







描述:发送webservice请求,得到2层嵌套的xml,一直解析不成功,总是打印一条数据,以下为本人解决方案和思路
解析的xml:
<soap:Envelope xmlns:soap="http://schemas.xmlsoap.org/soap/envelope/">
<soap:Body>
<TestResponse xmlns="http://tempuri.org/">
<TestResult>
<![CDATA[<?xml version="1.0" encoding="utf-8"?>
<Students>
<Student>
<NAME>张三</NAME>
<AGE>23</AGE>
<SEX>男</SEX>
<CLASS>三年二班</CLASS>
</Student>
<Student>
<NAME>李四</NAME>
<AGE>21</AGE>
<SEX>男</SEX>
<CLASS>三年三班</CLASS>
</Student>
<Student>
<NAME>王五</NAME>
<AGE>19</AGE>
<SEX>女</SEX>
<CLASS>三年一班</CLASS>
</Student>
</Students>]]>
</TestResult>
</TestResponse>
</soap:Body>
</soap:Envelope>解析的结果如下

发现解析出来的结果全是张三一个人,附上当前的代码
public static void test() {
try {
StringBuffer data = new StringBuffer();
data.append(
"<soap:Envelope xmlns:soap=\"http://schemas.xmlsoap.org/soap/envelope/\"><soap:Body><TestResponse xmlns=\"http://tempuri.org/\"><TestResult><![CDATA[<?xml version=\"1.0\" encoding=\"utf-8\"?><Students><Student><NAME>张三</NAME><AGE>23</AGE><SEX>男</SEX><CLASS>三年二班</CLASS></Student><Student><NAME>李四</NAME><AGE>21</AGE><SEX>男</SEX><CLASS>三年三班</CLASS></Student><Student><NAME>王五</NAME><AGE>19</AGE><SEX>女</SEX><CLASS>三年一班</CLASS></Student></Students>]]></TestResult></TestResponse></soap:Body></soap:Envelope>");
// 打印HTTP响应数据
System.out.println("响应数据:" + data);
// 将返回的数据转成Document
Document document = DocumentHelper.parseText(data.toString());
// 获取文档根节点
Element root = document.getRootElement();
// 取出第二层xml
root = root.element("Body").element("TestResponse").element("TestResult");
System.out.println("输出的名字" + root.getName());
System.out.println("输出的内容" + root.getText());
//将第二层的String的xml转成Document 用于处理
//之前看到不少都是直接截取字符串取得,我这边认为这样不方便,于是一层一层的取到第二层的xml
//可以将取出第二层xml用到的节点数据写在配置文件里面,这样后期节点变动可以只改配置文件 不用改java代码,当然要是改动太大就没办法了
Document document2 = DocumentHelper.parseText(root.getText());
// 获取文档根节点
Element root2 = document2.getRootElement();
//打印当前的根节点的name
System.out.println("输出的名字" + root2.getName());
//取根节点之下的Students
List<Element> list2 = root2.elements();
int i = 0;
//需要替换的代码(这个for是错误的)
for (Element e : list2) {
System.out.println("遍历eList: " + e.getName());
i++;
System.out.println("输出的名字" + root2.getName() +
"=======================" + i);
//取Students节点之下的Student
Element root3 = root2.element("Student");
List<Element> list = root3.elements();
//for循环遍历出所有的学生
for (Element k : list) {
System.out.println(
"遍历kList:" + k.getName() + "&&&" + k.getText());
}
}
} catch (DocumentException e) {
e.printStackTrace();
}
}数据可以确定是取出3条了,但是重复取得同一条,于是我的解决思路就在如何取出第二条数据
首先确定了list2的长度是没问题的,那问题已经确定了,肯定是第二层数据有问题
Element root3 = root2.element("Student");
这个是在网上找的方法取Student节点的数据,那么是不是因为它不是list只取到了第一个student的数据
既然elements是取节点之下的数据,那么我不根据Student取数据,直接取Students之下的节点是不是就可以了呢
改后的代码
for (Element e : list2) {
System.out.println("遍历eList: " + e.getName());
i++;
System.out.println("输出的名字" + root2.getName() +
"=======================" + i);
List<Element> list = e.elements();
for (Element k : list) {
System.out.println(
"遍历kList:" + k.getName() + "&&&" + k.getText());
}
}改后的结果
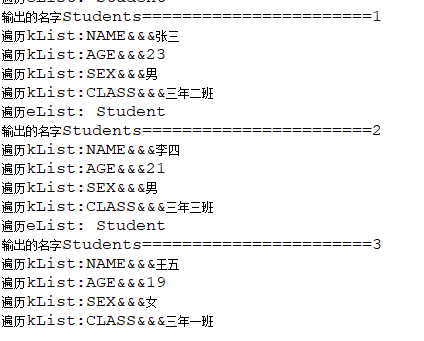
ok!果然是Element root3 = root2.element("Student");取得数据只取到了第一个Student的数据所导致的问题
希望可以给大家带来一点帮助。
<新手上路> 有更好的建议请在下方留言















 528
528











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









