







回顾一下cs224d中提及的神经网络在nlp中的应用.
word2vec
A Neural Probabilistic Language Model
z在nlp任务中, 我们希望将词表达为一个向量, 而通常来说词库都会非常大, 采用one-hot 编码的话, 假设词库的容量是
V
, 那么每一个词都是一个Window besed Co-occurrence Matrix 的方法, 这种方法有几个缺点:
1. 新词加入的时候矩阵的维度要改变
2. 矩阵过于稀疏, 因为大多数词是不相关的
3. 矩阵维度过大(≈106×106)
4. 训练时间过长, o(n2)
5. 需要一些技巧来解决词频的不均衡性
我们希望通过概率模型来改进这种算法, 如Unigram, Bigram模型就假设了词与前面一或两个词的出现相关. 这种都是基于统计的角度来考虑的. 在2003年, Bengio 发表了一篇用神经网络来训练词向量的文章[1].
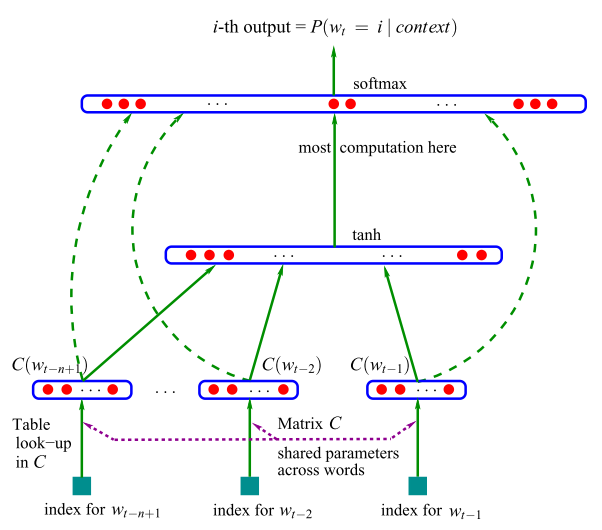
通过前面的n 个词来预测下一个词:
x 是词库矩阵 C的拼接.
通过梯度更新就可以训练到词向量了. 这个模型最终在论文所用的数据库比以前的方法在perplexity上提升了 10%−20% .
# TODO: computation complexity的表达
上面的模型的复杂之处在于hidden layer 的size, 很难在百万级别的词汇量上训练.
Distributed Representations of Words and Phrases
2013年, 两个模型横空出世, 并且得到了广泛的应用, 并且获誉一个非常cool的名字word2vec[2].
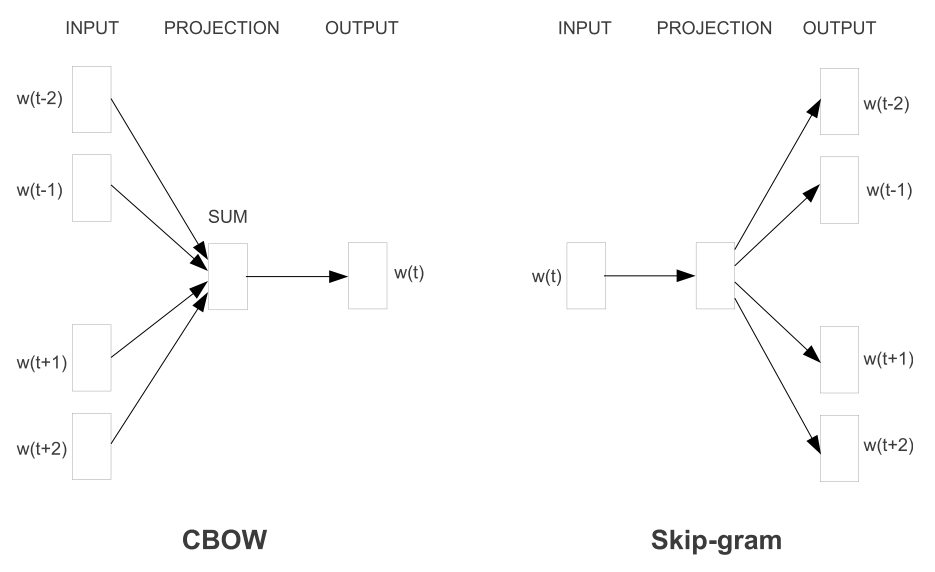
一个是continuous bag-of-words(CBOW), 另外一个是skip-gram. 这两个模型均没有hidden layer. CBOW通过context来预测current word, 而skip-gram通过current word来预测 surrounding words. 在论文的任务上, 在语法的表现上CBOW 表现的更好, 而skip-gram 在语义上表现的更好. [3] 进一步提出了negative sampling的方法来加快训练速度, 单机训练text8只需要十几十二分钟就能得到高质量的词向量.
Distributed Representations of Sentences and Documents
word2vec 的成功启发了学者将其应用到句子或者文档上, [4]通过加入文档向量的方法, 类似的提出了两种结构: Distributed memory of paragraph vectors(PV-DM) 和 Distributed Bag of Words of paragraph vectors(PV-DBOW).
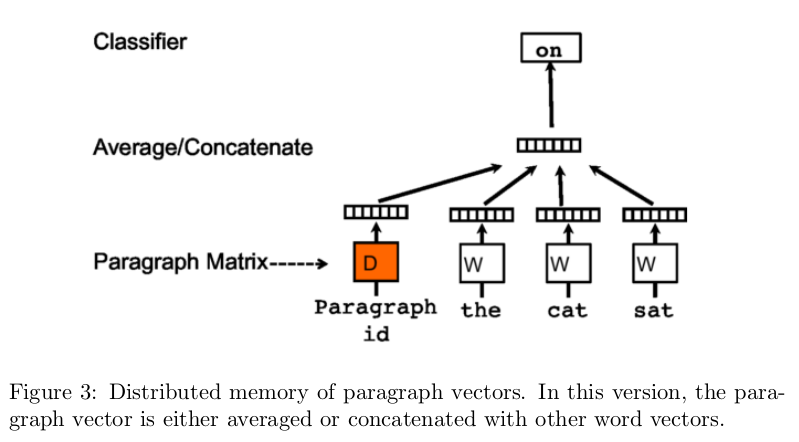
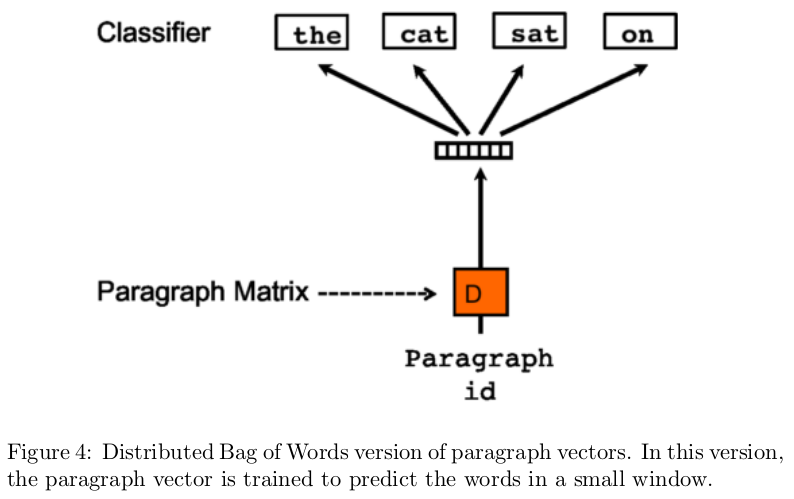
类似的, 它也有一个别称:doc2vec, 被应用在文档相似性的分析上, 效果比传统的LSI(Latent semantic indexing) 和 LDA(Latent semantic alloction)要好, 因为它考虑了词序的问题, 而不是传统的词袋模型(丢失了文档语义的理解).
Recurrent Neural Network
循环神经网络被认为是序列建模的一大利器, 它考虑了序列的上文对下面的影响, 将其应用在语言模型上是很自然的一件事情.
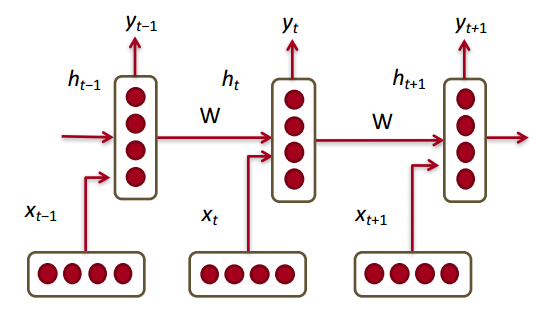
b表达式如下:
后面的LSTM和GRU都是为了解决RNN训练过程中gradient vanishing的问题, 这里就不展开了.
Recursive Neural Network
注意了, Recursive neural network和Recurrent neural network是完全不同的概念. 下面有一张Socher的课件很好的解释了它们之间的区别.
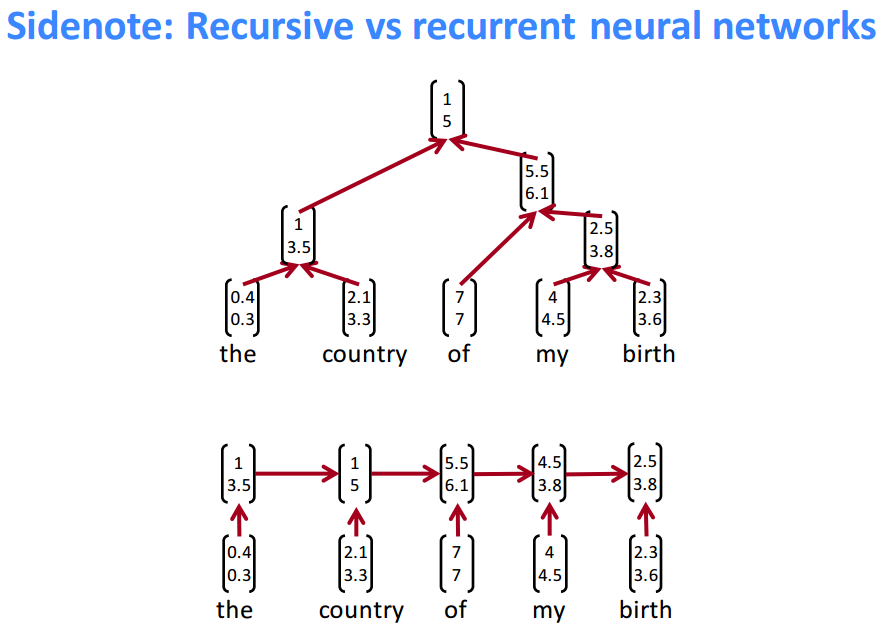
前者并没有考虑时序的问题, 而是通过树的结构将一个句子映射为向量, 而后者是一个序列问题, 每一个输入时间点对应一个词.
Rocher 成功的将递归神经网络应用到文本的情感识别中[5].
RNN: Recursive Neural Network
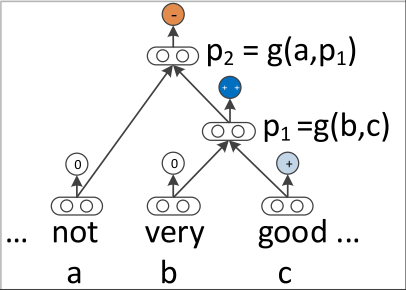
最后, 将 p2 输入到分类器中
MV-RNN: Matrix-Vector RNN
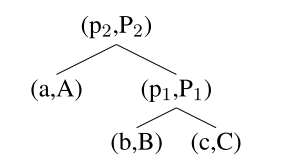
向量抓住了词的内在含义, 矩阵模拟了它是如何改变周围词或词组的含义.
RNTN: Recursive Neural Tensor Network
MV-RNN 计算量非常大, 这时候需要一个计算量比较小而又不会丢失与周围词的interaction的方法, that is RNTN.
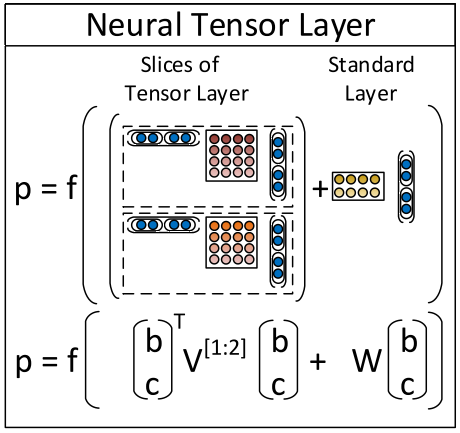
比较复杂, 好好体会.
Convolutional neural network
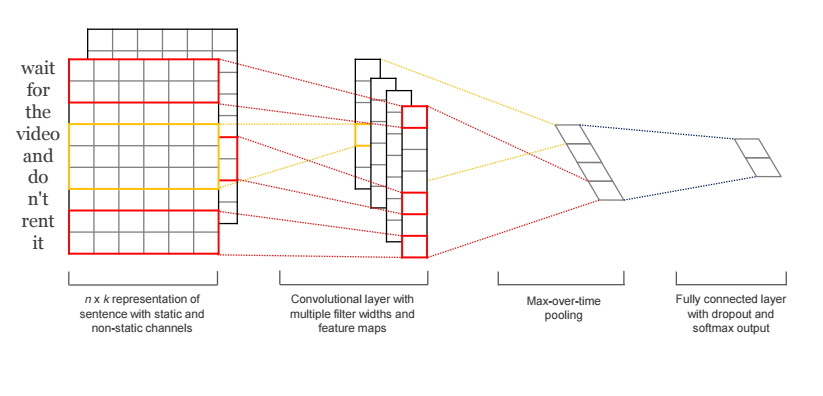
RNN 需要parser, 而CNN不用. [6]阐释了如何用CNN来对句子建模. #TODO:解释一下.
Future: Attention-based mechanism
# 补充好
Reference:
[1] Yoshua Bengio, R ́ejean Ducharme, Pascal Vincent, and Christian Janvin.A Neural Probabilistic Language Model. The Journal of Machine LearningResearch, 3:1137–1155, 2003.
[2] Tomas Mikolov, Greg Corrado, Kai Chen, and Jeffrey Dean. Efficient Estimation of Word Representations in Vector Space. Proceedings of the International Conference on Learning Representations (ICLR 2013), pages 1–12,2013
[3] Tomas Mikolov, Kai Chen, Greg Corrado, and Jeffrey Dean. Distributed Representations of Words and Phrases and their Compositionality. Nips,pages 1–9, 2013.
[4] Qv Le and Tomas Mikolov. Distributed Representations of Sentences and Documents. International Conference on Machine Learning - ICML 2014,32:1188–1196, 2014.
[5] R. Socher, A. Perelygin, and J. Wu, “Recursive deep models for semantic compositionality over a sentiment treebank,” Proceedings of the conference on empirical methods in natural language processing (EMNLP), pp. 1631–1642, 2013.
[6] N. Kalchbrenner, E. Grefenstette, and P. Blunsom, “A Convolutional Neural Network for Modelling Sentences,” Proc. 52nd Annu. Meet. Assoc. Comput. Linguist. (Volume 1 Long Pap., pp. 655–665, 2014.















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









