







前言
RocketMQ的高性能设计主要体现在三个方面,数据存储,动态伸缩能力,消息投递设计。动态伸缩主要体现在队列扩容和集群扩容的能力,消息投递主要体现在其长轮询设计(和nacos配置中心的长轮询请求很像,可以去那篇看看,主要是避免了push模式对服务端的压力和pull模式对网络资源的浪费等缺陷)。本篇主要是看数据存储方面。RocketMQ数据存储方面的高性能设计,主要体现在四个方面:
1.前两个是和消息数据在硬盘上的存储设计有关的:顺序写盘和消费队列设计
2.后两个主要涉及消息数据在系统上的传输过程:消息跳跃读和数据零拷贝设计
下边来逐条分析:
顺序写盘
要了解RocketMQ关于数据在硬盘上的存储设计,首先要简单了解一下硬盘的结构,这里主要指机械硬盘。硬盘是用来存储数据的,而数据实际都存储在硬盘内的磁片上,当然一个硬盘内并不是只有一张磁片,而是有很多层磁片堆叠在一起的。从磁片上读取数据的是磁头,有的磁片两个盘面都可以存储数据,所以每个盘面都有自己对应的磁头。切面大概是这样:
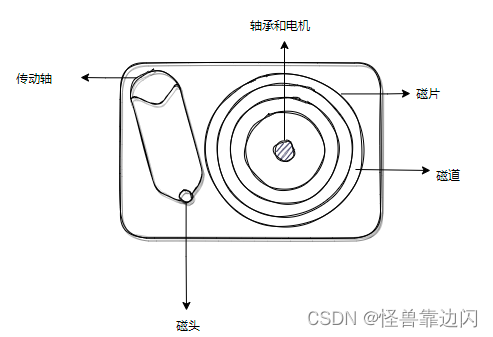
数据实际就存储在磁片盘面上一圈圈的磁道里(上边有磁性物质,通过改变磁极记录0和1)。整个硬盘的读写过程大概就是:
1.传动轴驱动磁头定位到相应的磁道
2.电机旋转磁盘,将磁道上相应的读写区域(扇区)送到磁头下
3.通过磁头在磁片上进行数据的读写。
所以要实现第三步读写,就必须经历前两步:寻道和旋转磁盘(消耗主要在于寻道,磁盘旋转实际非常快,家用机一般也可以达到7200转)。一般的写盘,一次写操作,磁头只会在磁盘上找到一个足够存放当前要写数据的空闲位置,完成后,再次写操作就再次寻找,这样的方式导致一些也许在看起来有逻辑关系的数据,实际在磁盘上的存放位置完全是天南海北,可以想象,在这样的条件下,一条条消息数据的读写过程,需要不断经历寻道,旋转磁盘的过程,必然消耗大量的时间。怎么样才能避免这样的时间消耗,这就是顺序写盘的意义。
顺序写盘就是指一段数据写入磁盘的结束位置和下一段数据开始写入的位置是相邻的,所以磁头在写完一条数据之后,就不需要再次经历新的定位过程,只要接着写下一条数据就好,同样,因为数据顺序写,所有数据最终都会写在同一磁道或者相邻几条磁道上,这样在读取数据时,磁头也不需要移动或只在很小的范围内移动,就大大节省了寻道的时间,提升了数据的整体读写效率(有实验证明,随机读写数据速度只有几十几百KB每秒,而顺序读写速度能达到几十几百MB,相差千倍,甚至超过了一般网卡的数据传输速度)。
了解了顺序写盘的优势,那么RocketMQ是怎样实现顺序写盘的呢?当RocketMQ成功部署运行成功之后(发送至少一条消息),在{USER_HOME}中(可以通过broker.conf修改),有/store/commitlog文件夹,文件夹里可以看到一个名称为一串0的文件(20位,命名规则稍后说),而且查看大小正好1G(默认),是的,RocketMQ刚运行,不管你发的消息有多小,他都会直接在硬盘上创建占据一个1G大小的空间,之后所有的消息,无论Topic是什么,不会做任何分类,都会一股脑的往这个文件里顺序存放,满了就再创建一个1G的文件,这些文件就是RocketMQ的CommitLog文件。因为直接创建1G的文件,所以在磁盘上也是相应的,一次占据了1G的连续空间,RocketMQ就是以这种提前占地儿的方式来保证数据都被顺序记录在磁盘上。
消费队列设计
顺序写盘使RocketMQ节省了大量寻道的时间,但显而易见,这样就会造成另一个问题,数据是顺序紧凑的写入磁盘了,但因为所有的Topic都存在一起,消息消费者想要消费指定Topic的消息数据时,难道要在一个个1G大的文件里进行检索吗,这无疑会造成消费消息变得性能差,吞吐量低,为此,RocketMQ还有一个消费队列设计(先说一下,这些队列文件也是顺序写盘的,后边介绍中也很容易看出,就不再提了,主要介绍队列设计)。
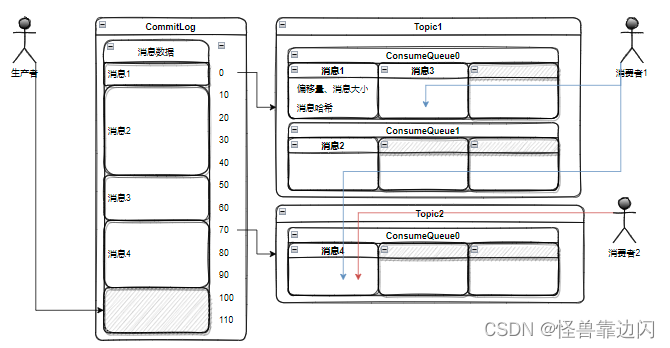
还是和上边发现CommitLog文件的过程一样,在commitlog的相同路径下,有一个consumequeue文件夹,进入后,就可以看到各个自定义的topic命名的文件夹,每个文件夹内又有多个数字命名的文件夹,对应多个消费队列,一个topic在某个broker下默认会有4个消费队列(顺序消息除外,原因以后另说),同样,这些数字文件夹内,是一个一串0命名的文件,5.72M大小。
这些消费队列文件的存储过程,简单来说,就是当消息写入CommitLog文件之后,RocketMQ会异步的在相应topic的ConsumeQueue消费队列文件中进行记录。不过要说明下,ConsumeQueue消息队列文件从CommitLog中获取并存储的数据并不是真正的消息数据,主要有三部分:在CommitLog中的物理偏移量,消息大小,和消息哈希(用于过滤功能),所以每条消息对应在消费队列中的存储空间固定且很小,每条固定20B,每个ConsumeQueue消费队列文件固定存放30万条数据,所以每个文件也固定6000000B(5.72M)。
主要说下偏移量,也涉及到了之前提到的这些文件的命名规则,这个偏移量是指当前消息数据存储的起始地址和CommitLog文件起始地址的差值,CommitLog文件起始地址定义为0,这样在提取消息详细数据时,就可以直接通过偏移量定位到数据,注意CommitLog文件的偏移量是总计的,第二个文件起始位置定义,是前一个文件的延续,所以第二个CommitLog文件的起始位置定义为1G的数值1024X1024X1024=1073741824,这就是这些文件的命名规则,该文件的起始偏移量,并用0向前补全20位,方便通过偏移量直接快速的找到对应文件并获取消息具体内容。
所以消息的消费,实际上是通过topic定位读取ConsumeQueue消费队列文件这些体量较小的文件,然后通过得到信息再去读取体量较大的CommitLog文件,而且是通过偏移量直接定位。
综上,RocketMQ消息数据在硬盘上的存储设计整体结构如下:
消息跳跃读取
上边说了数据在硬盘上的存储,但数据从硬盘上读取,到发送给消息消费者的过程还有很多步骤,而RocketMQ针对后续的步骤也进行了优化,下边继续。
首先在计算机系统中,cpu,内存,硬盘对数据的读写速度是完全不同的,而且存在着指数级差异,所以为了在速度上折中,cpu和内存,内存和硬盘之间,会存在一个缓冲空间,这里主要关注内存和硬盘之间的缓冲空间,而只要可以更多的使用这个缓冲空间,就可以降低直接访问硬盘的概率。
RocketMQ在消费broker中消息信息时,需要先从硬盘中读取消息数据,这时就会尽量使用内存和硬盘之间的缓冲机制,减少直接访问硬盘的次数,RocketMQ会在缓冲中查看是否有需要读取的数据,然后根据数据是否存在采取不同的操作流程:
1.如果所需数据没有命中缓冲,RocketMQ就会从硬盘中读取对应的数据(按页读取,页大小通常是4k),但是他并不是只读取对应数据,还会一次性读取当前数据之后一定量的数据(连续的几页),将这些数据一起读到缓冲空间中,而这种读取方式就叫跳跃读取。
2.如果缓冲中存在对应数据,说明之前的缓存是有效的,所以在RocketMQ从缓冲中取回给相应数据的同时,会继续从硬盘预读数据,以扩大缓存的范围。
从上述操作流程可以看出,如果是顺序读取数据,那么RocketMQ消费消息时,会不断从内存的缓冲空间中读取已经预读的数据,从而节省了直接读取硬盘的时间。
数据零拷贝
操作系统为了限制不同的程序之间的访问能力,防止他们获取别的程序的内存数据,或者获取外围设备的数据,并发送到网络等等原因,将执行权限进行了分级,分别为内核态和用户态。内核态可以访问内存中的任何地址,包括外围设备,例如硬盘,网卡等,权限等级最高;用户态相较于内核态只有较低的执行权限,只能受限的访问内存,而且很多操作是不被允许的,比如不允许访问外围设备,不允许访问受限内存之外的内存等。
以RocketMQ为例,作为一个应用程序,持有较低的执行权限,一般情况下只能在用户态运行,但是为了读写存储在硬盘上的消息数据,和将消息发放给消息消费者,RocketMQ确实需要做一些内核态才能做的事情,硬盘读写,网络读写等,此时就需要进行用户态到内核态切换。但是,两种状态的相互切换是要耗时的(保存当前状态的执行情况,寄存器状态,栈指针修改等),比如JDK早期,synchronized会直接调用系统锁,就存在用户态和内核态的切换消耗问题,所以synchronized也叫重量级锁(1.6之后有优化)。
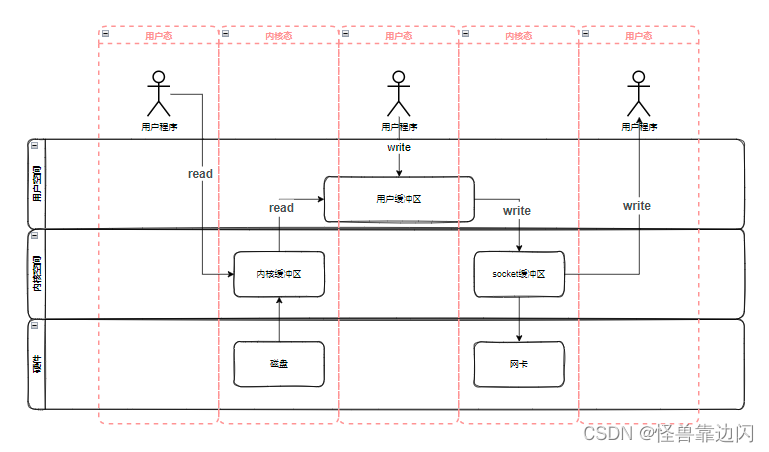
一般情况下,应用程序从磁盘读取数据并通过网络进行传输,首先要向系统调用read方法,这时系统会从用户态切换到内核态,然后才能把数据从磁盘读取到内核缓冲区中,再从内核缓冲区复制到用户缓冲区,同时切换回用户态,应用程序通过用户缓冲区获取到了数据,就可以向系统调用write方法,系统会再次进入核心态,并将数据从用户缓冲区复制到socket缓冲区,最后通过网卡,将数据传输出去,当然,最后会再次切换回用户态并返回write结果。整个过程如图:
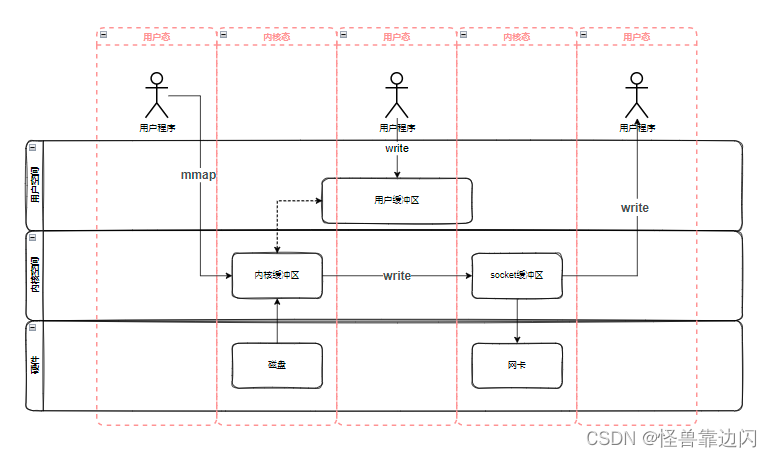
而RocketMQ使用了零拷贝的方式,这里说的零拷贝,并不是完全不拷贝,而是省略了一些拷贝的过程,零拷贝也分很多种,比如mmap+write,sendfile,sendfile+DMA,RocketMQ选用了mmap+write的方式,mmap也是读取数据的方法,但mmap和read的区别是,系统调用mmap时,会在调用进程的虚拟地址空间中创建一个新映射,这个映射会直接把内核缓冲区里的数据映射到用户空间,这样就省去了从内核缓冲区拷贝到用户缓冲区这一步了,但是,系统仍需切换到用户态,调用write方法,但数据是直接从内核缓冲区复制到socket缓冲区的,其他步骤差不多,如图:
sendfile和sendfile+DMA的方式简单说下,sendfile省去了中间切到用户态一步,等于减少了两次状态切换,sendfile+DMA涉及到另一个概念,DMA拷贝和CPU拷贝,简单来说DMA拷贝允许不同速度的硬件装置沟通,而不需要依赖于CPU ,CPU拷贝则要占用CPU,当然越少越好。而内存缓冲区到socket缓冲区的拷贝过程正好是CPU拷贝(内核缓冲区到用户缓冲区再到socket缓冲区也是CPU拷贝),sendfile+DMA在这步,只拷贝了描述符、数据长度等少量数据,网卡在从socket缓冲区获取相关信息后,会直接通过DMA拷贝从内核缓冲区获取数据,减少了CPU占用。但是我们已经知道,上边所说的有关零拷贝过程中的很多步骤,其实都是操作系统进行操作的,对系统有一定的要求,mmap+write的方式显然更具有通用性。















 221
221











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









