







转载自:
- https://mp.weixin.qq.com/s/r_PGLvkFfaWV-K7QU2xrXw
- 内核大神教你从 Linux 进程的角度看 Docker
整个分享过程中有以下几个关键词:Linux、Docker、fork、exec、task_struct、namespace 以及 dockerinit。分享内容可能比较底层,但对大家理解 Docker 的本质会很有帮助,大家要有耐心哦。
分享的内容包含三部分:
- Linux进程的基本知识;
- Docker与Linux进程的关系;
- Docker中dockerinit,entrypoint和cmd三者的关系。
Part1 Linux 进程的基本知识
这部分我们会比较基础地介绍 Linux 进程管理中的 fork、exec、进程描述符 task_struct 以及 namespace。
1 Linux 中创建进程的基本模型
Linux 操作系统中,由父进程创建并执行子进程,创建通过 fork 完成,执行通过 exec 完成。简单示意图如下:
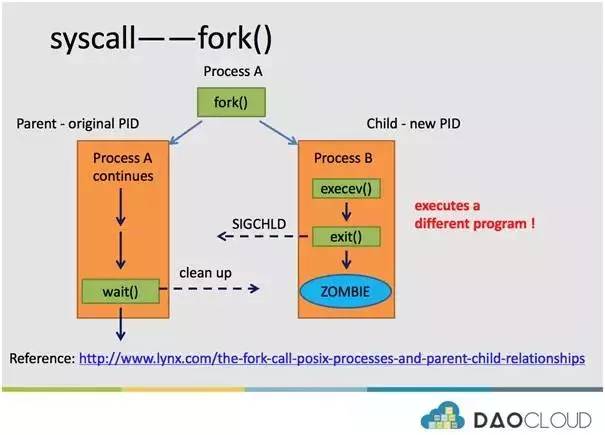
在上图中,我们看到进程 A 创建了一个新的进程 B,最终两个进程各自运行。创建时,进程 A 通过 fork 系统调用来完成。fork 之后,两个进程最大的区别就是:进程 A 依然拥有原来的 PID,新创建的进程 B 会占用一个全新的 PID,两者的 PID 不同。
并且 Linux 内核会在 fork 系统调用时,会拷贝进程 A 的 task_struct,拷贝的副本是为进程 B 准备的。完成 fork 操作之后,拥有全新 PID 的进程 B 会执行 exec 操作,保证执行新的程序,真正开始进程 B 的运行逻辑。
进程 B 运行过程中,假若 B 正常或者异常退出,那么内核就会给进程 B 的父进程 A,发送一个 SIGHOLD 信号,父进程 A 则对退出的进程 B 执行 wait 操作,实现对 B 进程资源的回收,如进程描述符 task_struct 等。
如此一来,Linux 系统中进程最基本的生命周期就完整了。大家不要觉得这和 Docker 没有什么关系,其实我也卖个关子,Docker 容器的底层实现原理,就是基于 Linux 进程的 fork 和 exec。
2 Linuxfork 的具体实现细节 do_fork
Linux 操作系统在实现 fork 时,其实更为底层的是:实现一个名为 do_fork 的函数。Do_fork 函数是在内核态,完成了新进程的创建流程。do_fork 函数的运行流程可以如下图:
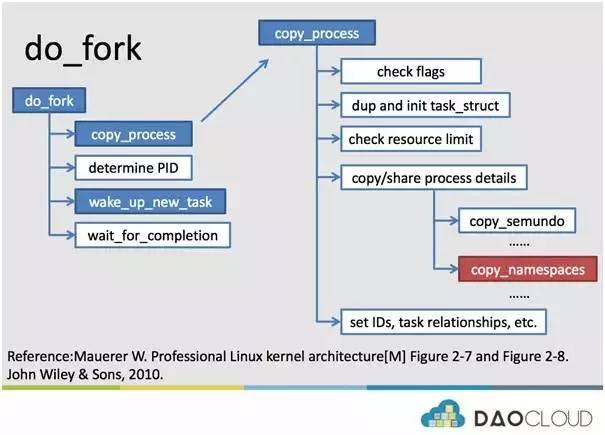
上图中,我们最关心的 Linux 内核为子进程,拷贝父进程内容的环节(copy_process)。这个环节中,Linux 会:首先,查看传入的 flag 参数,为后续是否创建新 namespace 做准备;随后,拷贝父进程的进程描述符 task_struct;接着查看系统的资源限制;而后,拷贝父进程的具体细节,这个环节也是本次分享的一个重点,因为其中涉及了命令空间的拷贝(copy_namespaces);最后,内核仍会完成一些其他操作。
在这里,我们已经多次强调了task_struct 和 namespace,那不妨对两者多做一些介绍。简单理解,task_struct 唯一地定义了一个进程的多种属性,内核调度进程时,绝大多数的信息都来源于 task_struct。
而 namespace 为进程定义了一整套的命名空间,实现不同命名空间内进程之间的完全隔离。说到隔离,Docker 就有能力实现容器间的隔离,其实最终的原理正是通过 namespace 来实现的。
这部分内容比较底层,大家可以多多揣摩一下哈。
3 task_struct 和 namespace 的关系
通俗一点来讲,Linux 内核在调度进程的时候,所有信息都来源于进程描述符 task_struct,并从 task_struct 中找到相应的命令空间信息。也就是说通过 task_struct,内核有能力找到这个进程的 namespace。
比如说:一个进程A要使用网络设备(网卡)实现网络通信。那在宿主机上有多个网络设备的时候,如何定位要具体的网络设备呢。很简单,Linux 内核首先找到进程A的进程描述符 task_struct,然后在 task_struct 中找到进程具体所在的网络命名空间(net namespace),netnamespace 中会有一个对象真正对应于具体的网络设备,那么关于改进程具体的网络通信,Linux 内核就会交给这个网络设备来完成。
看下图可以理解的更清楚:
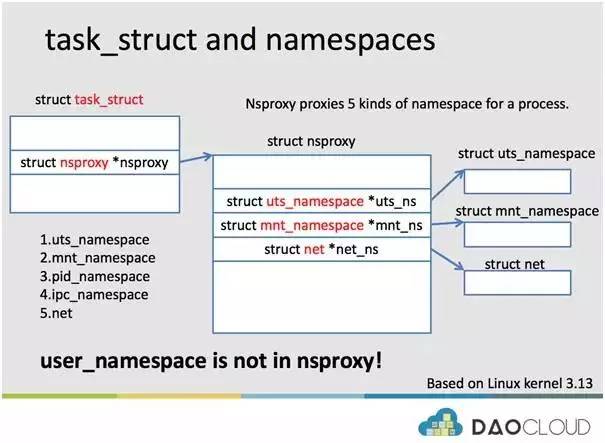
在进程描述符 task_struct 中,有一个 nsproxy 会为进程代理所有的 namespace,具体的 nsproxy 会有多个指针指向具体的 namespace。具体由 nsproxy 代理的 namespace,有:uts_namespace, mnt_namespace,pid_namespace, ipc_namespace 和net namespace。
讲了这么多的namespace,大家肯定会有疑惑,namespace中到底包含了哪些内容:
具体可以看下图哦:

比如说,pidnamespace 可以认为是为 Linux 容器完成内部进程 PID 的管理。在 pidnamespace 中,会有很多的数据结构。其中有一个属性特别重要,那就是一个名为 child_reaper 的指针,执行一个 task_struct。顾名思义,这个属性可以实现对很多子进程进程清理。这个进程一般会被认为是容器的 init 进程(pid=1),一旦这个进程退出,那么内核会给容器内其他的所有进程发送一个终止信号,确保容器的退出。
总结而言,就是容器 init 进程,决定容器的存活~
另外,像 mnt_namespace,它为容器实现了根目录的隔离视角,也就是传统意义上 chroot 的作用。该 mnt_namespace 中最重要的自然是 root 属性,定义了容器的根目录。
还有 uts_namespace,定义了容器的命名信息等。
以上的所有内容,就是为 Docker 原理准备的基本内容。总结一下,有 Linux 进程的 fork、exec、task_struct 以及 namespace。
下面,我们会来介绍 Linux 进程与 Docker 的关系。
Part2 Docker 与 Linux 进程的关系
第一部分讲了很多 Linux 进程的概念,我们今天的主题是 Docker,Docker 在哪里呢?
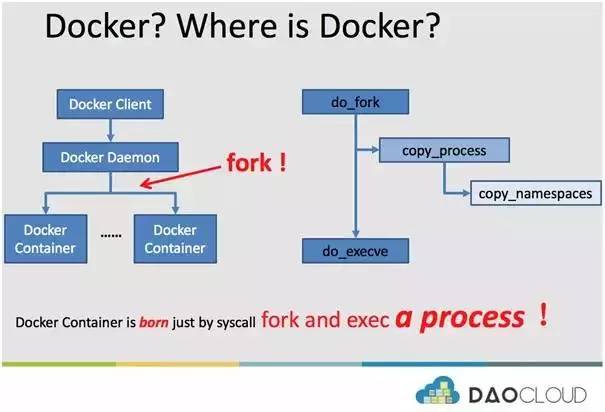
回到 Docker 最经典的三层架构:dockerclient、dockerdaemon 以及 docker container。DockerDaemon 作为守护进程管理着所有的容器,其实在创建容器的时候,DockerDaemon 仅仅是实现了一个 fork,然后在 fork 的过程中实现了 copy_namespaces。
换言之,Docker 容器的诞生仅仅是通过 fork 和 exec 一个进程而已。
具体解释原因前,我们来看看 Docker Daemon 的 fork 和我们程序员普通的 fork 有什么区别,为什么 Docker 的 fork,fork 出的是容器,而我们的却不叫容器呢?且看下图:
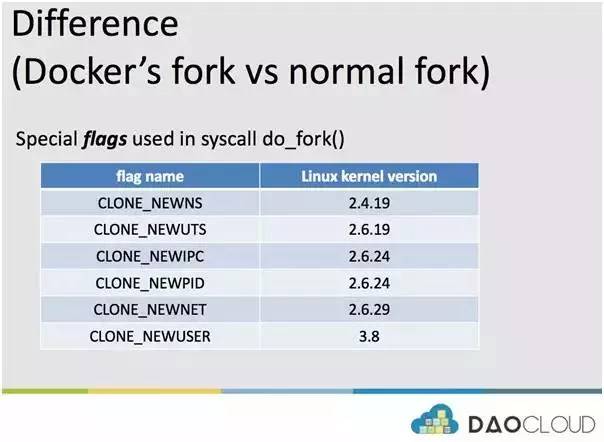
原因是 Docker Daemon 在 fork 容器进程的时候,传入了一些特殊的 flag 参数,而这些参数恰恰在内核执行 do_fork 函数时,被用来创建新的 namespace。
大家如果去看 Docker 的源码,可以发现 Docker 对于 namespace 的支持如下图:

其中 user_namespace 在 Docker 中仍然没有被支持,那说明 Docker 容器还不能支持用户 uid 的映射,容器的 root 和宿主机的 root 属于同一个 uid,均为 0。其实,这样是否会导致安全问题,肯定是大家最关心的。
回到 Docker 的 fork,DockerDaemon 一旦完成 fork,那么后面肯定还需要完成子进程的 exec。

容器进程被 fork 之后,进程描述符 task_struct 有了,新的命名空间也有了,但是进程还没有开始运行,还没有被 exec。因此,exec 的内容就是 Docker 的精髓,Docker 容器的重中之重。
Part3 Docker 中 dockerinit,entrypoint 和 cmd 三者的关系
1 dockerinit,entrypoint 和 cmd 三者的初步介绍
此时,我们进入 Docker 的很多细节部分了,围绕 Docker 容器的 exec,我们需要知道 exec 的内容到底是什么,因为 exec 的内容代表了 Docker 容器的运行逻辑到底是怎么样的。
先看下图:

Docker 的世界中,不知道大家是否听说过 dockerinit、entrypoint 和 cmd。相信大家使用 Dockerfile 打包自身应用的时候,肯定涉及过 entrypoint 和 cmd,然而一般会很少涉及到 dockerinit。
从功能的角度来介绍三者:
dockerinit:是在新 namespace 中第一个运行的内容,作用是设置新 namespace 中的挂载资源,初始化容器内的网络栈等。完成的属于容器层系统环境的初始化工作。
以网络 namespace 为例:当 DockerDaemon 创建容器时,仅仅是 fork 了一个进程,那么如何让这个进程的 net namespace 中包含一个可用的网络栈(虚拟网络设备 veth)呢?为容器内部初始化网络栈的角色就是 dockerinit,dockerinit 会获取 Docker Daemon 传递来的网络信息,并用来初始化这个容器的 net namespace。保证后续的进程拥有足够的网络能力。
entrypoint:由用户指定,完成容器内用户态配置的工作。
cmd:由用户指定,为容器的运行提供默认的参数,比如默认的运行启动入口等。
既然都属于在容器内部运行的内容,而且最终容器的角色要转移到用户指定的应用指定 cmd,而容器内的进程只有一个 init 进程(pid=1),那么 dockerinit、entrypoint 和 cmd 三者与容器 init 进程之间的关系,会非常重要,毕竟 init 进程决定的容器的生命状态。
更为清晰的 Docker 容器进程图如下,其中包含 dockerinit、entrypoint 以及 cmd:
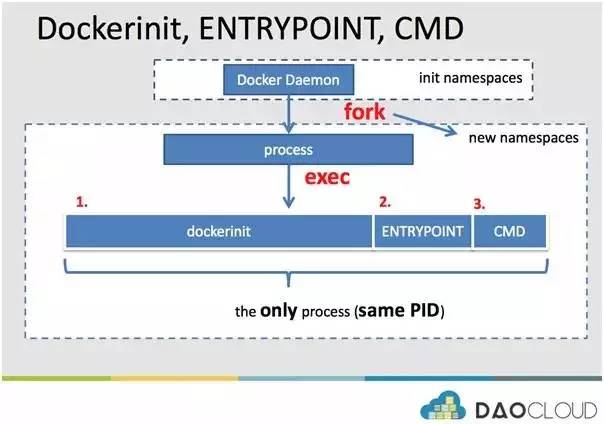
大家可以看到容器进程被 fork 出来之后,实现 exec 的时候,第一部分直接 exec 的是 dockerinit,而后是 entrypoint,最后是 cmd。
图中有一个非常重要的点是,三部分的内容会占用同一个 PID,整个流程不会有新的 pid 诞生。原因很简单,那就是 dockerinit 执行 entrypoint 的时候,使用的也是 exec 操作,确保进程 PID 不变,进程执行程序切换到 entrypoint。Entrypoint 到 cmd 的过程,原理也是如此。
流程的角度来讲,最终容器的 init进程(pid=1)的角色能满足最终嫁接到用户指定应用的 cmd 处。当然图中也显示了,整个容器都处于全新的 namespace 中,也就是说容器与容器,容器与宿主机之间都是可以实现隔离的。
2 DockerDaemon 与 dockerinit
DockerDaemon 作为 fork 容器进程的发起者,自然是父进程,而 dockerinit 作为容器内第一个执行的内容,自然是子进程。其实在父子进程之间,还存在一些细枝末节,值得大家去深思与玩味。
简言之,Docker Daemon 与 dockerinit 还存在一些数据的交互。大家还记得 dockerinit 的作用吗?初始化新建的 namespace 内的一些重要资源。但是这些资源呢,又是 Docker Daemon 在宿主机上申请的,比如说虚拟网络设备对(veth pair)。DockerDaemon 在原始的命名空间中创建了这些内容之后,需要一种方式,把网络设备对的一个 veth 交给容器,那就是交给 dockerinit。
DockerDaemon 与 dockerinit 具体的通信形式如下:
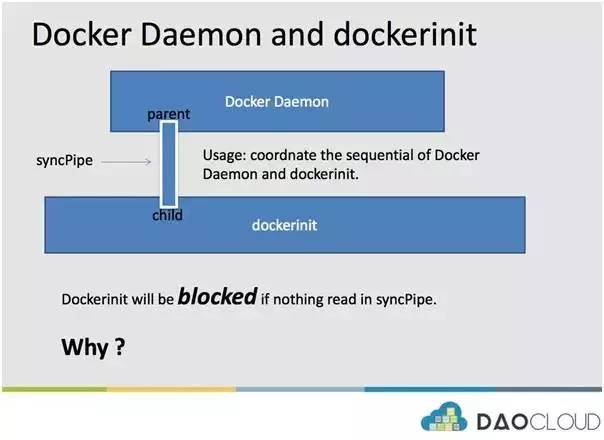
看上图,我们可以发现最重要的字眼有两个:syncPipe 与 blocked。
前者可以称为同步管道,作用是协调 Docker Daemon 和 dockerinit 的运行顺序。
后者指的是:dockerinit 的运行会被阻塞住,直 dockerinit 从同步管道 syncPipe 中读到内容为止。
接下来,我们就详细介绍阻塞的原因与两者的协作运行的情况。
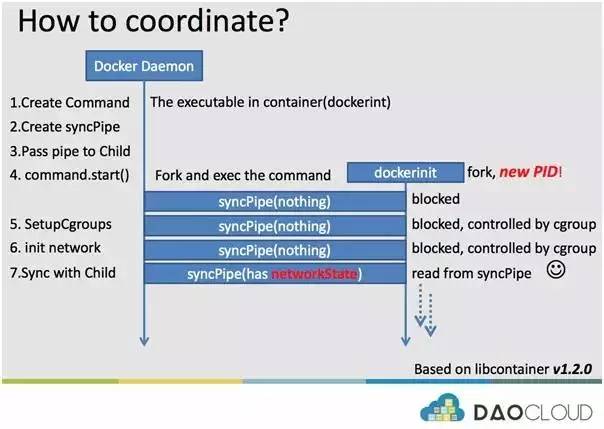
上图中,左边代表 Docker Daemon 的运行流程,右边代表 dockerinit 的运行流程。现在,我们一步一步详细介绍两者的运行流程,以便深入了解 Docker 容器的原理。
Docker Daemon 的流程如下:
- Create Command 创建容器的执行程序,也就是为 Docker 容器 exec 的内容,当然这部分内容自然是 dockerinit,毕竟 dockerinit 是 Docker 容器内第一个执行的内容。
- 创建一个同步管道 syncPipe,自然是为了和马上要创建的 dockerinit 建立通信。
- 将同步管道 syncPipe 的一端以文件描述符的形式,为即将创建的子进程准备。
- 执行 command.Start(),也就是完成 fork 和 exec 两个步骤,此时 dockerinit 进程会以一个全新 PID 来运行,但是 dockerinit 由于自身程序逻辑的原因,由于同步管道 syncPipe 中没有内容,因此会被阻塞(block)住。
- DockerDaemon 为 dockerinit 设置 cgroups,保证 dockerinit 进程以及以后 dockerinit fork 出的子进程设置资源限制。此时 dockerinit 仍然处于阻塞状态。
- Docker Daemon 为容器初始化网络,在宿主机的 namespace 下创建一个虚拟网络设备对(veth pair)。此时 dockerinit 仍然处于阻塞状态。
- DockerDaemon 开始将网络设备的一端(veth)放入同步管道 syncPipe,开始与容器进程 dockerinit 实现同步。此时,dockerinit 读取到同步管道 syncPipe 中的内容,不再阻塞,开始运行自身的逻辑。(容器活啦!)
以上7个步骤,属于 docker daemon 的运行逻辑,理解一下,下面就要 dockerinit 啦。
既然 Docker 容器已经开始活了,那我们从 dockerinit 的角度来看看容器做了一些什么操作。
如下图:
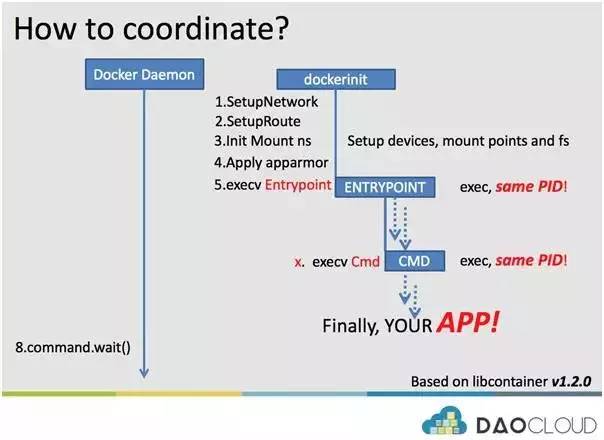
dockerinit 的运行流程如下:
- 初始化网络,也就是说把 Docker Daemon 通过同步管道传输来网络设备信息(veth)作为初始化自身 net namespace 的依据,完成配置,使得容器有独立的网络栈。
- 设置路由等,容器内部也会存在路由记录,dockerinit 会实现配置。
- Mnt namespace 的根目录配置。
- Apparmor 或者 SELinux的安全配置。
- 完成那些容器层系统配置之后,重要的内容来了。开始 exec entrypoint,在 PID 不变的情况下,开始执行 entrypoint。
- Entrypoint 在执行过程中,完成了执行命令之后,最后一步会实现 exec Cmd,在 PID 不变的情况下,开始执行 Cmd。
- Cmd 一般就是用户指定的应用程序。这个时候,就是在运行用户的应用程序啦。Docker 容器的 init 进程(pid=1)开始由用户指定的应用 Cmd 接管。
用户指定的应用,也就是 cmd,是容器的主进程,决定容器的存活。是不是很奇妙?
3 Docker 容器的真实形态
如果上述流程都走通的话,我们来看看 Docker 容器的真实形态。Docker 容器的基本架构可以参见下图:
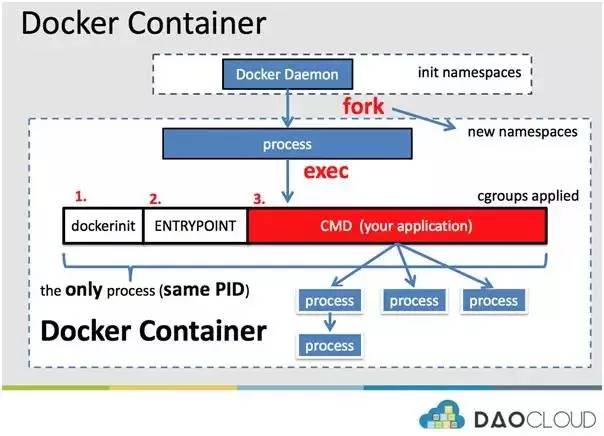
上图中,会有几个点,大家注意下:
- Docker Daemon与Docker容器的关系。
- Dockerinit,entrypoint以及cmd的关系
- Docker容器内进程最终呈现的树状关系图
- 容器处于新的namespace,实现隔离
- 容器受到cgroups的作用,实现资源限制
You havemastered the root theory of Docker Container .
总结本次分享
- 介绍 Linux 操作系统中进程管理的一些基本概念,如下 fork、exec、task_struct 和 namespace等;
- 如何看待 Docker 容器与 Linux 进程的一些关系;
- 详细介绍 Docker Daemon 与 Docker 容器的细节关系,最终给大家展现 Docker 容器的本质框架图。
彩蛋——问答环节:
父进程问题会不会造成僵尸子进程,docker Desmond?
僵尸进程的问题,Docker 容器是会存在的。原因主要是:Docker 容器的 init 进程和宿主机上的 init 进程,在运行逻辑上存在很大的差异,它没有能力去 wait 其他父进程先退出的子进程。
Fork 过程中是否可以把其他命名空间挂进来实现,例如其他容器命名空间?
这个问题的答案是完全可以。这个属于 Docker 中的高级功能了,比如说 kubernetes 中的 pod 概念,就是让一个 Docker 容器的 net namespace给pod 内的其他容器挂。
Docker 对于安全,网络,存储,备份,是怎么处理的?
安全方面,我觉得目前市面上用 docker 的安全隐患可能存在两点:
- 是使用方式存在安全,这一点不容小觑,比如说不支持 docker 的一些特性,采用一些不安全,不加密,不受信的方式;
- docker 本质存在的安全,主要还是存在于 Docker 容器和宿主机共享内存的缘故,内核态的一些数据结构资源很难做到很好的隔离。
网络的话,大家经常提,关键问题是:Docker 的网络到底应该由谁来完成,是不是应该由 docker 这个二进制文件内部逻辑来完成?其实未必,更多的要从 Docker 生态来看这个问题,价值会更大,这个话题不展开了。
刚才提到为什么很难隔离。我简单说一下。大家可能认为隔离的物理资源,计算资源,是一个比较好的方式。但是共享同一个 Linux 内核,会导致一些内核态的资源无法隔离,简单一点,linux 内核管理的文件描述符资源,inotify 总数资源,pid 总数资源,都是需要考虑的点;还有 uid 权限的问题,其实都和无力资源无关,都属于内核资源。
讲讲 kvm 与 docker 的区别,有人说 docker 会替代 kvm,你是如何理解这句话的?
既然会回归到隔离问题,那么替代一说,我觉得 5 年内很难实现吧,但是 docker 的诞生会侵蚀 KVM 或者说虚拟机很多的应用场景。
在一台机器上模拟并发多个 dockerpush,daemon 是不是有什么限制,让 push 的过程是串行的?因为观察到,在一台机器上增大 docker push 的并发数,并没有增加机器上的资源的消耗而只是延长了 push 的时间。
在一台机器上模拟并发多个 dockerpush,daemon 是不是有什么限制,让 push 的过程是串行的?因为观察到,在一台机器上增大 docker push 的并发数,并没有增加机器上的资源的消耗而只是延长了 push 的时间。
这个问题,可能就比较难说了。如果说是 push 多个完全没有任何镜像关系的镜像,那么理论上应该是可以实现并发的。加入 push 的镜像存在共有镜像的话,那么 docker daemon 不会并发执行。
是不是完全可以认为 docker 容器的进程完全符合一个 Linux 普通进程的特性?
可以这么理解吧,但是容器进程额外的东西才是最重要的嘛。隔离的环境,受限的资源,受限的权限等。
原文参考:https://mp.weixin.qq.com/s/r_PGLvkFfaWV-K7QU2xrXw (版权归原作者所有,侵删)















 8309
8309











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









