









文章目录
0. 引言
在数据治理项目或者数据中台搭建的过程中,都无法避免数据集成的步骤,该步骤甚至是整个流程的重中之重,所以一个可靠的数据同步组件就至关重要,本期我们特别讲解关于阿里开源的数据同步组件DataX,其可靠性经过阿里庞大的业务量锤炼下,也得到保障。
1. 简介
1.1 基础简介
DataX 是阿里云DataWorks数据集成工具分支出来的开源版本,主要用于解决异构数据源之间的大量数据同步问题。它能够帮助用户高效地实现数据在不同数据存储之间的迁移和同步,支持多种数据源,包括关系型数据库、NoSQL、大数据计算引擎以及各种存储系统。其特点主要包括:
- 丰富的数据源支持:MySQL、Oracle、OceanBase、SqlServer、Postgre、HDFS、Hive、ADS、HBase、TableStore(OTS)、MaxCompute(ODPS)、Hologres、DRDS, databend 等各种异构数据源之间高效的数据同步功能。
- 高性能:DataX 采用框架和插件分离的设计,框架负责调度、插件负责数据读写,使得各个数据源的同步可以并行执行,从而提高了数据同步的效率。针对各种数据源的同步性能我们可以在官方文档中查看
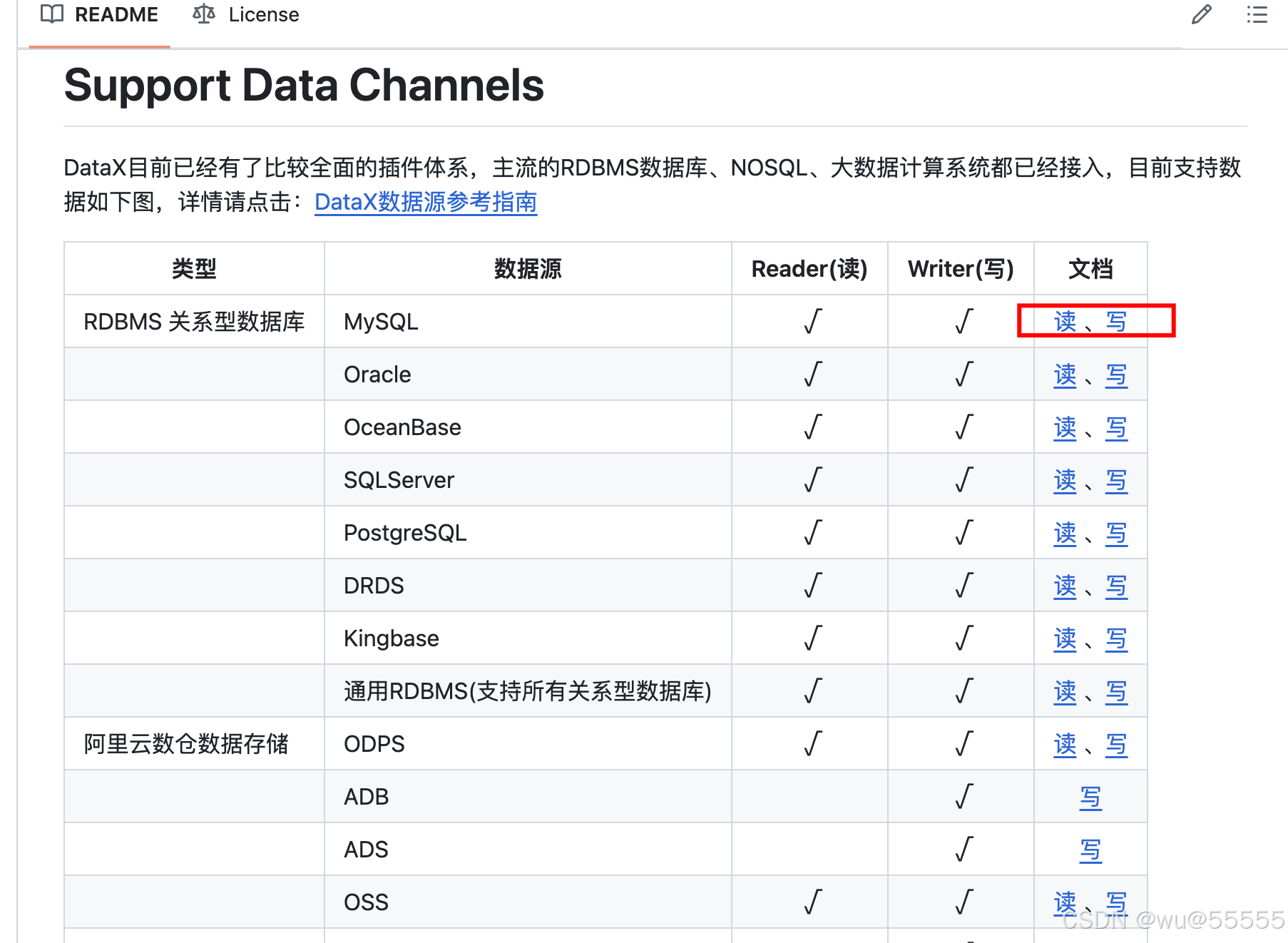
这里以mysql的同步写入性能为例,在测试报告文档中可以看到:基于24核48GB的datax服务器和32核256G的mysql服务器,在4通道,4000+批量提交行数的基础上,其同步写入速度可以达到8W条/s,随着通道数的提高,其性能指标还能继续提升。
https://github.com/alibaba/DataX/blob/master/mysqlwriter/doc/mysqlwriter.md
- 易用性:DataX 提供了简单的配置文件,用户可以通过编写JSON格式的配置文件来定义数据同步的任务,无需编写代码。这里提供一份mysql同步的配置,以供参考
{
"job": {
"setting": {
"speed": {
"channel": 1 // 通道数
}
},
"content": [
{
"reader": {
"name": "streamreader",
"parameter": {
"column" : [
{
"value": "DataX",
"type": "string"
},
{
"value": 19880808,
"type": "long"
},
{
"value": "1988-08-08 08:08:08",
"type": "date"
},
{
"value": true,
"type": "bool"
},
{
"value": "test",
"type": "bytes"
}
],
"sliceRecordCount": 1000
}
},
"writer": {
"name": "mysqlwriter",
"parameter": {
"writeMode": "insert",
"username": "root",
"password": "root",
"column": [
"id",
"name"
],
"session": [
"set session sql_mode='ANSI'"
],
"preSql": [
"delete from test"
],
"connection": [
{
"jdbcUrl": "jdbc:mysql://127.0.0.1:3306/datax?useUnicode=true&characterEncoding=gbk",
"table": [
"test"
]
}
]
}
}
}
]
}
}
-
可扩展性:DataX 支持自定义插件,用户可以根据自己的需求开发新的插件以支持更多的数据源。
-
稳定性:DataX 在阿里巴巴内部得到了广泛使用,经历了各种大数据场景的考验,其稳定性和可靠性得到了验证。
-
可视化操作:DataX Web 是 DataX 的可视化操作工具,用户可以通过图形界面配置和执行数据同步任务。
-
精准的并发控制:DataX3.0提供了包括通道(并发)、记录流、字节流三种流控模式,可以随意控制作业速度,让作业在库可以承受的范围内达到最佳的同步速度。
"speed": { "channel": 4, "byte": 1048576, "record": 10000}
1.2 工作原理
DataX中主要有3大模块:
- Reader(读取模块)
负责从数据源读取数据,将数据读取任务拆分成多个Task,分配到不同的线程中进行读取。
- Framework(框架核心)
负责整个数据同步流程的控制,包括任务的切分、Task的分配、执行、状态的监控以及错误处理等。
- Writer(写入模块)
负责将读取到的数据写入到目标数据源,同样会拆分成多个Task并行写入。
DataX 的使用,可以大大简化数据同步和迁移的工作,适用于数据仓库的构建、大数据的集成以及数据的实时同步等多种应用场景。
以mysql同步到HDFS为例,其工作原理,是通过Reader模块连接输入端mysql, 经过FrameWork进行缓冲,流控,并发,数据转换等核心逻辑,然后通过Writer输出到输出端HDFS

核心工作流程:
1、DataX配置的单个数据同步的任务,称之为一个Job, 针对每个Job,datax都会启动一个进程来进行同步作业。所以当看到后台启动了多个datax进程时,不要觉得有异常,同时当datax没有执行任务时,自然也就没有启动进程。
2、DataXJob启动后,会根据不同的源端切分策略,将Job切分成多个小的Task(子任务),以便于并发执行。Task便是DataX作业的最小单元,每一个Task都会负责一部分数据的同步工作。
3、切分多个Task之后,DataX Job会调用Scheduler模块,根据配置的并发数据量,将拆分成的Task重新组合,组装成TaskGroup(任务组)。每一个TaskGroup负责以一定的并发运行完毕分配好的所有Task,默认单个任务组的并发数量为5。
4、每一个Task都由TaskGroup负责启动,Task启动后,会固定启动Reader—>Channel—>Writer的线程来完成任务同步工作。
5、DataX作业运行起来之后, Job监控并等待多个TaskGroup模块任务完成,等待所有TaskGroup任务完成后Job成功退出。否则,异常退出,进程退出值非0
1.3 datax与datax-web
datax-web是datax的可视化管理后台,可以通过可视化的操作来管理调度datax执行器,而每个执行器又通过调度datax执行文件datax.py来启动数据同步任务,datax-web本身是基于xxl-job任务调度框架来实现同步任务的调度的,我们接下来通过具体安装来详细理解这两者间的关系
2. 安装
2.0 基础环境
-
JDK(1.8以上,推荐1.8):
下载地址:https://www.oracle.com/cn/java/technologies/downloads/ -
Python(2或3都可以):
下载地址:https://www.python.org/downloads/ -
Apache Maven 3.x (如果不需要源码编译则无需安装):
下载地址:https://maven.apache.org/download.cgi
2.1 datax安装
方式一:
1、可以直接下载安装包,当然也可以下载源码自己编译,我们单独讲解下源码编译的形式
https://datax-opensource.oss-cn-hangzhou.aliyuncs.com/datax.tar.gz
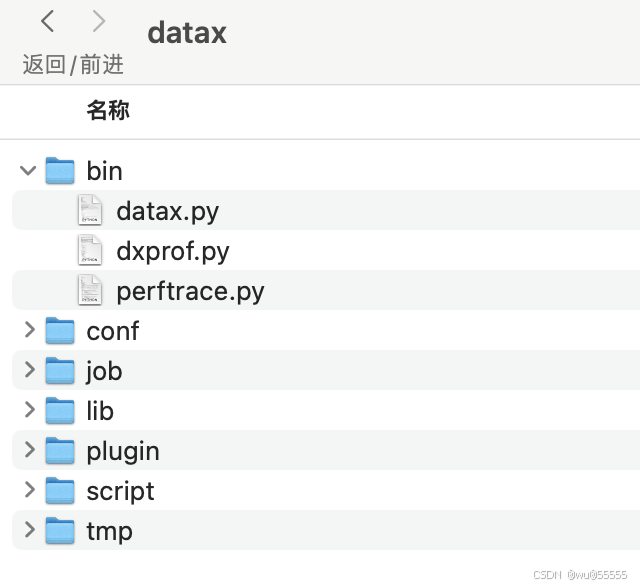
2、下载下来的安装包目录如图所示,其中bin目录下的datax.py就是运行datax的脚本程序,可以看到是python脚本,因此服务器环境中要有python的基础运行环境
方式二:
1、下载源码:https://github.com/alibaba/DataX/releases
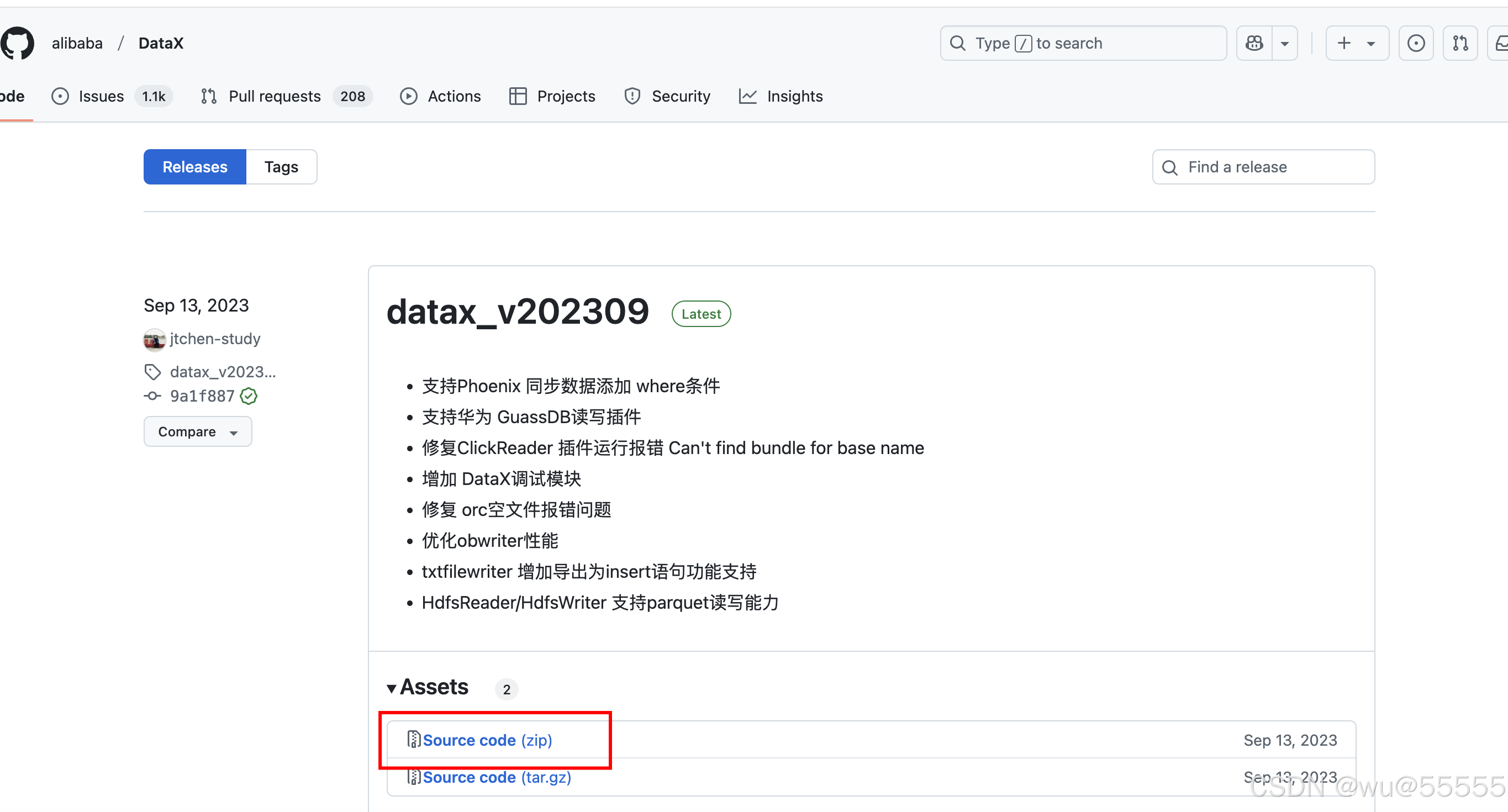
2、进入源码目录,执行打包语句(请提前下载maven)
cd {DataX_source_code_home}
mvn -U clean package assembly:assembly -Dmaven.test.skip=true
3、其打包出来的安装包就在根目录下的/target/datax/datax/ 目录,之后解压即可
4、安装包解压后,进入该目录下,执行测试脚本
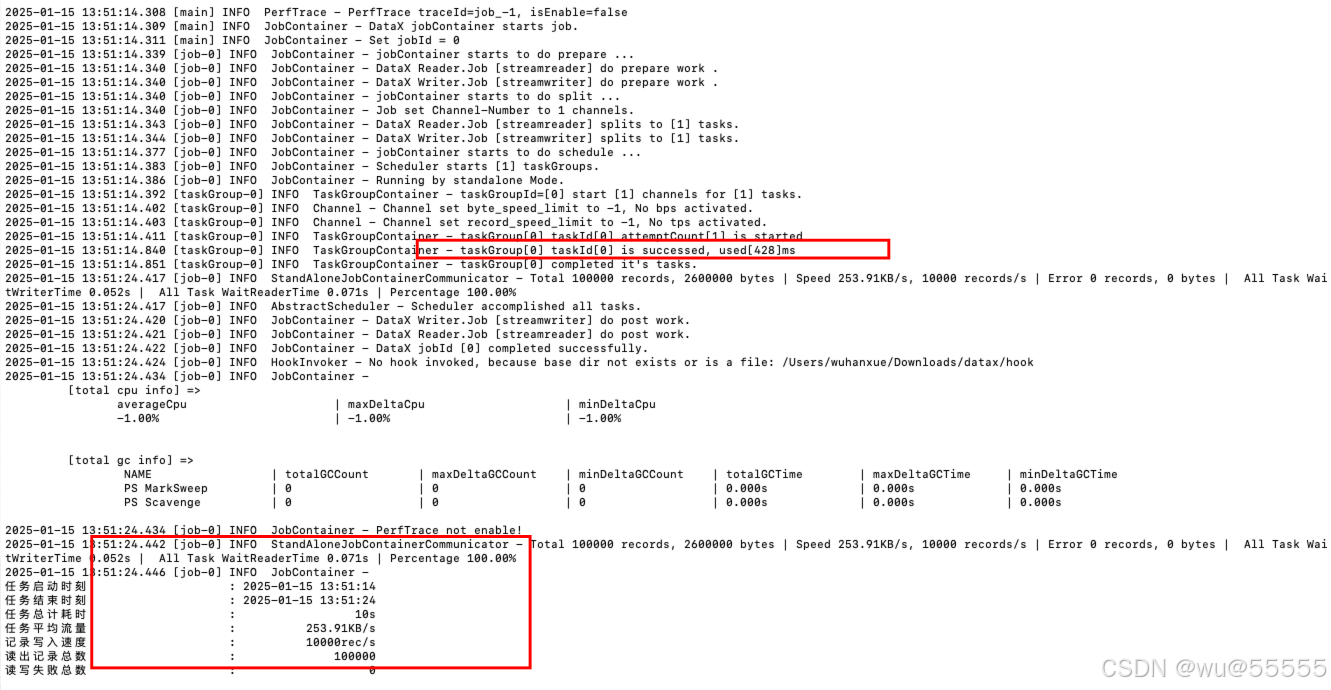
cd {你的安装路径}/datax
python bin/datax.py job/job.json
看到输出如下日志,则说明安装成功
补充:datax是java开发,为什么是python运行
我们在datax的github源码库可以看到datax是java开发的,但是为什么上述我们演示时,其启动又是通过python运行呢?
这是因为python相对java可以更加方便的实现脚本化操作,可以轻松实现任务的定时调度、重试、日志记录等,python也拥有丰富的第三方库,可以方便地与其他系统集成,虽然datax的任务调度是通过python来触发的,但是实际的数据抽取、转换、加载依然是java来完成的,python在datax的运行中,更加像一个桥梁的作用
2.2 datax-web安装
官方地址:https://github.com/WeiYe-Jing/datax-web
方式一:
1、下载安装包的方式,也是可以直接下载官方提供的安装包:https://pan.baidu.com/share/init?surl=3yoqhGpD00I82K4lOYtQhg,提取码:cpsk
方式二:
1、先通过如上的官方地址下载源码
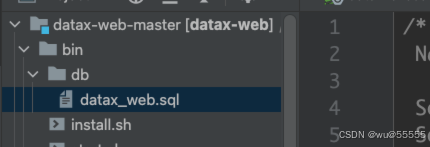
2、通过源码中的bin/db/datax_web.sql创建datax_web数据库
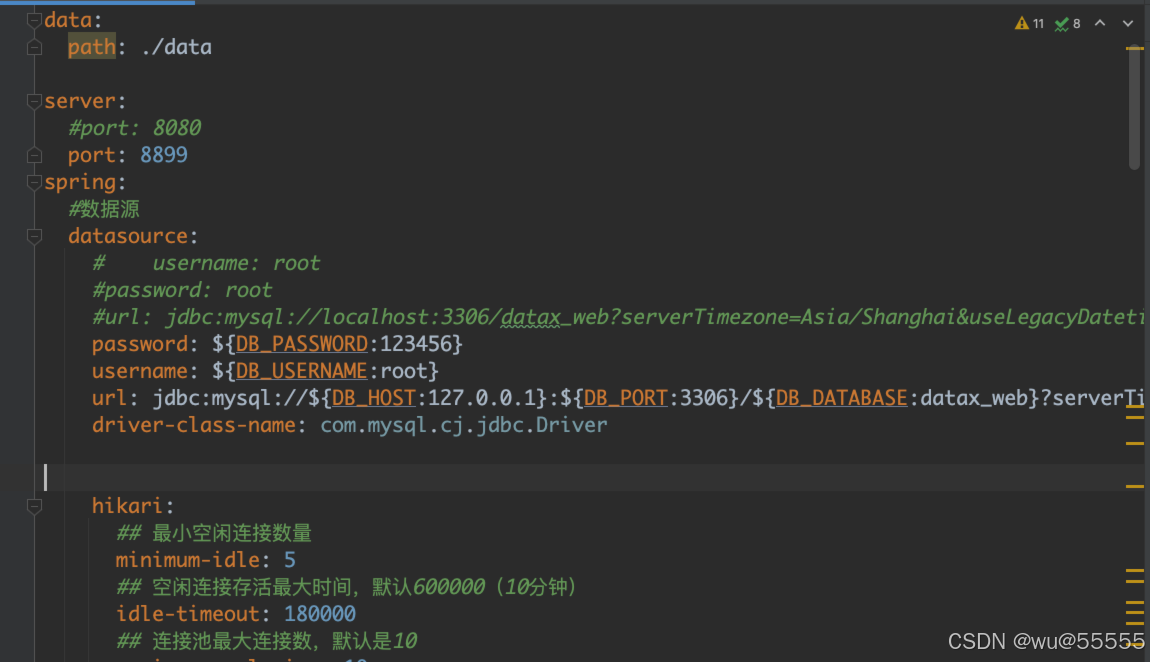
3、修改datax-admin项目中的配置文件application.yml,其配置文件中不少配置项是通过配置环境变量获取的,我这里直接定义在配置文件中了。需要重点调整的就是data.path目录,数据库地址、账号密码、服务端口等
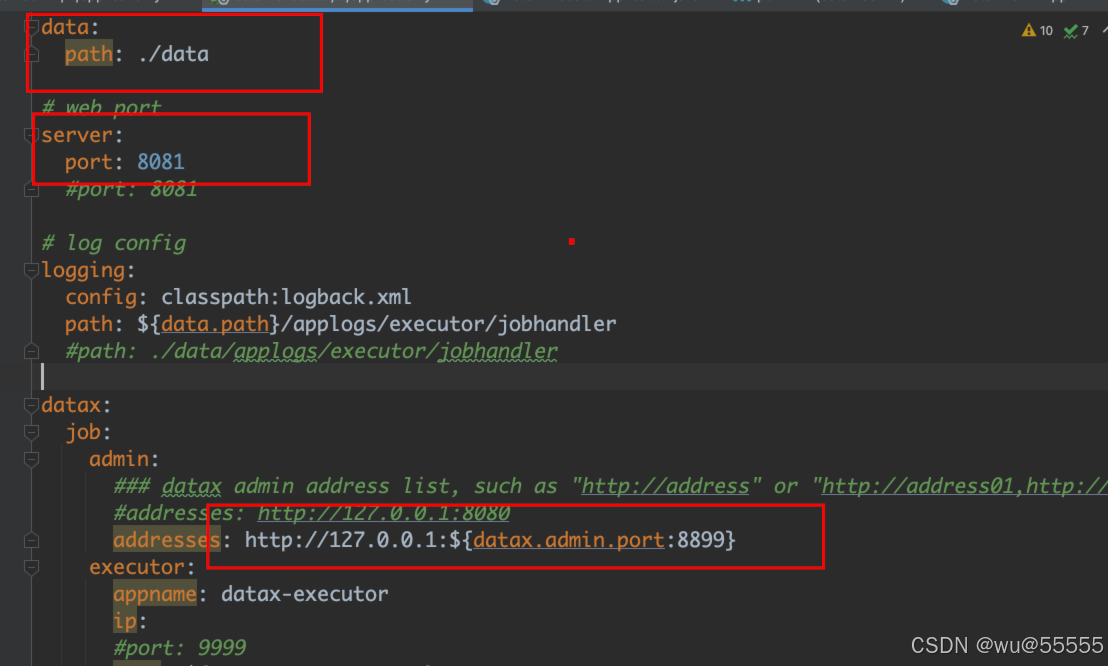
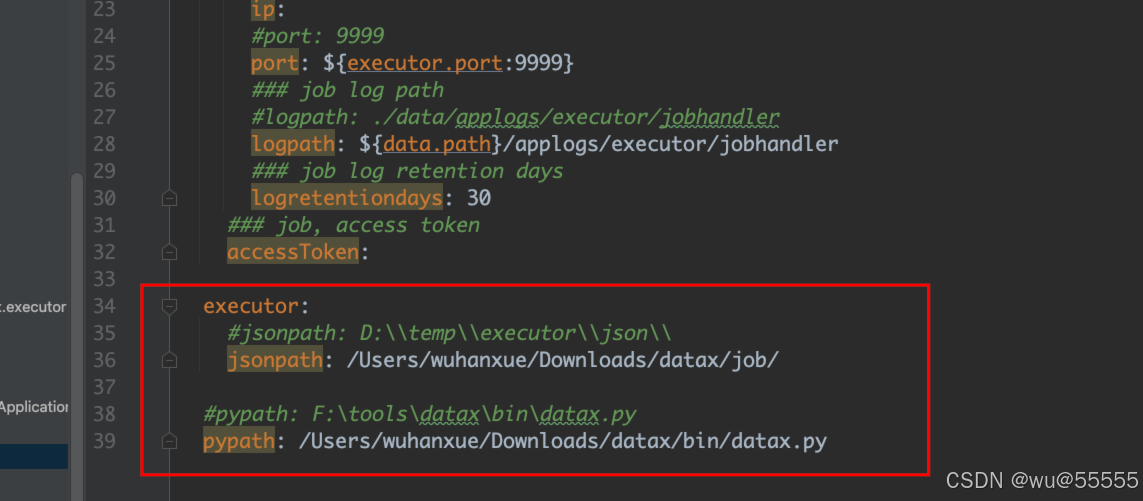
4、然后修改执行器datax-executor的配置文件application.yml,也是主要声明data.path目录、admin模块的服务端口,以及datax的json配置文件路径和执行脚本路径
5、启动admin和exector服务,看到如下日志说明启动成功
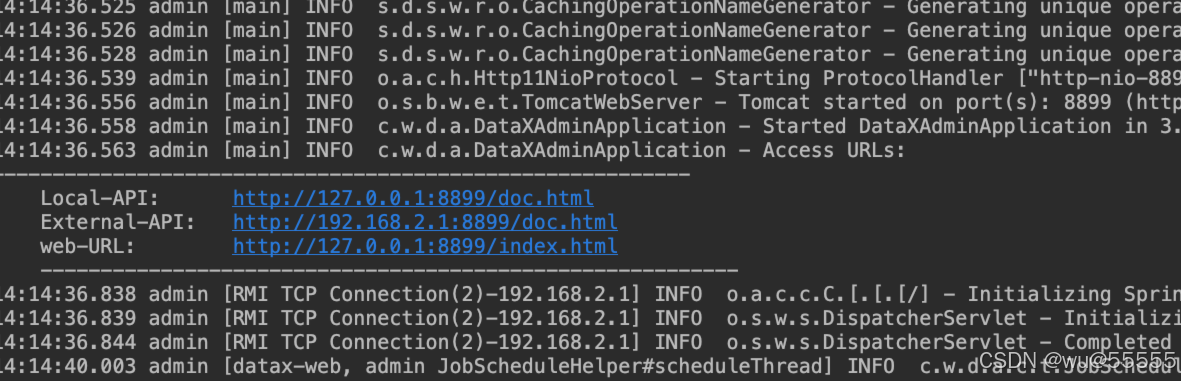
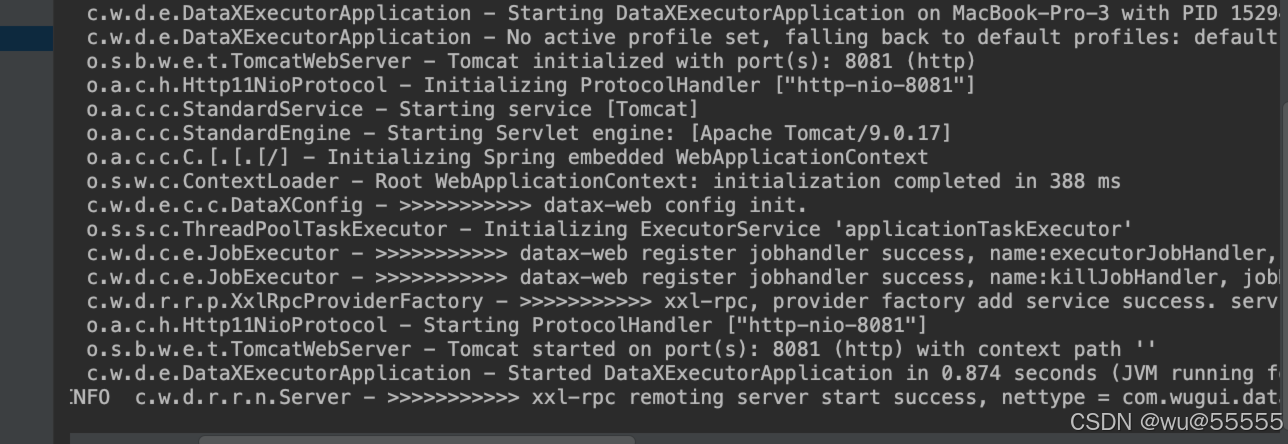
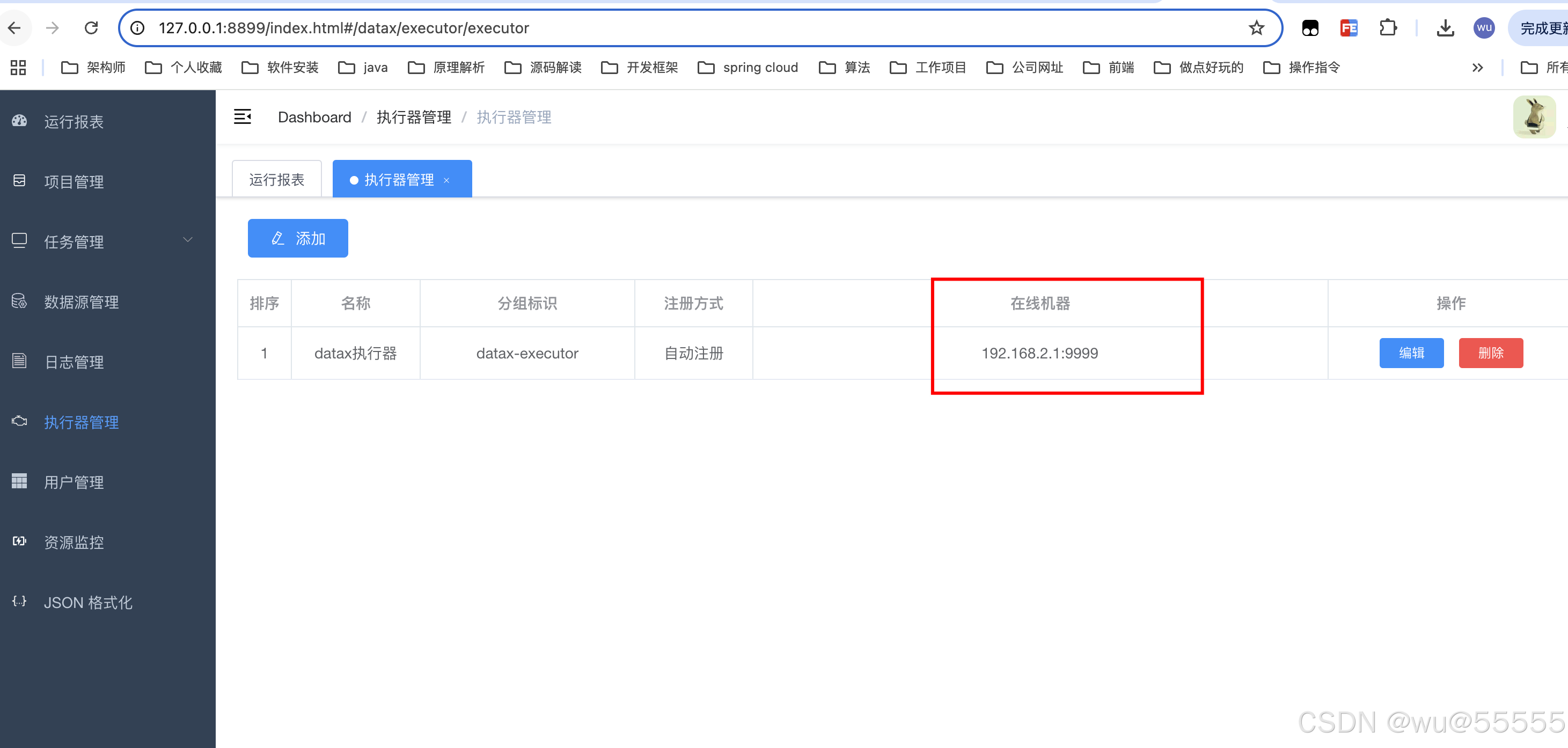
我们访问后台服务,在执行器管理中有看到执行器有注册上具体的机器ip,说明执行器启动正常
3. 总结
至此,我们针对datax,datax-web的安装就完成了,下一节我们详细讲解datax json配置,并通过实际同步案例带大家感受下


















 3919
3919

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











