







k-近邻法概述

工作原理:
存在一个样本数据集合,也称作训练样本集,并且样本集中每个数据都存在标签,即我们知道样本集中每一数据与所属分类的对应关系。输人没有标签的新数据后,将新数据的每个特征与样本集中数据对应的特征进行比较,然后算法提取样本集中特征最相似数据(最近邻)的分类标签。一般来说,我们只选择样本数据集中前&个最相似的数据,这就是k-近邻算法中k的出处,通常k是不大于20的整数。最后,选择k个最相似数据中出现次数最多的分类,作为新数据的分类。
k-近邻算法的一般流程


从文本文件中解析数据
k-近邻算法:

预测[0,0]所在分类:

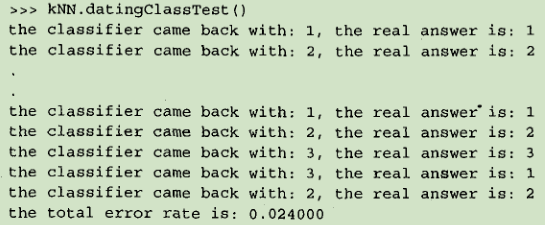
测试分类器
为了测试分类器的效果,我们可以使用已知答案的数据,当然答案不能告诉分类器,检验分类器给出的结果是否符合预期结果。通过大量的测试数据,我们可以得到分类器的错误率—分类器给出错误结果的次数除以测试执行的总数。错误率是常用的评估方法,主要用于评估分类器在某个数据集上的执行效果。完美分类器的错误率为0,最差分类器的错误率是1.0,在这种情况下,分类器根本就无法找到一个正确答案。
示例:使用k-近邻算法改进约会网站的配对效果


准备数据:从文本中解析数据

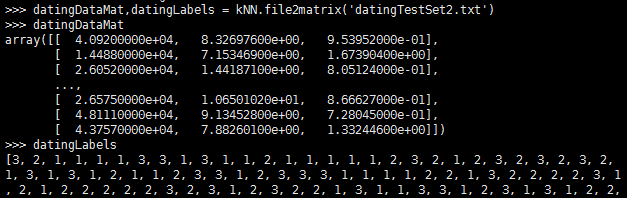
数据准备:归一化数值
计算样本之间距离时,数字差值最大的属性对计算结果的影响最大,所以在处理不同取值范围的特征值时,我们通常采用的方法是将数值归一化,如将取值范围处理为0到1或者-1到1之间。下面的公式可以将任意取值范围的特征值转化为0到1区间内的值:newValue={oldValue-min)/(max-min)。其中min和max分别是数据集中的最小特征值和最大特征值。虽然改变数值取值范围增加了分类器的复杂度,但为了得到准确结果,我们必须这样做。

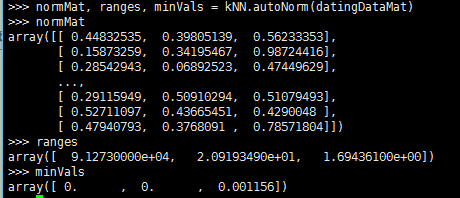
测试算法:作为完整程序验证分类器
分类器针对约会网站的测试代码:

示例:手写识别系统
这里构造的系统只能识别数字0-9,需要识别的数字已经使用图形处理软件,处理成具有相同的色彩和大小:宽髙是32像 素 x 32像素的黑白图像。



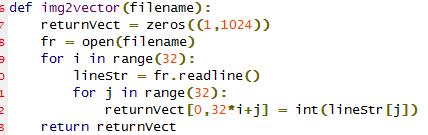
准备数据:将图像转换为测试向量
我们使用目录trainingDigits中的数据训练分类器,使用目录testDigits中的数据测试分类器的效果。
我们将把一个32x32的二进制图像矩阵转换为1 x 1024的向量。

手写数字识别系统的测试代码:



k-近邻算法识别手写数字数据集,错误率为1.2%。改变变量k的值、修改函数handwritingClassTest随机选取训练样本、改变训练样本的数目,都会对k-近邻算法的错误率产生影响,感兴趣的话可以改变这些变量值,观察错误率的变化。
小结
k-近邻算法是分类数据最简单最有效的算法。k-近邻算法是基于实例的学习,使用算法时我们必须有接近实际数据的训练样本数据。k-近邻算法必须保存全部数据集,如果训练数据集的很大,必须使用大量的存储空间。此外,由于必须对数据集中的每个数据计算距离值,实际使用时可能非常耗时。
k-近邻算法的另一个缺陷是它无法给出任何数据的基础结构信息,因此我们也无法知晓平均实例样本和典型实例样本具有什么特征。















 1295
1295











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









