







kNN(k-nearest neighbors algorithm)
这是一个简单粗暴的分类器(
Classifier)算法,分类效果不错,但是对于异常值不敏感,而且算法的复杂度高,每次计算都要遍历整个训练集(Training Data Set),效率不高.

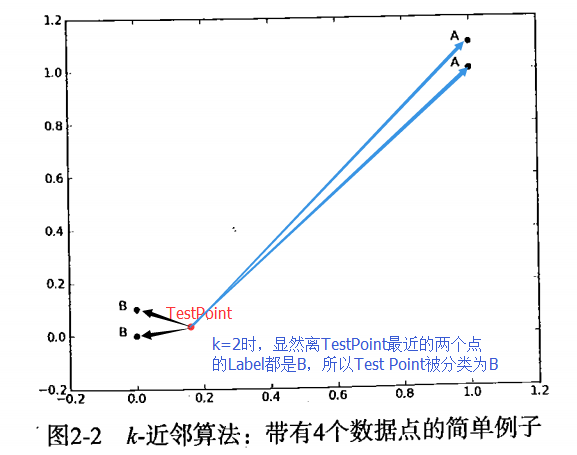
距离量度相似性 #1
kNN算法的思想就是把整个训练集在依照特征值坐标轴标定后,把测试量标定到特征值空间后,计算测试量与所有训练数据的距离,按照距离从小到大排列,选取距离最小的k个训练点,统计这k个点的Labels数量最多的Label就是kNN得到的分类结果(简单说,就是测试量和训练集的哪个(些)量最相似)。
归一化不同特征量距离 #2
考虑两组特征量(A、B),A的数量级为1,B的数量级为100000,当用距离来衡量相似性时,B的大小远大于A,所以只有B在起作用,A被忽略了,然而我们是想A、B的权重一样的,所以我们要把A、B归一化,以使得A、B一起决定距离.
归一化公式:
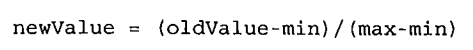
python 代码如下:
def autoNorm(dataSet):
minVals = dataSet.min(0)
maxVals = dataSet.max(0)
ranges = maxVals - minVals
normDataSet = zeros(shape(dataSet))
m = dataSet.shape[0]
normDataSet = (dataSet-tile(minVals, (m,1)))/tile(ranges, (m,1))
return normDataSet, ranges, minVals算法构建与应用 #3
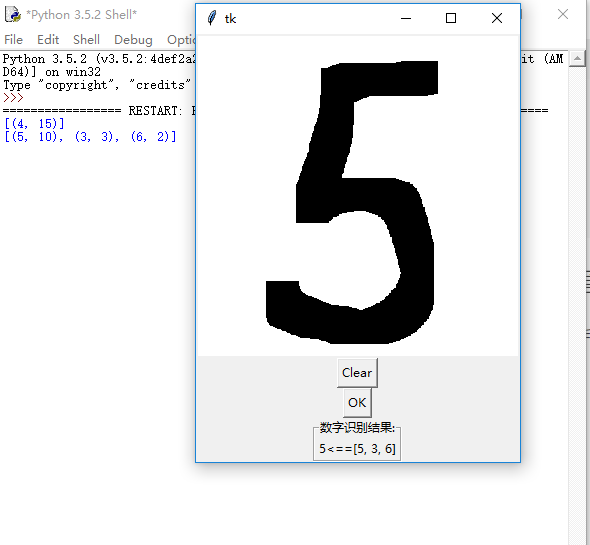
手写数字识别demo:
相关参数:
k=15
2.3M训练集数据
准确度较高(与训练集和个人书写习惯相关性大)
















 7109
7109

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









