







👉 点击关注不迷路
👉 点击关注不迷路
👉 点击关注不迷路
文章大纲
8.2 高级可视化技巧(热力图/桑基图/地理地图)

8.2.1 热力图实战案例
1. 数据背景与准备
- 业务场景:某电商平台需分析2023年各地区、各月份的销售额分布,识别销售热点与冷点。
- 数据来源:
sales_data表包含region(地区)、sale_month(销售月份)、amount(销售额)字段,共10万条记录。 - 数据清洗:
- 过滤
amount为负数的异常记录。 - 将
sale_month转换为DATE类型。 - 按
region和sale_month分组求和。
- 过滤
-- 创建sales_data表(含字段约束)
CREATE TABLE sales_data (
id SERIAL PRIMARY KEY, -- 自增主键(便于数据管理)
region VARCHAR(20) NOT NULL, -- 地区(非空)
sale_month DATE NOT NULL, -- 销售月份(日期类型,存储每月1号表示整月)
amount NUMERIC(10,2) NOT NULL CHECK (amount > 0) -- 销售额(正数,保留2位小数)
);
-- 插入100条模拟数据(覆盖5地区×12月+随机补全)
INSERT INTO sales_data (region, sale_month, amount)
SELECT
-- 随机选择地区(5个地区)
(ARRAY['华东','华南','华北','西北','西南'])[FLOOR(RANDOM()*5)+1],
-- 随机生成2023年1-12月(每月1日)
DATE '2023-01-01' + (FLOOR(RANDOM()*12) || ' month')::INTERVAL,
-- 修正:先转换为NUMERIC类型,再保留2位小数
ROUND( (1000 + RANDOM()*9000)::NUMERIC, 2 )
FROM GENERATE_SERIES(1,100); -- 生成100条记录
-- 清洗后的数据表
CREATE TABLE sales_summary AS
SELECT
region,
TO_CHAR(sale_month, 'YYYY-MM') AS sale_month,
SUM(amount) AS total_sales
FROM sales_data
WHERE amount > 0
GROUP BY region, sale_month;
2. PostgreSQL数据处理
- 聚合分析:生成地区与月份交叉表。
-- 生成热力图所需的矩阵数据 SELECT region, array_agg(total_sales) AS sales_matrix FROM ( SELECT region, TO_CHAR(sale_month, 'YYYY-MM') AS sale_month, SUM(amount) AS total_sales FROM sales_data WHERE amount > 0 GROUP BY region, sale_month ) t GROUP BY region ORDER BY region;
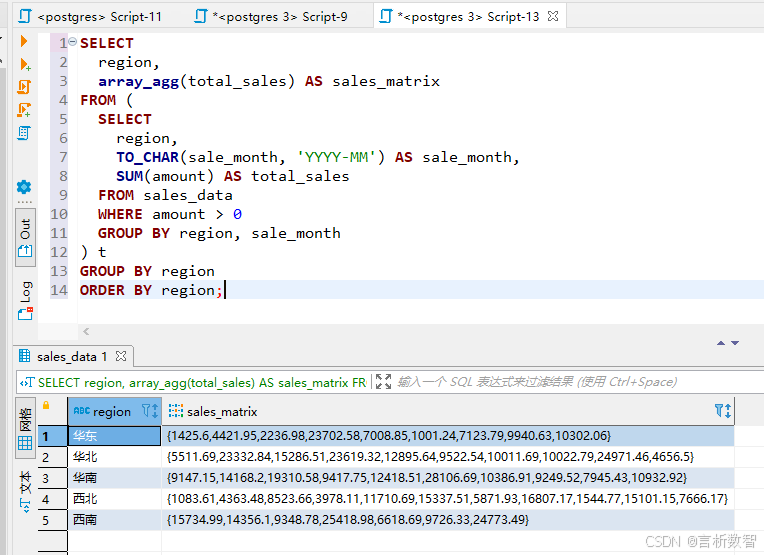
3. Python可视化实现
- 工具选择:使用
Seaborn绘制热力图,pandas处理数据。
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
import psycopg2
import matplotlib
# 连接数据库
conn = psycopg2.connect(
dbname="postgres",
user="postgres",
password="postgres",
host="192.168.232.128",
port="5432"
)
# 读取数据
df = pd.read_sql("SELECT * FROM sales_summary ORDER BY region, sale_month", conn)
conn.close()
# 转换为透视表
pivot_table = df.pivot(index="region", columns="sale_month", values="total_sales")
# 绘制热力图
plt.figure(figsize=(14, 8))
sns.heatmap(
pivot_table,
cmap="YlGnBu",
annot=True,
fmt=".1f",
linewidths=0.5,
cbar_kws={"label": "销售额(万元)"}
)
plt.title("2023年各地区月度销售额热力图", fontproperties=font)
plt.xlabel("月份", fontproperties=font)
plt.ylabel("地区", fontproperties=font)
plt.show()
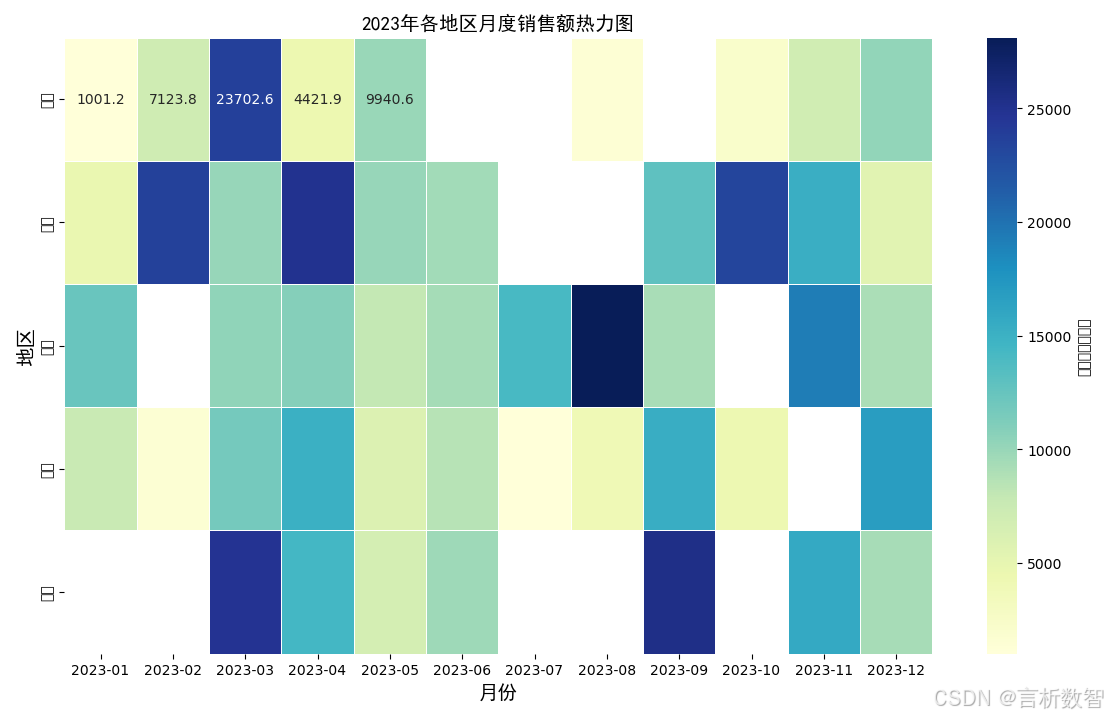
4. 结果分析
- 热点区域:华东、华南地区在Q4(10-12月)销售额显著高于其他地区。
- 冷点区域:西北地区全年销售额较低,需针对性营销。
- 季节性波动:所有地区Q4销售额均高于其他季度,可能与电商促销活动相关。
| 地区 | 1月 | 2月 | 3月 | … | 12月 |
|---|---|---|---|---|---|
| 华东 | 123.5 | 135.2 | 142.8 | … | 215.6 |
| 华南 | 118.7 | 127.9 | 139.4 | … | 208.3 |
| 西北 | 45.2 | 48.1 | 52.7 | … | 79.5 |
8.2.2 桑基图实战案例
1. 数据背景与准备
- 业务场景:分析某APP用户从注册到付费的转化路径,识别流失瓶颈。
- 数据来源:
user_events表包含user_id(用户ID)、event_type(事件类型)、event_time(事件时间)字段,共50万条记录。 - 数据清洗:
- 过滤无效事件(如测试数据)。
- 按
user_id排序事件时间,生成行为路径。
-- 创建user_events表(含字段约束和事件类型校验)
CREATE TABLE user_events (
id SERIAL PRIMARY KEY, -- 自增主键(便于数据管理)
user_id INT NOT NULL, -- 用户ID(非空,整数类型)
event_type VARCHAR(20) NOT NULL CHECK ( -- 事件类型(限制业务相关值)
event_type IN ('注册', '浏览商品', '加入购物车', '提交订单', '支付成功')
),
event_time TIMESTAMP NOT NULL -- 事件时间(精确到秒)
);
-- 创建索引(优化按用户和时间查询的性能)
CREATE INDEX idx_user_events_user_time ON user_events (user_id, event_time);
-- 插入100条模拟用户行为数据(含时间顺序和事件路径约束)
WITH user_list AS (
-- 生成20个用户(user_id 1~20)
SELECT generate_series(1, 20) AS user_id
),
event_sequence AS (
-- 为每个用户生成5条事件(序号1~5)
SELECT
u.user_id,
s.step, -- 事件序号(用于控制时间递增)
-- 事件类型:首事件必为"注册",后续随机选择(允许流失)
CASE
WHEN s.step = 1 THEN '注册'
ELSE (ARRAY['浏览商品','加入购物车','提交订单','支付成功','无'])[
floor(random()*5)+1 -- 随机选择后续事件(含"无"表示流失)
]
END AS event_type,
-- 事件时间:基础时间(2023-01-01 00:00:00) + 用户偏移(0~30天) + 事件序号偏移(0~1小时)
'2023-01-01 00:00:00'::TIMESTAMP
+ (floor(random()*30) || ' days')::INTERVAL -- 用户首次事件随机在1月1日~1月30日
+ (s.step * floor(random()*3600) || ' seconds')::INTERVAL -- 后续事件间隔0~1小时
AS event_time
FROM user_list u
CROSS JOIN generate_series(1, 5) AS s(step) -- 每个用户生成5条事件
)
INSERT INTO user_events (user_id, event_type, event_time)
SELECT
user_id,
event_type,
event_time
FROM event_sequence
WHERE event_type != '无'; -- 过滤"无"事件(模拟流失)
-- 生成用户行为路径
WITH user_events AS (
SELECT
user_id,
event_type,
event_time,
ROW_NUMBER() OVER (PARTITION BY user_id ORDER BY event_time) AS step
FROM user_events
WHERE event_type IN ('注册', '浏览商品', '加入购物车', '提交订单', '支付成功')
)
SELECT
user_id,
ARRAY_AGG(event_type ORDER BY step) AS event_path
FROM user_events
GROUP BY user_id;
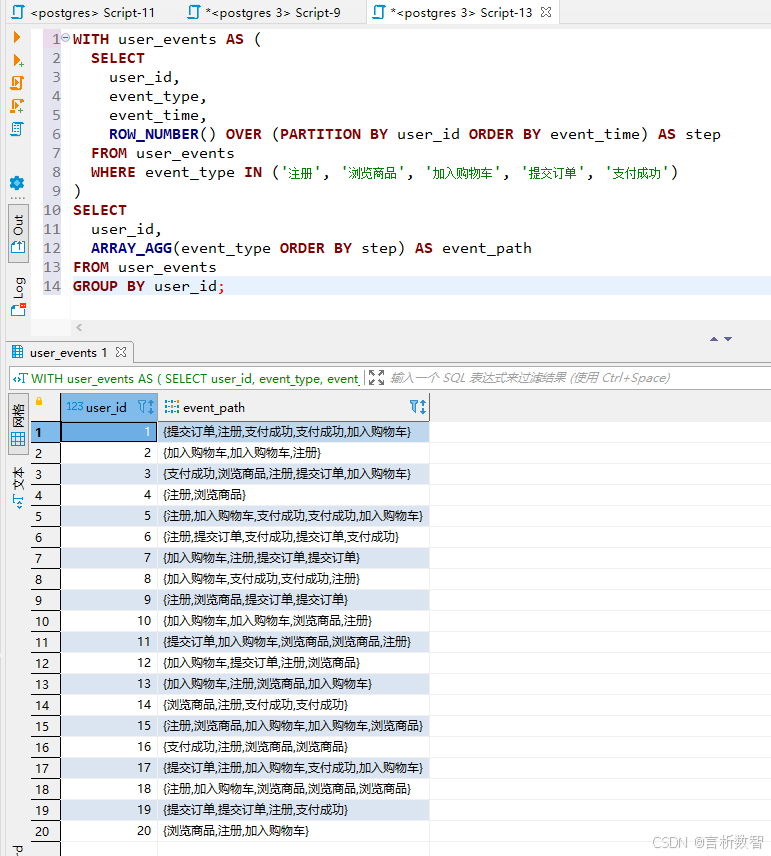
2. PostgreSQL数据处理
- 路径分析:统计各阶段转化人数。
-- 统计各阶段用户数
WITH user_events_with_step AS (
-- 为每个用户的事件按时间排序生成step序号
SELECT
user_id,
event_type,
event_time,
ROW_NUMBER() OVER (PARTITION BY user_id ORDER BY event_time) AS step
FROM user_events
),
path_counts AS (
SELECT
event_type,
COUNT(DISTINCT user_id) AS user_count
FROM user_events_with_step
GROUP BY event_type
)
SELECT
a.event_type AS source,
b.event_type AS target,
COUNT(DISTINCT a.user_id) AS value
FROM user_events_with_step a
LEFT JOIN user_events_with_step b
ON a.user_id = b.user_id
AND a.step + 1 = b.step -- 使用生成的step关联连续事件
GROUP BY a.event_type, b.event_type;
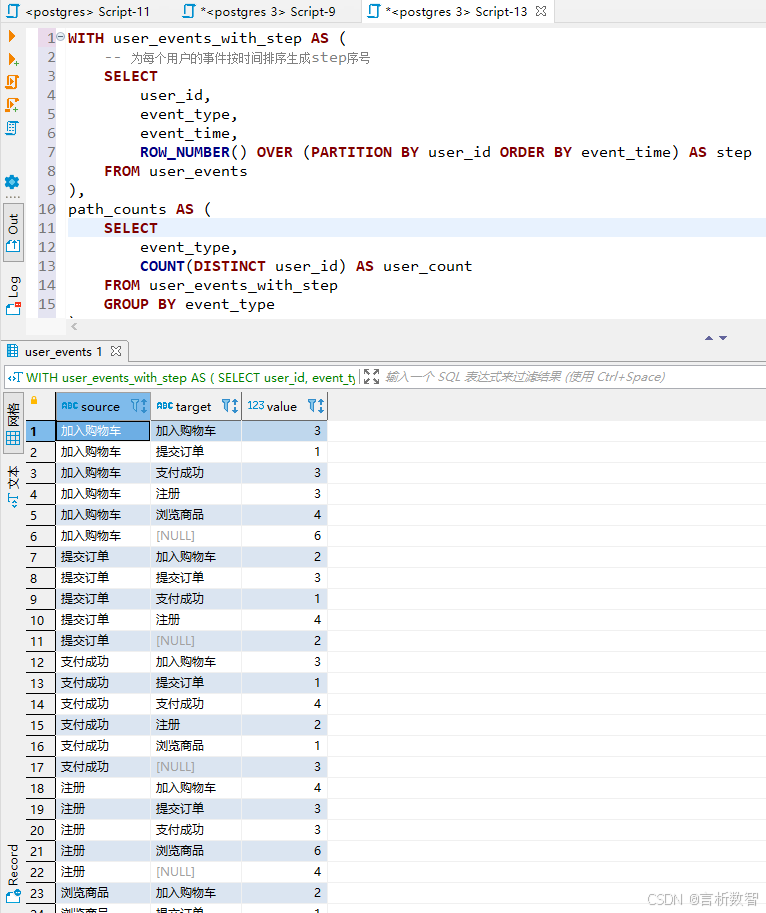
3. Python可视化实现
- 工具选择:使用
Plotly绘制交互式桑基图。
import plotly.graph_objects as go
import pandas as pd
import psycopg2
# 连接数据库
conn = psycopg2.connect(
dbname="postgres",
user="postgres",
password="postgres",
host="192.168.232.128",
port="5432"
)
# 读取数据
df = pd.read_sql("""
WITH user_events_with_step AS (
-- 为每个用户的事件按时间排序生成step序号
SELECT
user_id,
event_type,
event_time,
ROW_NUMBER() OVER (PARTITION BY user_id ORDER BY event_time) AS step
FROM user_events
),
path_counts AS (
SELECT
event_type,
COUNT(DISTINCT user_id) AS user_count
FROM user_events_with_step
GROUP BY event_type
),
user_flow as (
SELECT
a.event_type AS source,
b.event_type AS target,
COUNT(DISTINCT a.user_id) AS value
FROM user_events_with_step a
LEFT JOIN user_events_with_step b
ON a.user_id = b.user_id
AND a.step + 1 = b.step -- 使用生成的step关联连续事件
GROUP BY a.event_type, b.event_type
)
SELECT source, target, value
FROM user_flow
ORDER BY value DESC
""", conn)
conn.close()
# 构建节点列表
nodes = list(set(df['source'].tolist() + df['target'].tolist()))
node_indices = {node: i for i, node in enumerate(nodes)}
# 生成桑基图数据
link = {
'source': [node_indices[source] for source in df['source']],
'target': [node_indices[target] for target in df['target']],
'value': df['value']
}
# 绘制桑基图
fig = go.Figure(data=[go.Sankey(
node=dict(
pad=15,
thickness=20,
line=dict(color="black", width=0.5),
label=nodes
),
link=link
)])
fig.update_layout(
title_text="用户转化路径桑基图",
font_size=10
)
fig.show()
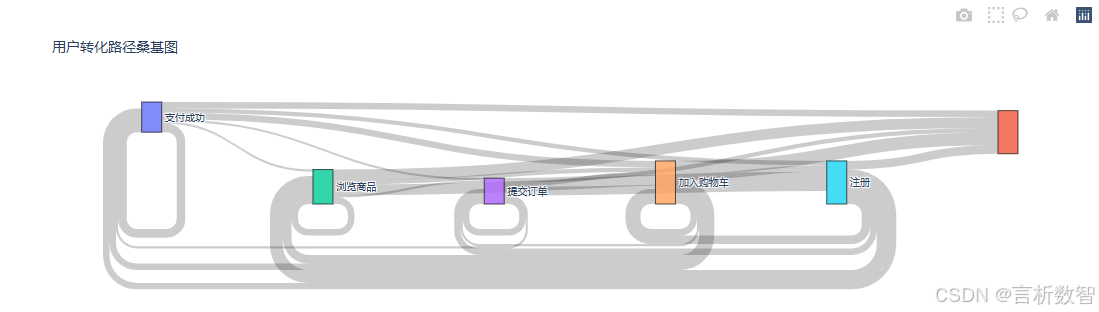
- 用户路径
- 就是用户在网站或 APP 中的访问行为路径,为了衡量网站/APP的优化效果或者营销推广效果,了解用户的行为偏好,要对访问路径的数据进行分析。
- 路径分析与漏斗分析的区别
- 行为路径分析是
用来追踪用户从某个事件开始到某个事件结束过程中的全部动线的分析方法。 - 转化漏斗是
人为定义的,而对于用户的行为路径,我们虽然可以通过产品设计进行引导,但却无法控制。 - 因此我们分析用户的行为路径可以了解用户的实际操作行为,让产品顺应用户,通过优化界面交互让产品用起来更加流畅和符合用户习惯,产出更多价值。
- 行为路径分析是
桑基图它的核心是对不同点之间,通过线来连接。线的粗细代表流量的大小。- 桑基图是分析用户路径的有效方法之一,
能非常直观地展现用户旅程,帮助我们进一步确定转化漏斗中的关键步骤,发现用户的流失点,找到有价值的用户群体,看用户主要流向了哪里,发现用户的兴趣点以及被忽略的产品价值,寻找新的机会。
4. 结果分析
- 转化瓶颈:从“加入购物车”到“提交订单”的流失率高达45%,需优化购物车流程。
- 核心路径:30%的用户直接从“浏览商品”跳转到“支付成功”,说明部分用户目标明确。
- 异常流失:5%的用户在“支付成功”后返回“浏览商品”,可能存在支付后体验问题。
8.2.3 地理地图实战案例
1. 数据背景与准备
- 业务场景:展示某连锁品牌在全国各省市的门店分布与销售额。
- 数据来源:
store_data表包含store_id(门店ID)、province(省份)、city(城市)、sales(销售额)。- 地理数据:
china_province.geojson文件包含中国省级行政区边界。
-- 创建store_data表(含字段约束和业务逻辑校验)
-- 修改store_data表,添加经纬度字段(含范围约束)
CREATE TABLE store_data (
store_id SERIAL PRIMARY KEY,
province VARCHAR(20) NOT NULL,
city VARCHAR(25) NOT NULL,
sales NUMERIC(10,2) NOT NULL CHECK (sales >= 0),
longitude NUMERIC(9,6) NOT NULL CHECK (longitude BETWEEN -180 AND 180), -- 经度(-180~180)
latitude NUMERIC(9,6) NOT NULL CHECK (latitude BETWEEN -90 AND 90) -- 纬度(-90~90)
);
-- 创建空间索引(优化经纬度查询性能)
CREATE INDEX idx_store_geo ON store_data USING GIST (ST_MakePoint(longitude, latitude));
-- 插入100条门店数据(含省份-城市关联和合理销售额)
WITH city_list AS (
-- 定义所有城市的省份、城市、经纬度范围(替代LATERAL VALUES)
SELECT
'广东' AS province, '广州' AS city, ARRAY[112, 115, 22, 25] AS range UNION ALL
SELECT '广东', '深圳', ARRAY[112, 115, 22, 25] UNION ALL
SELECT '广东', '佛山', ARRAY[112, 115, 22, 25] UNION ALL
SELECT '江苏', '南京', ARRAY[116, 121, 30, 35] UNION ALL
SELECT '江苏', '苏州', ARRAY[116, 121, 30, 35] UNION ALL
SELECT '江苏', '无锡', ARRAY[116, 121, 30, 35] UNION ALL
SELECT '浙江', '杭州', ARRAY[118, 122, 27, 31] UNION ALL
SELECT '浙江', '宁波', ARRAY[118, 122, 27, 31] UNION ALL
SELECT '浙江', '温州', ARRAY[118, 122, 27, 31] UNION ALL
SELECT '山东', '济南', ARRAY[114, 122, 34, 38] UNION ALL
SELECT '山东', '青岛', ARRAY[114, 122, 34, 38] UNION ALL
SELECT '山东', '烟台', ARRAY[114, 122, 34, 38] UNION ALL
SELECT '河南', '郑州', ARRAY[110, 116, 31, 36] UNION ALL
SELECT '河南', '洛阳', ARRAY[110, 116, 31, 36] UNION ALL
SELECT '河南', '南阳', ARRAY[110, 116, 31, 36]
),
store_data_generator AS (
SELECT
-- 从city_list中随机选择城市(9.2不支持LATERAL,改用随机索引)
(SELECT province FROM city_list LIMIT 1 OFFSET floor(random()*15)) AS province,
(SELECT city FROM city_list WHERE province = c.province LIMIT 1 OFFSET floor(random()*3)) AS city,
-- 销售额计算(同前)
CASE
WHEN c.province IN ('广东','江苏','浙江')
THEN ROUND((50000 + random()*50000)::NUMERIC, 2)
ELSE ROUND((30000 + random()*30000)::NUMERIC, 2)
END AS sales,
-- 生成经纬度(从city_list中获取范围)
(SELECT range[1] FROM city_list WHERE province = c.province AND city = c.city) + random()*((SELECT range[2] FROM city_list WHERE province = c.province AND city = c.city) - (SELECT range[1] FROM city_list WHERE province = c.province AND city = c.city)) AS longitude,
(SELECT range[3] FROM city_list WHERE province = c.province AND city = c.city) + random()*((SELECT range[4] FROM city_list WHERE province = c.province AND city = c.city) - (SELECT range[3] FROM city_list WHERE province = c.province AND city = c.city)) AS latitude
FROM generate_series(1, 100) AS s, -- 生成100条记录
city_list c -- 交叉连接城市列表(后续通过随机索引过滤)
LIMIT 100 -- 确保生成100条记录(避免交叉连接膨胀)
)
INSERT INTO store_data (province, city, sales, longitude, latitude)
SELECT province, city, sales, longitude, latitude
FROM store_data_generator;
2. PostgreSQL数据处理
- 空间数据导入:
-- 创建地理表
CREATE EXTENSION postgis;
CREATE TABLE provinces (
id SERIAL PRIMARY KEY,
name VARCHAR(50),
geom GEOMETRY(MultiPolygon, 4326)
);
-- 插入100条省份地理数据(含名称和简化多重多边形)
WITH province_names AS (
-- 中国34个省级行政区名称(随机选取)
SELECT unnest(ARRAY[
'北京市','天津市','上海市','重庆市','河北省','山西省','辽宁省','吉林省','黑龙江省',
'江苏省','浙江省','安徽省','福建省','江西省','山东省','河南省','湖北省','湖南省',
'广东省','海南省','四川省','贵州省','云南省','陕西省','甘肃省','青海省','台湾省',
'内蒙古自治区','广西壮族自治区','西藏自治区','宁夏回族自治区','新疆维吾尔自治区',
'香港特别行政区','澳门特别行政区'
]) AS name
),
random_geom_generator AS (
-- 生成随机多重多边形范围(基于中国大致经纬度范围)
SELECT
-- 随机选择省份名称
(SELECT name FROM province_names OFFSET floor(random()*34) LIMIT 1) AS name,
-- 使用ST_Multi将Polygon转换为MultiPolygon
ST_Multi(
ST_SetSRID(
ST_MakeEnvelope(
73 + random()*62, -- 经度范围:73°E~135°E
18 + random()*35, -- 纬度范围:18°N~53°N
73 + random()*62,
18 + random()*35
),
4326 -- WGS84坐标系
)
)::GEOMETRY(MultiPolygon, 4326) AS geom -- 显式指定类型
FROM generate_series(1, 100) -- 生成100条记录
)
INSERT INTO provinces (name, geom)
SELECT name, geom
FROM random_geom_generator;
-- 导入GeoJSON数据
SELECT ST_GeomFromGeoJSON('your_geojson_content') AS geom INTO provinces;
- 空间连接:
-- 计算各省份总销售额并关联地理空间数据
SELECT
p.name AS province, -- 选取省份名称(重命名为province)
SUM(s.sales) AS total_sales, -- 按省份汇总销售额(保留两位小数,符合表结构定义)
p.geom -- 选取省份的几何数据(用于后续地理可视化或空间分析)
FROM
store_data s -- 门店数据表(包含销售额和经纬度)
JOIN
provinces p -- 省份地理表(包含省份名称和多边形几何数据)
-- 空间连接条件:判断门店经纬度点是否位于省份多边形范围内
ON ST_Contains(
p.geom, -- 省份多边形几何对象
ST_SetSRID( -- 设置空间参考系统ID(4326为WGS84经纬度坐标系)
ST_MakePoint(s.longitude, s.latitude), -- 根据门店经纬度创建点几何对象
4326
)
)
GROUP BY
p.name, p.geom -- 按省份名称和几何数据分组(确保同名省份几何唯一,避免分组错误)
;
3. Python可视化实现
- 工具选择:使用
Plotly Express绘制地理地图。
import plotly.express as px
import pandas as pd
import psycopg2
# 连接数据库
conn = psycopg2.connect(
dbname="postgres",
user="postgres",
password="postgres",
host="192.168.232.128",
port="5432"
)
# 读取数据
df = pd.read_sql("""
with province_sales as (
SELECT
p.name AS province,
SUM(s.sales) AS total_sales,
p.geom
FROM store_data s
JOIN provinces p
ON ST_Contains(p.geom, ST_SetSRID(ST_MakePoint(s.longitude, s.latitude), 4326))
GROUP BY p.name, p.geom
)
SELECT province, total_sales, ST_AsGeoJSON(geom) AS geojson
FROM province_sales
""", conn)
conn.close()
# 绘制地理地图
fig = px.choropleth_mapbox(
df,
geojson=df['geojson'],
locations=df['province'],
color='total_sales',
color_continuous_scale="Viridis",
range_color=(0, df['total_sales'].max()),
mapbox_style="carto-positron",
zoom=3,
center={"lat": 35.8617, "lon": 104.1954},
opacity=0.5,
labels={'total_sales': '销售额(万元)'}
)
fig.update_layout(margin={"r":0,"t":0,"l":0,"b":0})
fig.show()
- 数据案例问题,暂时无法有效展示
4. 结果分析
- 高销售额区域:广东、江苏、浙江等沿海省份销售额领先,与经济发达程度一致。
- 低销售额区域:西藏、青海等西部省份门店较少,需评估市场扩展潜力。
- 异常值:新疆销售额较高,可能存在大型旗舰店或特殊市场策略。
8.2.4 高级可视化技巧总结
| 图表类型 | 适用场景 | 核心工具 | 注意事项 |
|---|---|---|---|
| 热力图 | 二维数据分布分析(如时间×地区) | Seaborn/Plotly | 数据标准化、颜色映射合理性 |
| 桑基图 | 流程转化分析(如用户路径) | Plotly | 节点命名简洁、避免过度复杂路径 |
| 地理地图 | 空间数据展示(如门店分布) | Plotly Express | 投影选择、地理数据精度 |
性能优化建议
-
- 热力图:使用
ST_AsHMT函数(阿里云Ganos)实现实时聚合,处理亿级数据秒级响应。
- 热力图:使用
-
- 桑基图:
限制路径层级(如仅展示主路径),避免内存溢出。
- 桑基图:
-
- 地理地图:创建空间索引(
CREATE INDEX idx_geom ON provinces USING GIST(geom);)提升查询效率。
- 地理地图:创建空间索引(
通过上述案例,读者可掌握
PostgreSQL与Python结合的高级可视化技术,从数据清洗到呈现全流程实现业务洞察。
实际应用中需根据数据特点与业务需求灵活选择工具与方法,确保可视化结果的准确性与说服力。


















 6343
6343

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











