单隐层的前馈神经网络来计算attention对齐:

其中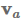

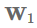
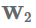
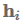
的单独转换,然后对其求和:


Multiplicative attention
乘法attention(Luong et al., 2015)通过计算以下函数简化了attention操作:

加法和乘法attention在复杂度上是相似的,尽管乘法attention在实践中更快速,更节省空间,因为它可以使用矩阵乘法来更有效地实现。两种变体在解码器状态的维度较小的时候表现差不多,但对于较大的维度,加法attention表现得更好。一种减轻这种情况的方法是通过
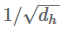
(Vaswani et al., 2017)。
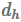
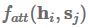
Attention不仅可以用于关注编码器或先前的隐藏状态,而且还可以获得其他特征的分布,例如用于阅读理解的文本的word embeddings(Kadlec et al., 2017)。但是,attention并不直接适用于不需要额外信息的分类任务,如情感分析。 在这样的模型中,通常使用LSTM的最终隐藏状态或诸如max pooling、averaging这样的聚合函数来获得句子表征。
Self-attention
没有任何其他信息,我们仍然可以从句子中提取相关方面,使其能够使用self-attention去关注自己(Lin et al., 2017)。Self-attention也被称为intra-attention,已经被成功应用于各种任务,包括阅读理解(Cheng et al., 2016),文字蕴涵(textual entailment)(Parikh et al., 2016)和抽象概括(abstractive summarization)(Paulus et al., 2017)。
我们可以简化加法attention,以计算每个隐藏状态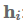
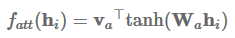
以矩阵形式,对于隐藏状态,我们可以计算attention向量
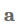
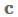
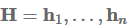

不是仅仅提取一个向量,我们可以使用矩阵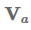
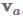
:
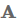

在实践中,我们执行以下正交约束来惩罚冗余,并以弗罗贝尼乌斯范数(Frobeniusnorm)平方的形式来使得attention矩阵能够更加多样:

Key-value attention
最后,key-value attention (Daniluk et al., 2017)是最近的一种attention变体,它通过单独的向量计算attention,从而separates form from function。它对不同的文档建模任务很有效。具体来说,key-value attention将每个隐藏向量分解成一个键
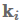
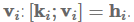
:
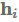

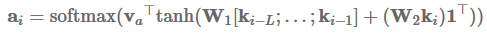
其中L是attention窗口的长度,l是一个ones的向量。然后使用这些值来获取上下文表征
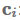
:

将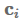
一起用来预测。
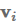
Optimization
优化算法和方案是模型的一部分,被视为黑盒。有时候,算法的轻微变化,例如减少Adam算法中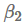
值(Dozat & Manning, 2017)都可能会对优化行为产生很大的影响。
Optimization algorithm
Adam(Kingma & Ba, 2015)是最受欢迎和广泛使用的优化算法之一,通常是NLP研究人员的优化器。通常认为Adam明显优于普通的随机梯度下降(SGD)。然而,虽然它比SGD收敛快的多,但学习率annealing(退火)的SGD略胜于Adam。最近的工作进一步表明,具有适当调整momentum(动量)的SGD比Adam表现好(Zhang et al., 2017)。
Optimization scheme
虽然Adam内部调整每个参数的学习率(Ruder, 2016),我们可以在Adam上明确地使用SGD式的退火。特别是我们可以通过重新启动进行学习率退火:我们设定学习率并训练模型直到收敛。 然后,我们将学习速度减半,并通过加载先前的最佳模型进行重新启动。 在Adam的情况下,这会使优化器忘记其参数学习率并start fresh。Denkowski & Neubig (2017)有2次重启和学习率退火的Adam更快,表现优于SGD退火。
Ensembling
若果评估模型的多样性增加,ensemble是确保结果仍然可靠的重要方法(Denkowski & Neubig, 2017)。虽然融合一个模型的不同的checkpoints已经被证明是有效的(Jean et al., 2015;Sennrich et al., 2016),但这是以牺牲模型的多样性为代价。循环的学习率有助于减轻这种影响(Huang et al., 2017)。但如果有资源可用,我们更喜欢融合多个独立训练的模型以最大化模型的多样性。
Hyperparameter optimization
LSTM tricks
Learning the initial state
我们通常使用0向量初始化初始LSTM状态。不是固定初始状态,我们可以像学习任何其他参数一样学习这个状态,这可以提升性能,也是Hinton所推荐的。这篇博文有Tensorflow的实现。
Trying input and output embeddings
输入和输出embeddings 是LSTM模型里面数量最多的参数。If the LSTM predicts words as in language modelling,则可以共享输入和输出参数(Inan et al., 2016; Press & Wolf, 2017)。这对于不允许学习大量参数的小型数据集特别有用。
Gradient norm clipping
减小梯度爆炸风险的一个方法是clip其最大值(Mikolov, 2012)。然而,这并不能一直改善效果(Reimers & Gurevych, 2017)。不是单独clip每个梯度,clip梯度的全局范数(Pascanu et al., 2013)可以产生更为显著的提升,这里是Tensorflow的实现。
Down-projection
为了进一步减少输出参数的数量,LSTM的隐藏状态可以投影到更小的尺寸。这对于具有大量输出的任务(如语言建模(Melis et al., 2017))尤其有用。
PS:原文中的Task-specific best practices这里没做翻译,忙完这段时间会补全。若大家发现有翻译错误或者不妥之处,还望不吝指正。















 769
769

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









