







0. 引言
上一章我们讲解了datax中可以通过-p自定义参数实现增量同步,但是该种方式还要单独维护每次的偏移量,本章我们来看看如何通过datax-web快速实现自定义增量同步。
1. datax-web简介
之前我们已经说明过datax-web的安装,可以看到其菜单主要分为项目管理、任务管理、数据源管理、日志管理、执行期管理、用户管理等几大管理模块
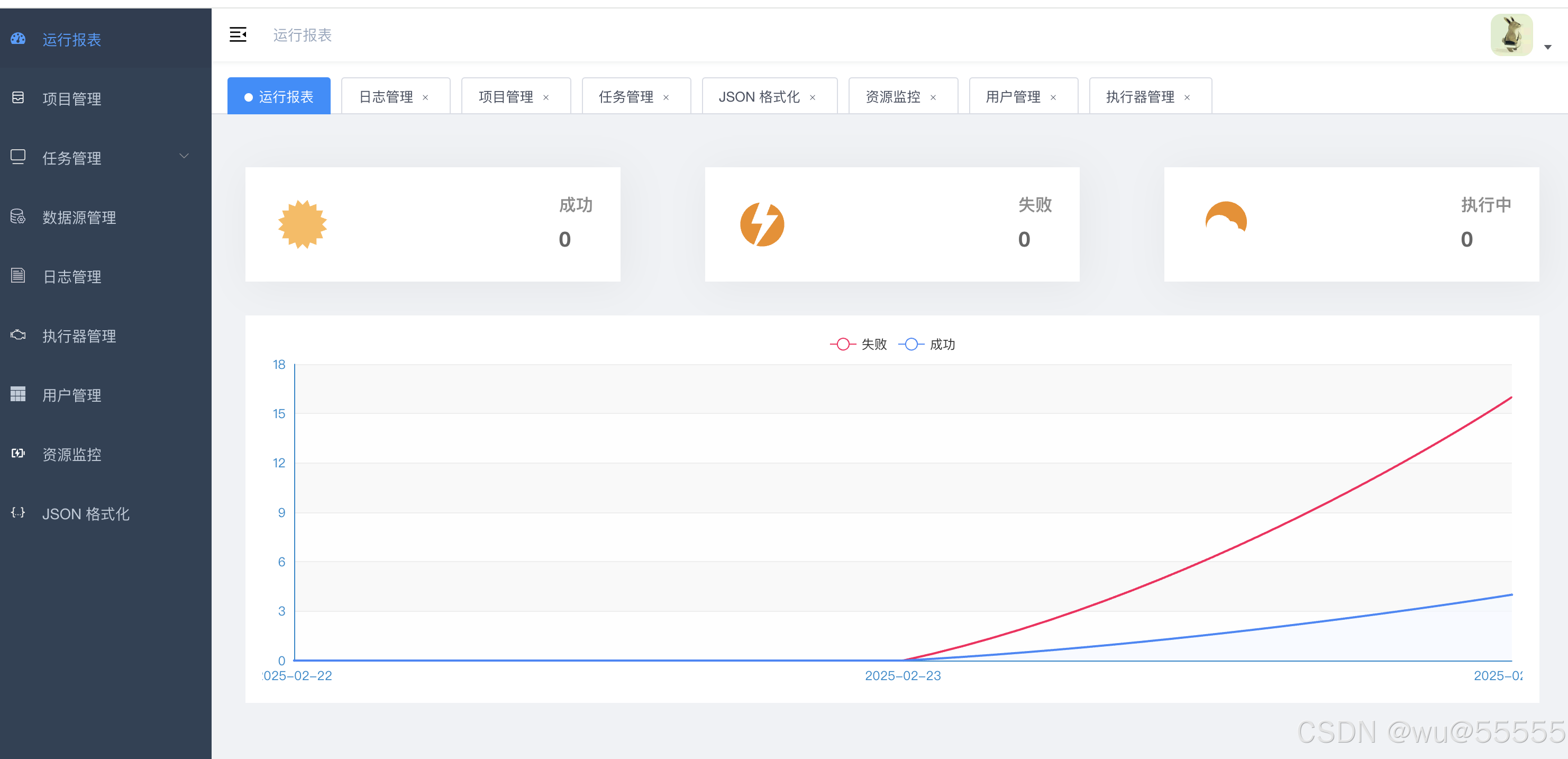
各模块核心功能如下:
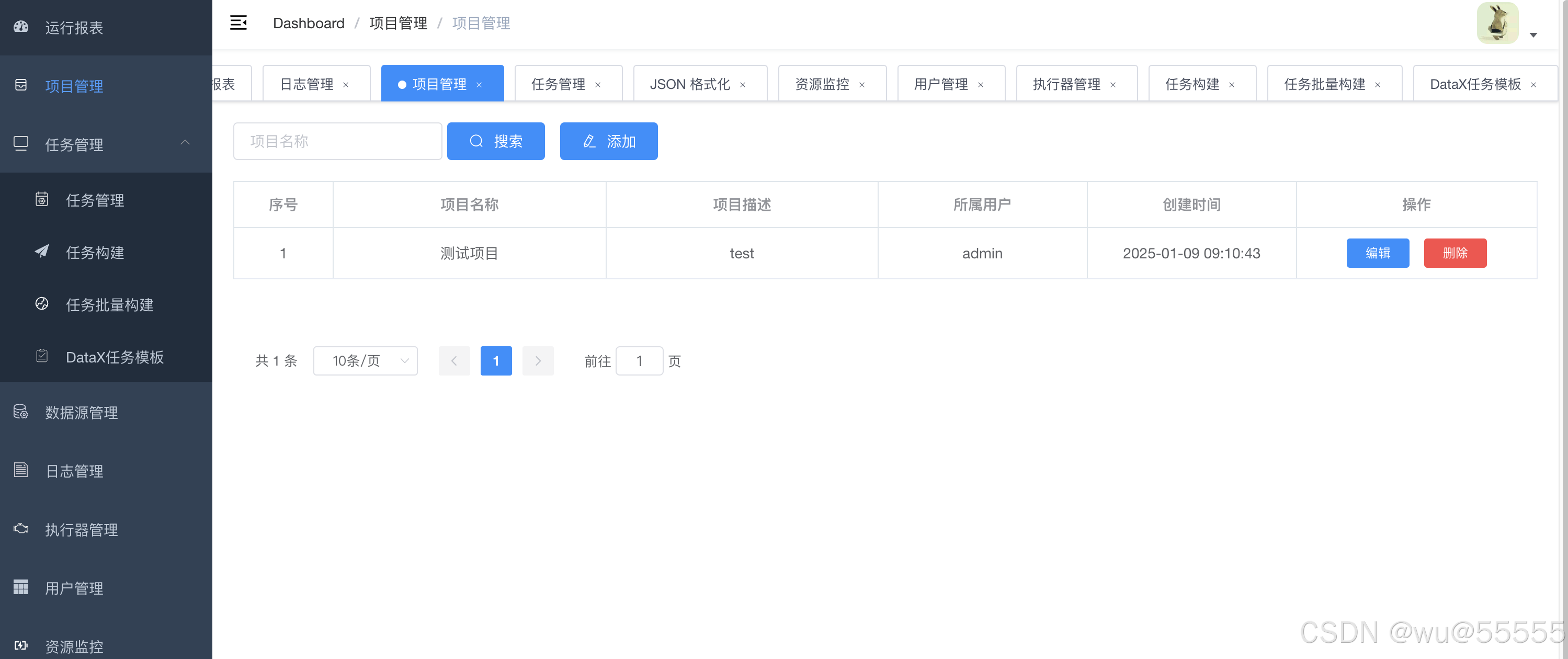
- 项目管理
其同步任务也是通过项目制来进行管理,任务中会关联项目,可以项目维度对任务进行管理
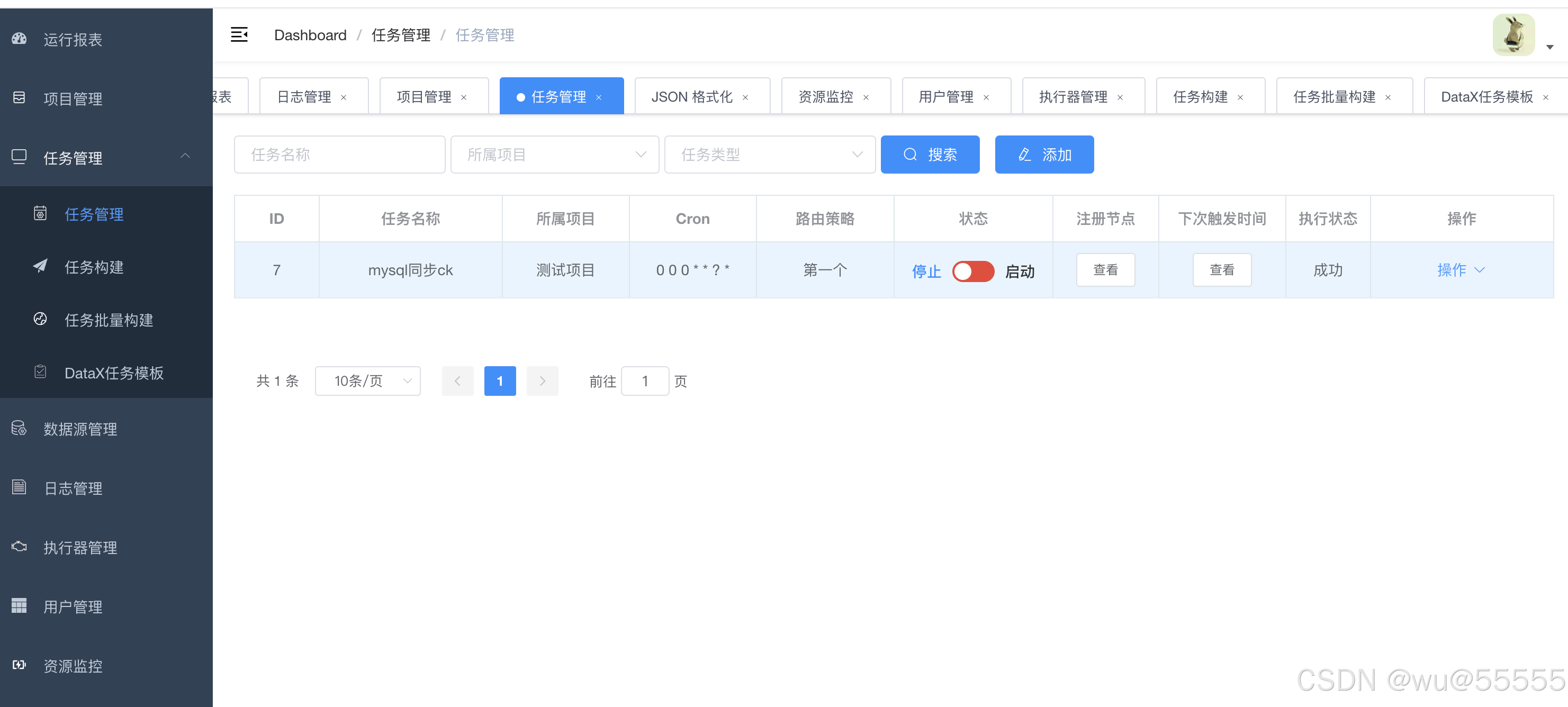
- 任务管理
任务管理中有4个子模块:任务管理、任务构建、任务批量构建、DataX任务模版
DataX任务模版:主要用于创建任务模版,如果有比较多表的配置类似,只是字段上的区别,实际上可以通过创建任务模版,再根据模版来创建任务,以此实现快捷的任务新增。
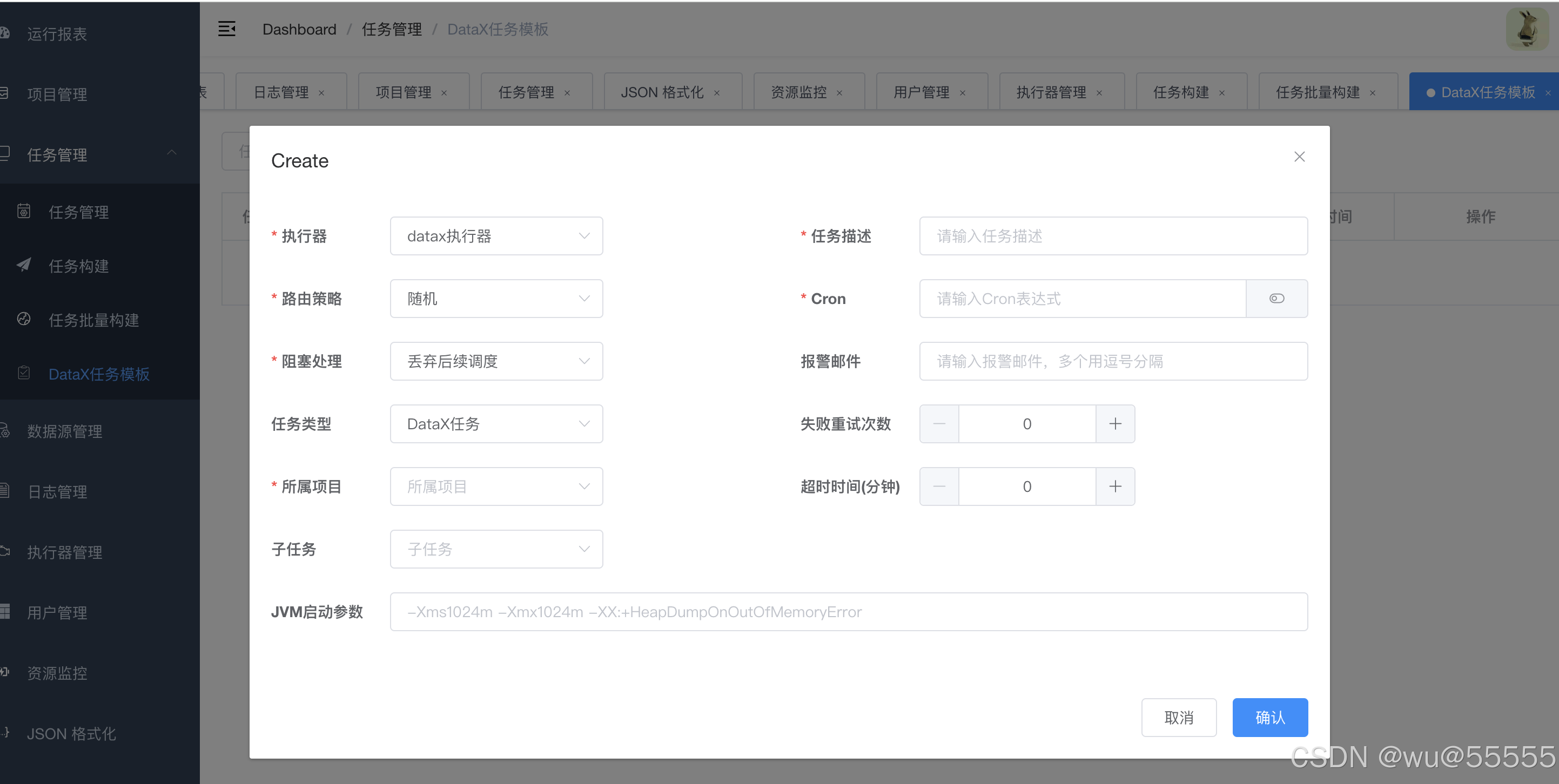
任务批量构建:当同一个数据源需要批量将数据表同步到另一个数据源时,就可以通过该页面进行任务批量构建

任务构建:主要用于引导式的任务创建,当不熟悉datax json配置文件时,可以通过这种引导式页面进行配置
任务管理:创建好的任务会在该页面进行统一管理,包括执行、定时配置、修改删除等
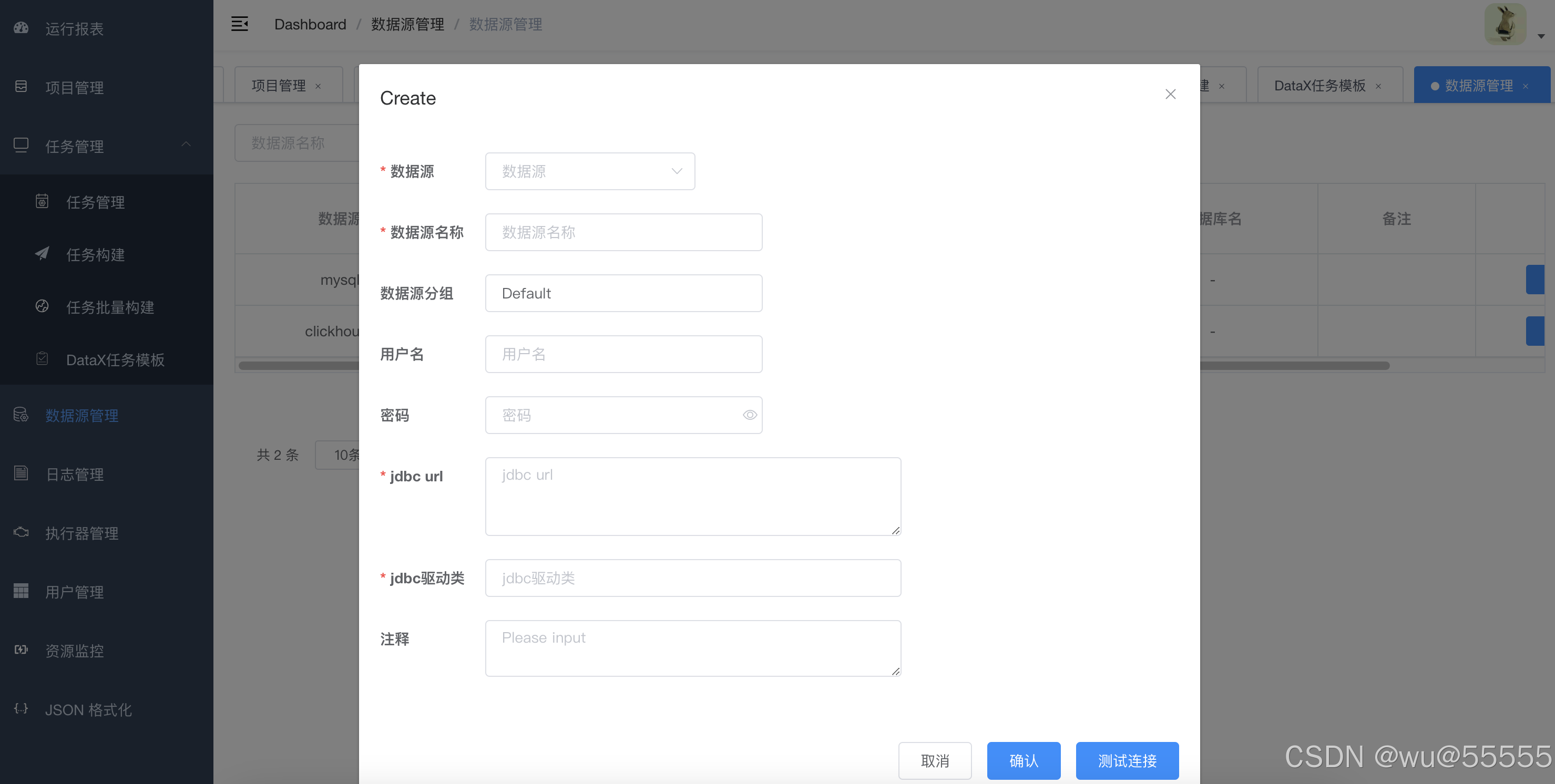
- 数据源管理
主要用于维护需要同步的数据源和目标数据源的基本信息,包括ip、端口、账号密码、驱动器等
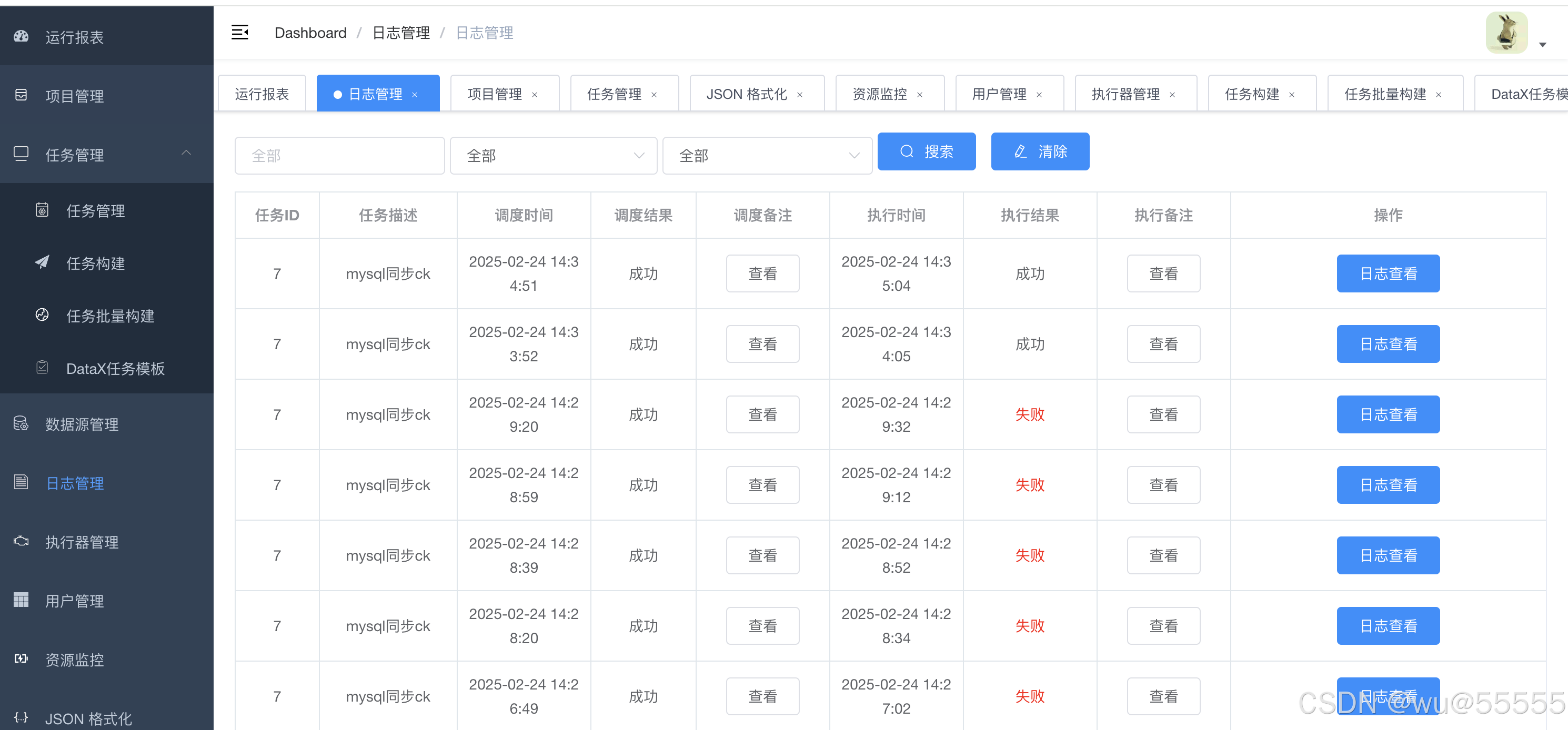
- 日志管理
主要用于记录任务的运行日志,可以通过日志看到执行失败时的具体原因,从而方便排查
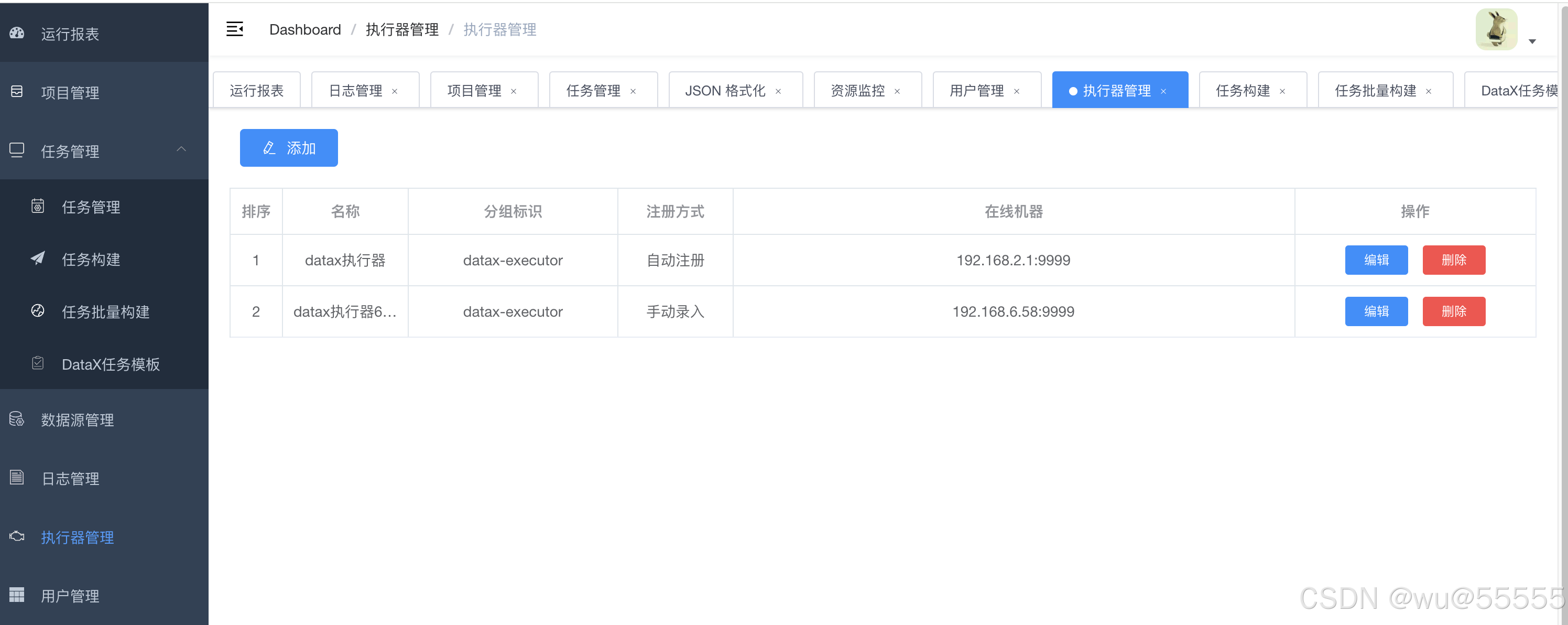
- 执行器管理
datax的执行器是指具体调用datax程序的datax-executor模块,通过该模块生成和调用datax脚本,从而启动数据同步进程
2. 数据同步配置
2.1 全量数据同步配置
0、首先在“数据源管理”页面,配置输入和输出数据源信息
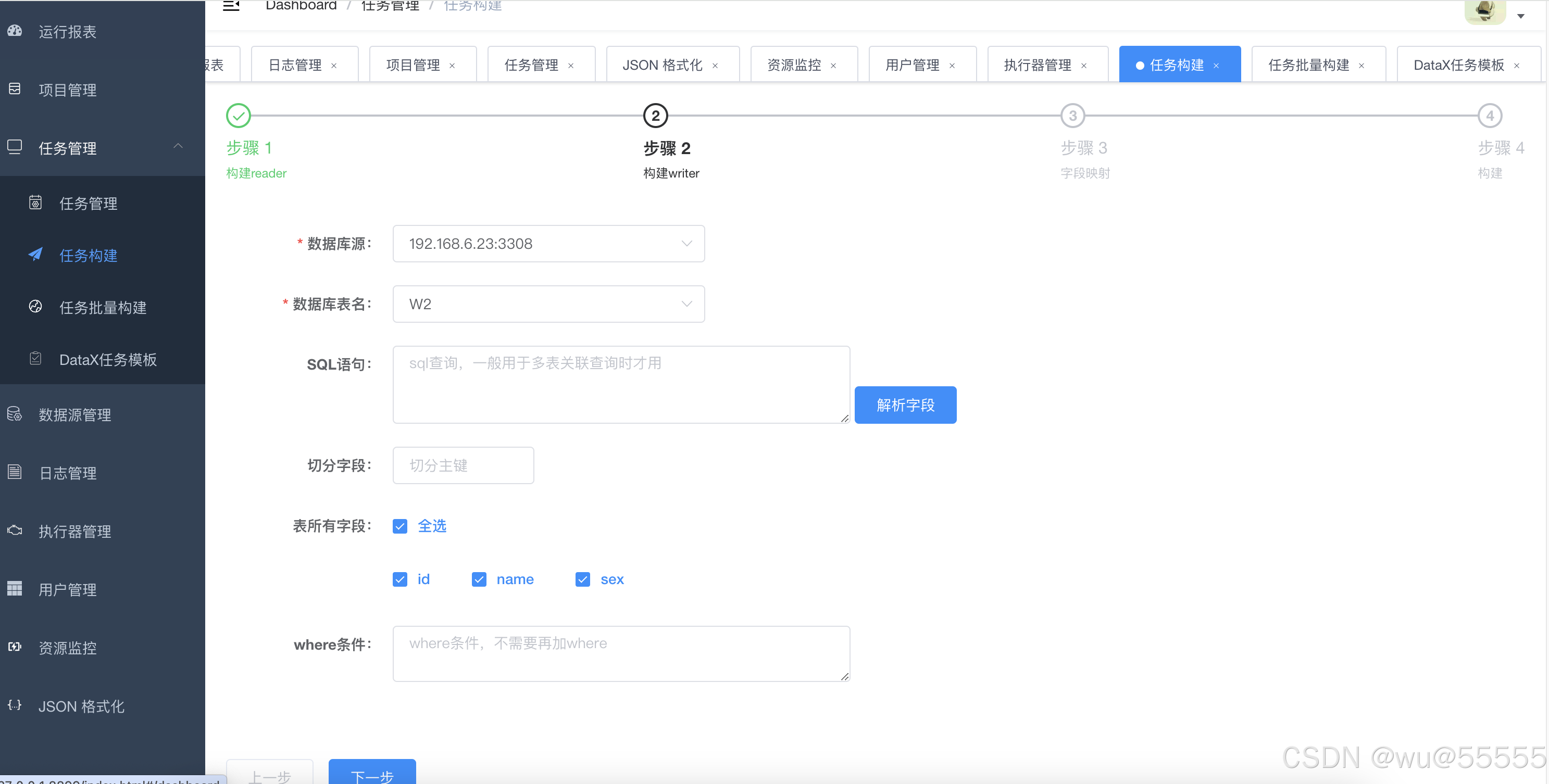
1、进入“任务构建”页面,在步骤1中输入来源库相关信息,相当于是配置datax json配置中的reader部分
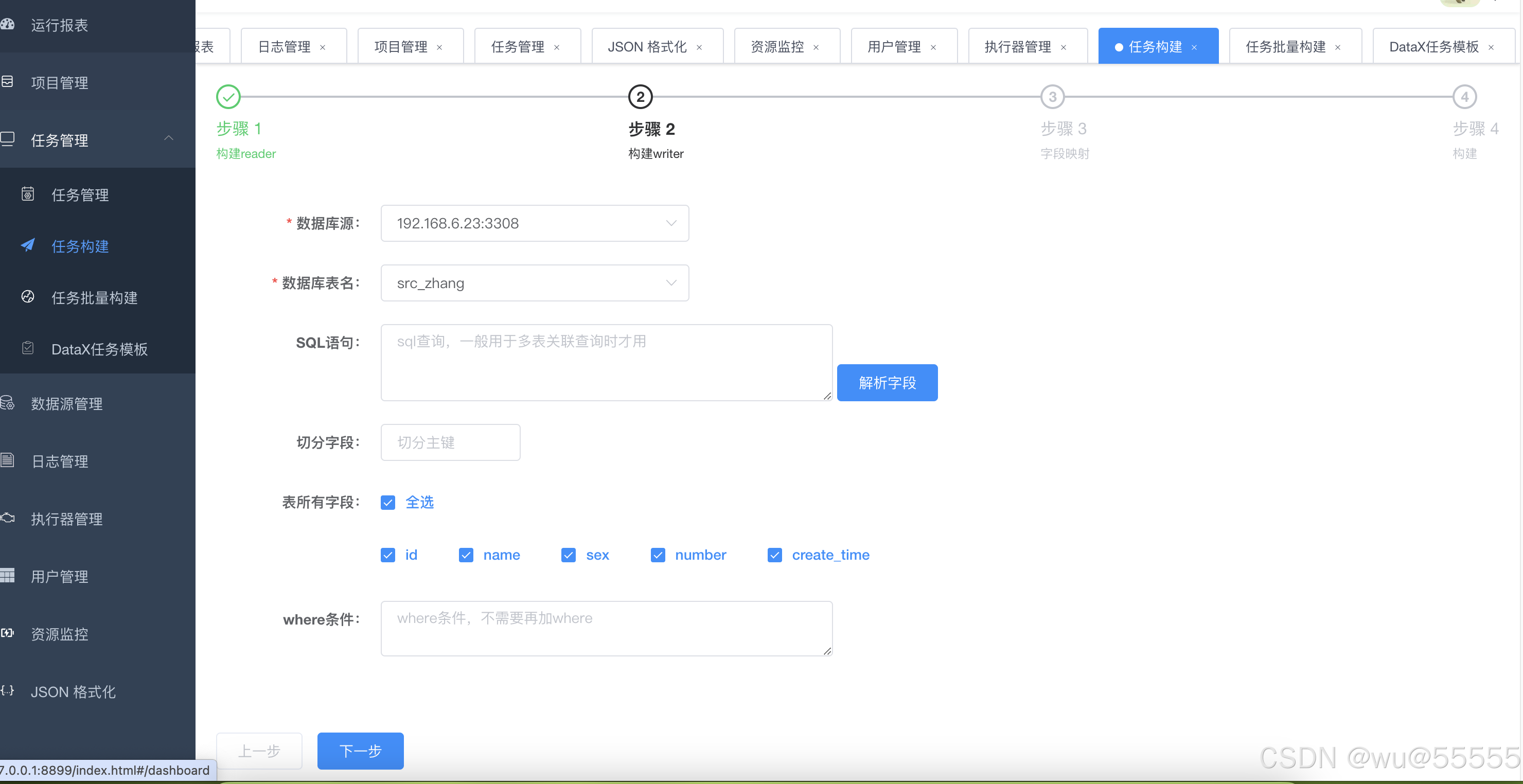
2、在步骤2中配置输出表字段信息,相当于配置writer
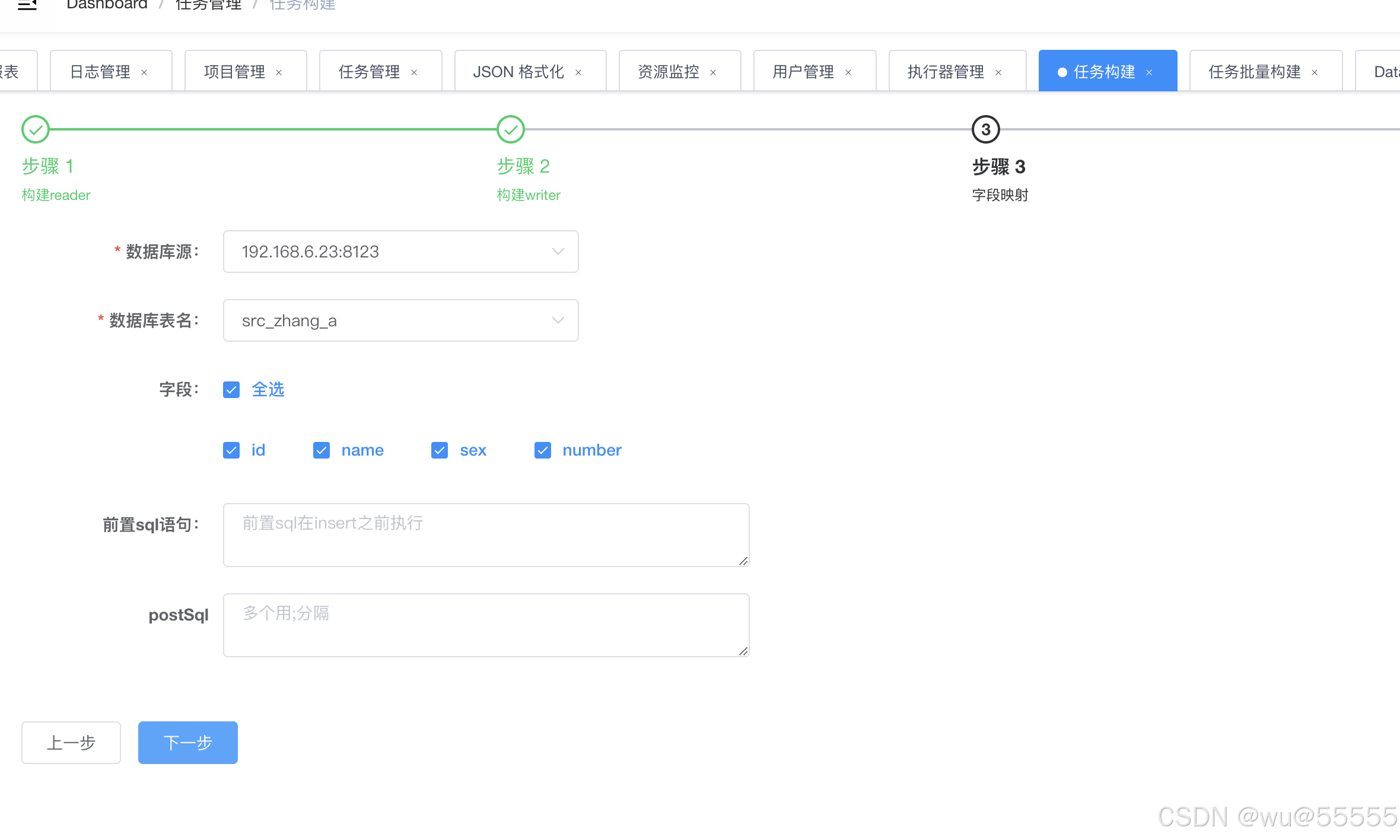
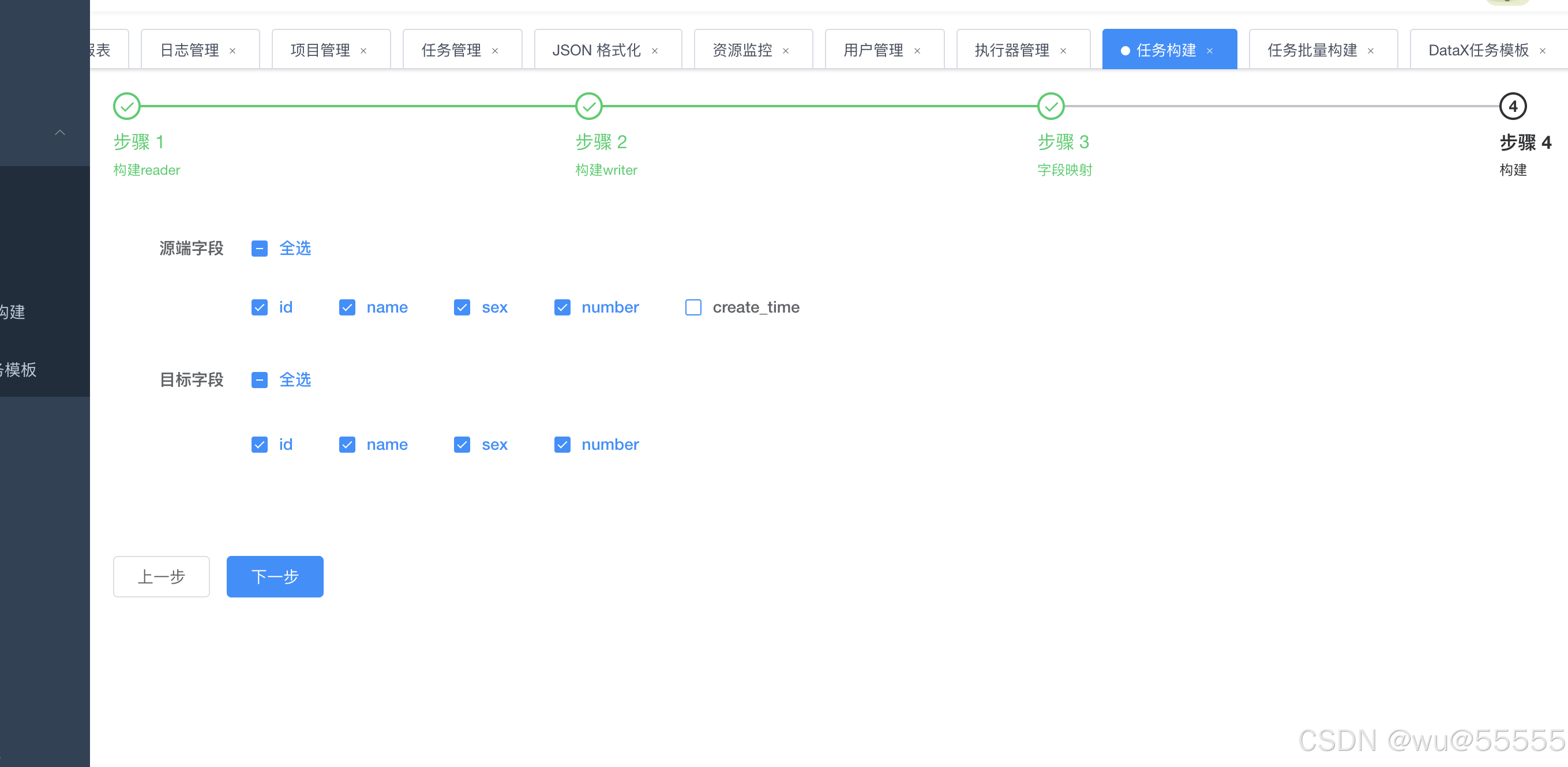
3、构建需要将哪些字段进行映射
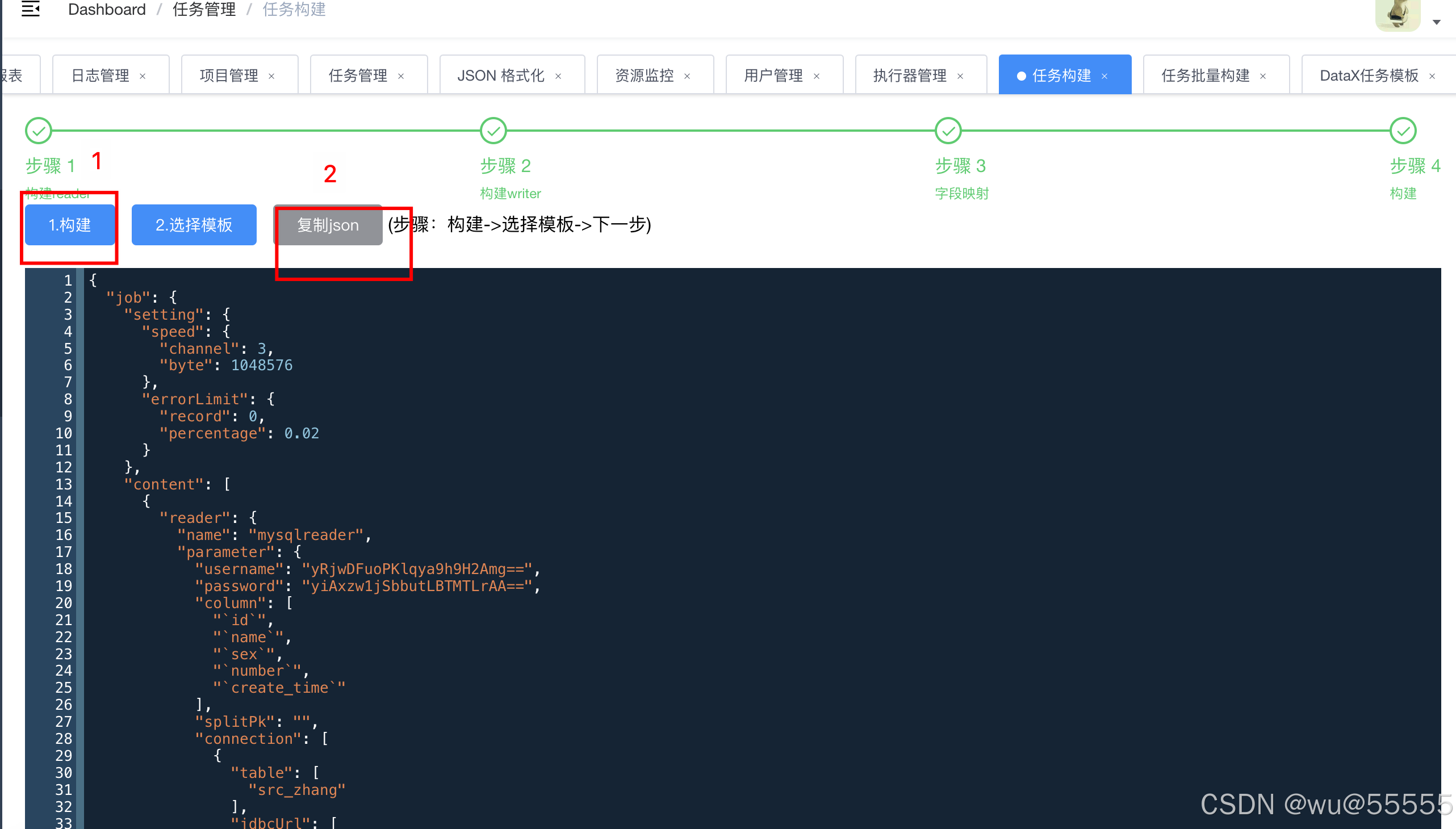
4、点击构建,然后复制json
5、在“任务管理”页面选择添加,配置执行器和cron定时配置,并将刚刚复制的json粘贴到该json框中
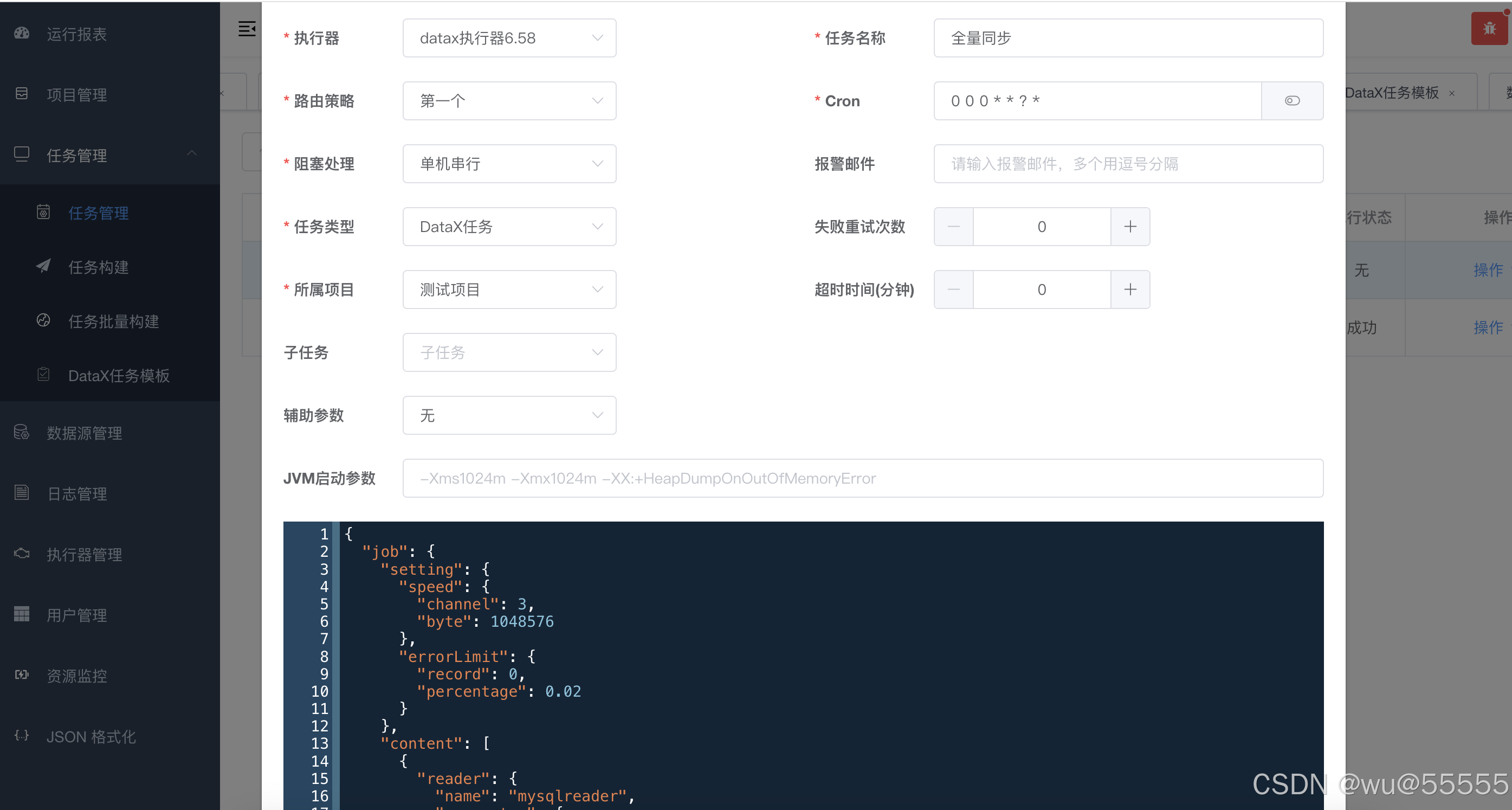
6、选择任务“执行一次”,查看同步情况
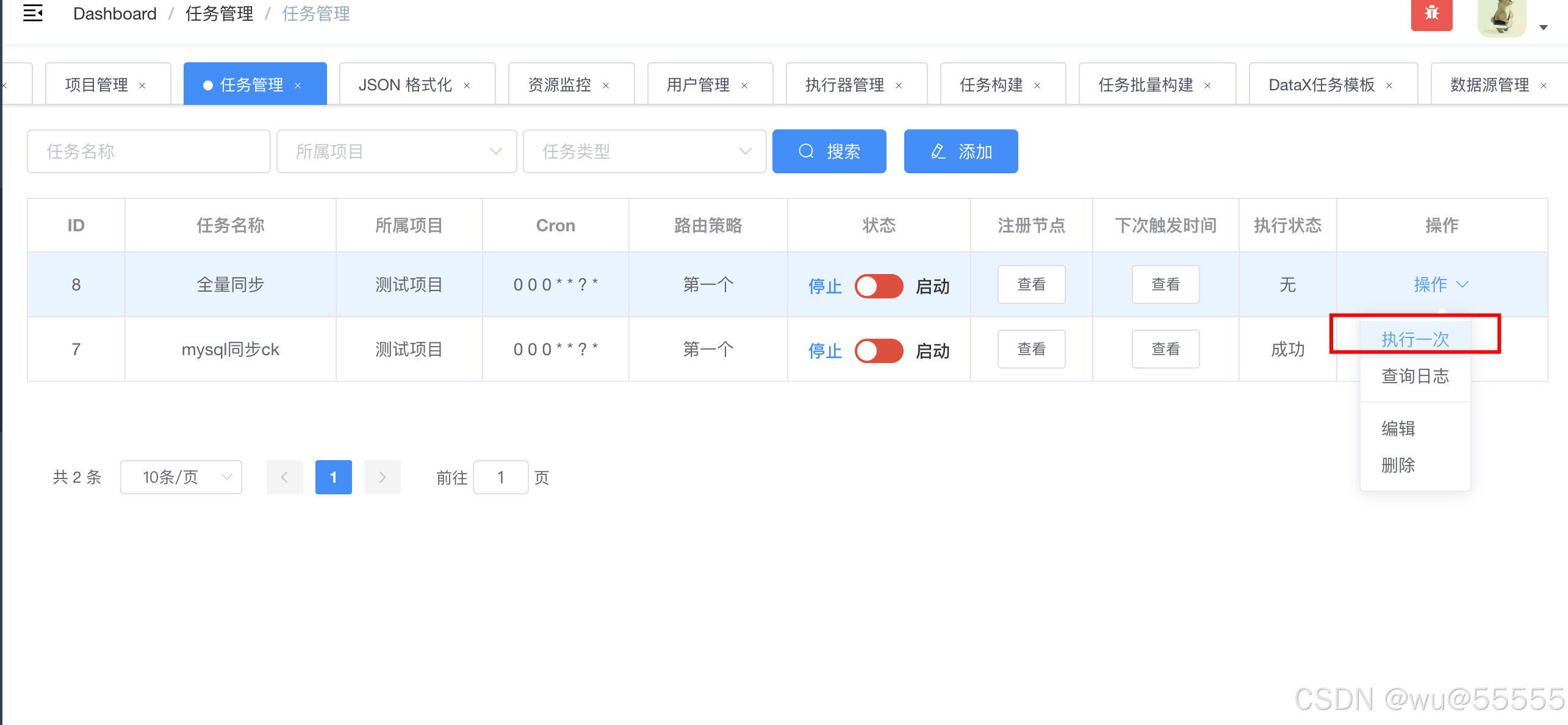
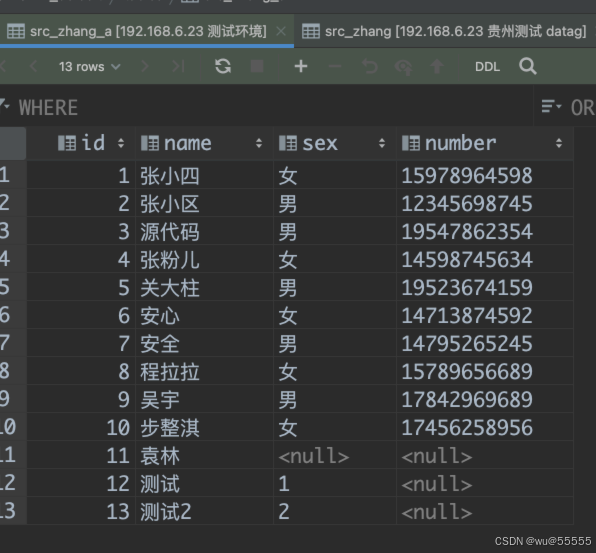
7、查看目标表,可以看到数据都同步过来了
2.2 增量数据同步配置
1、datax-web中支持增量字段配置,在辅助参数中选择增量字段类型,比如我们这里以自增id为例,就配置为主键自增,如果你是以创建时间之类的字段作为增量字段的,就选时间自增
主键开始ID可以输入你期望开始同步的值,比如我们这里因为前面已经执行过1~13数据的同步了,那就让他以13后开始同步
ID增量参数,这里的配置固定格式是-D参数名=%s -D参数名2=%s,如果参数值是字符串那么就是-D参数名='%s' -D参数名2='%s'。其中%s为占位符,后续会替换为具体的值

2、另外在json配置中,要将reader配置中增加"where"部分,注意该配置项是与connection同级的,其中的startId,endId就是上面配置的参数名,注意名称上要保持一致。
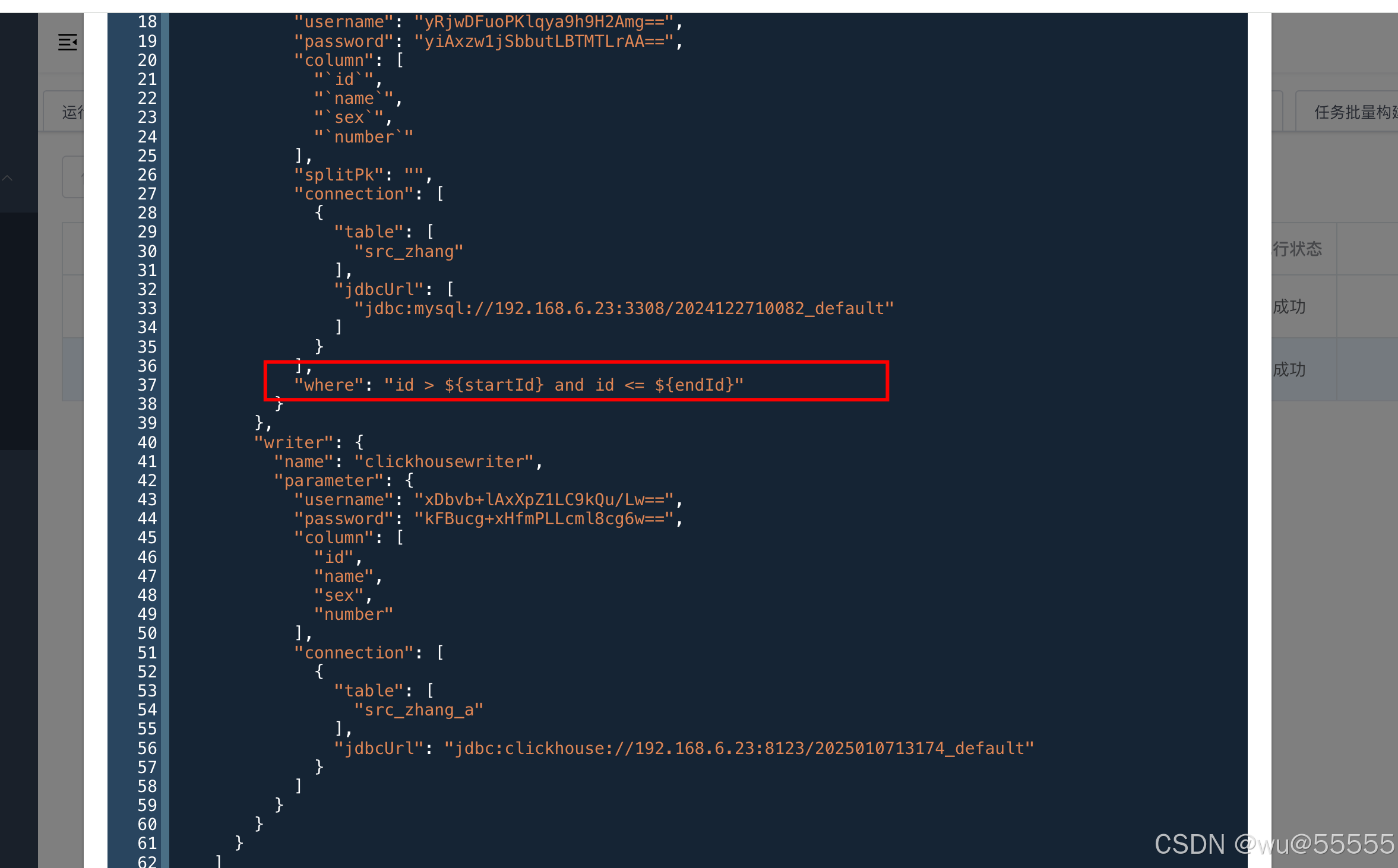
{
"job": {
"setting": {
"speed": {
"channel": 3,
"byte": 1048576
},
"errorLimit": {
"record": 0,
"percentage": 0.02
}
},
"content": [
{
"reader": {
"name": "mysqlreader",
"parameter": {
"username": "yRjwDFuoPKlqya9h9H2Amg==",
"password": "yiAxzw1jSbbutLBTMTLrAA==",
"column": [
"`id`",
"`name`",
"`sex`",
"`number`"
],
"splitPk": "",
"connection": [
{
"table": [
"src_zhang"
],
"jdbcUrl": [
"jdbc:mysql://192.168.6.23:3308/2024122710082_default"
]
}
],
"where": "id > ${startId} and id <= ${endId}"
}
},
"writer": {
"name": "clickhousewriter",
"parameter": {
"username": "xDbvb+lAxXpZ1LC9kQu/Lw==",
"password": "kFBucg+xHfmPLLcml8cg6w==",
"column": [
"id",
"name",
"sex",
"number"
],
"connection": [
{
"table": [
"src_zhang_a"
],
"jdbcUrl": "jdbc:clickhouse://192.168.6.23:8123/2025010713174_default"
}
]
}
}
}
]
}
}
3、保存后,我们再启动一次任务,我们将源数据增加一条,再执行一次同步
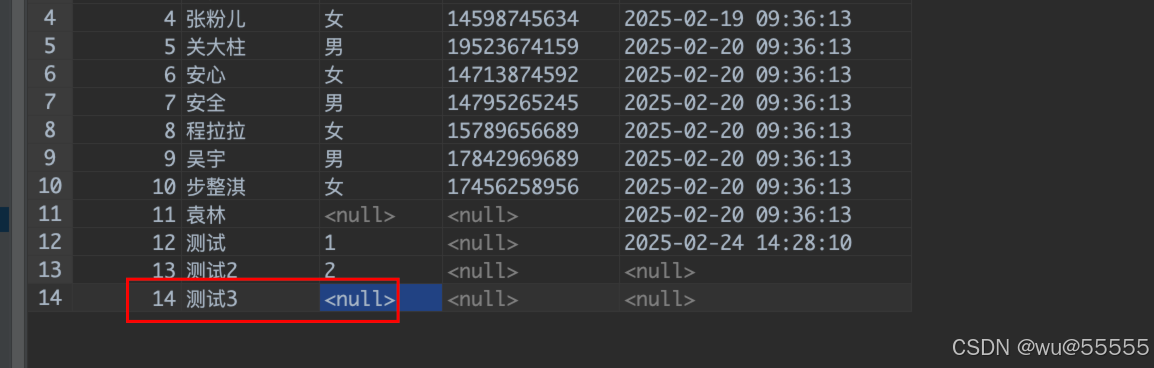
4、在日志管理中可以看到同步的sql信息,可以看到其配置就是按照起始id和当前最大记录值来替换的
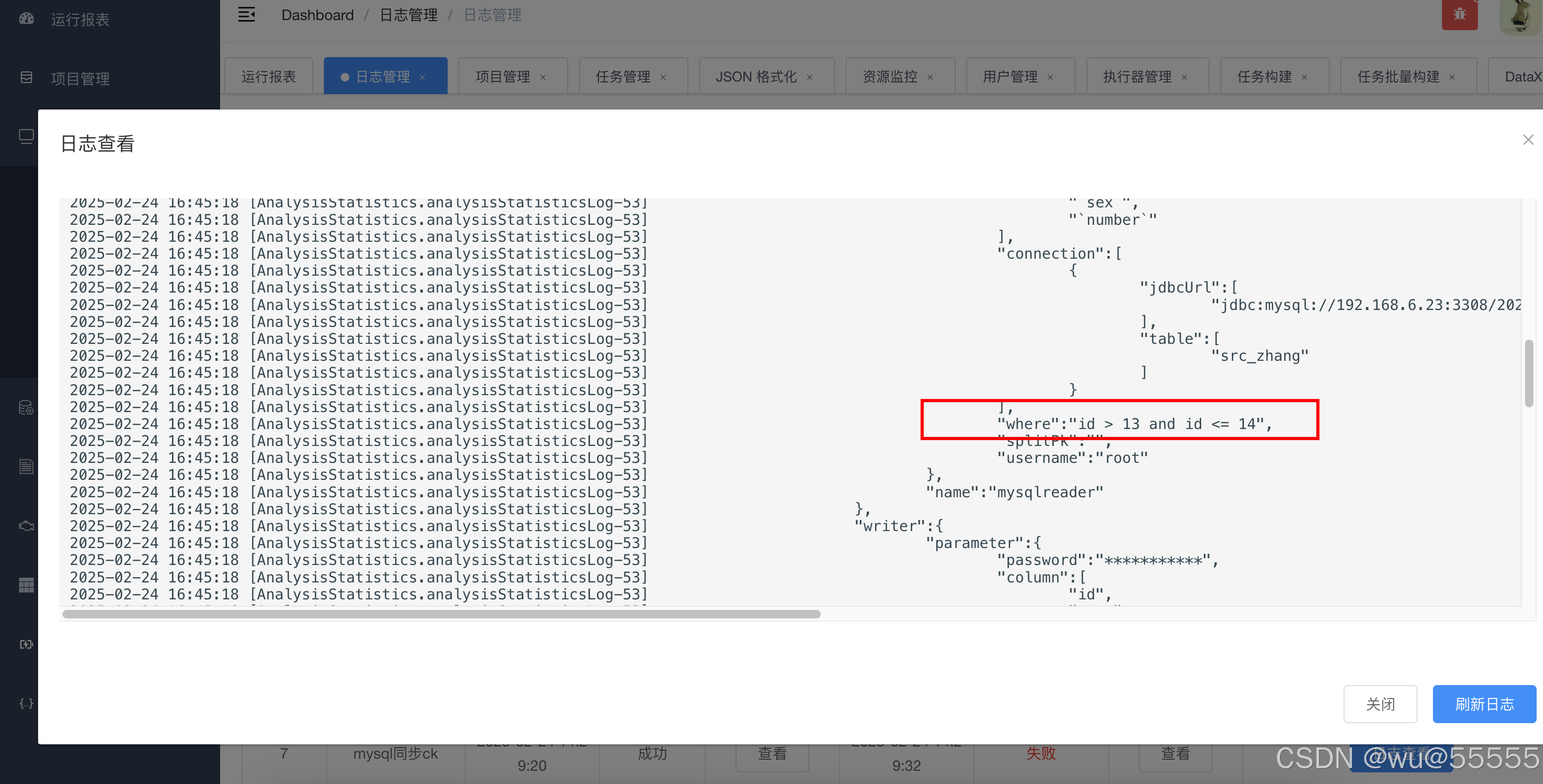
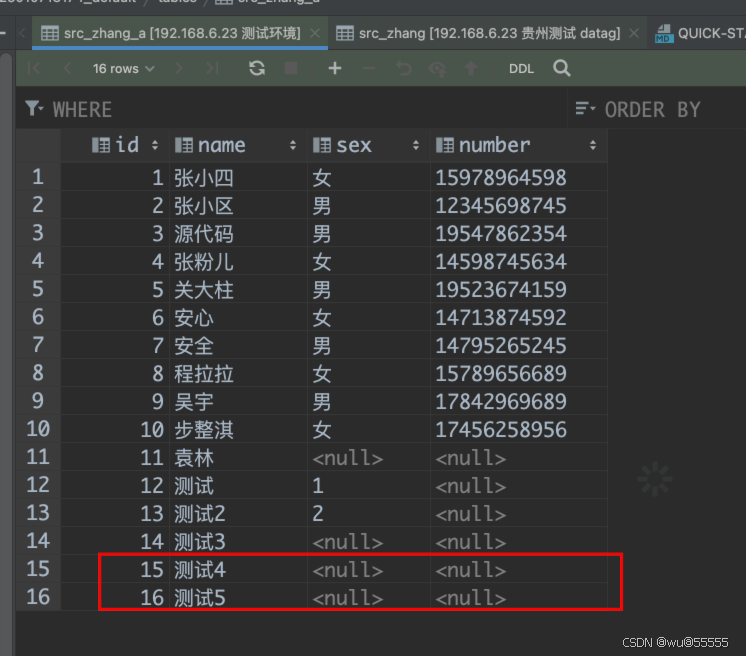
5、在目标数据库中也可以看到新增同步的数据14
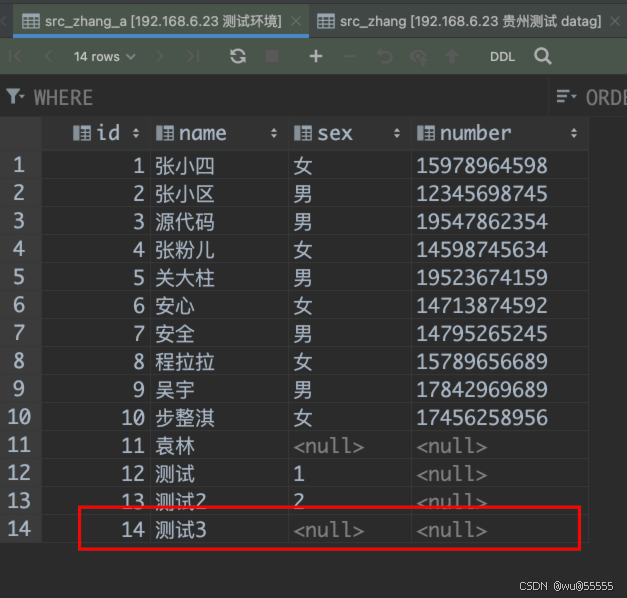
6、我们再在来源表中新增两条数据
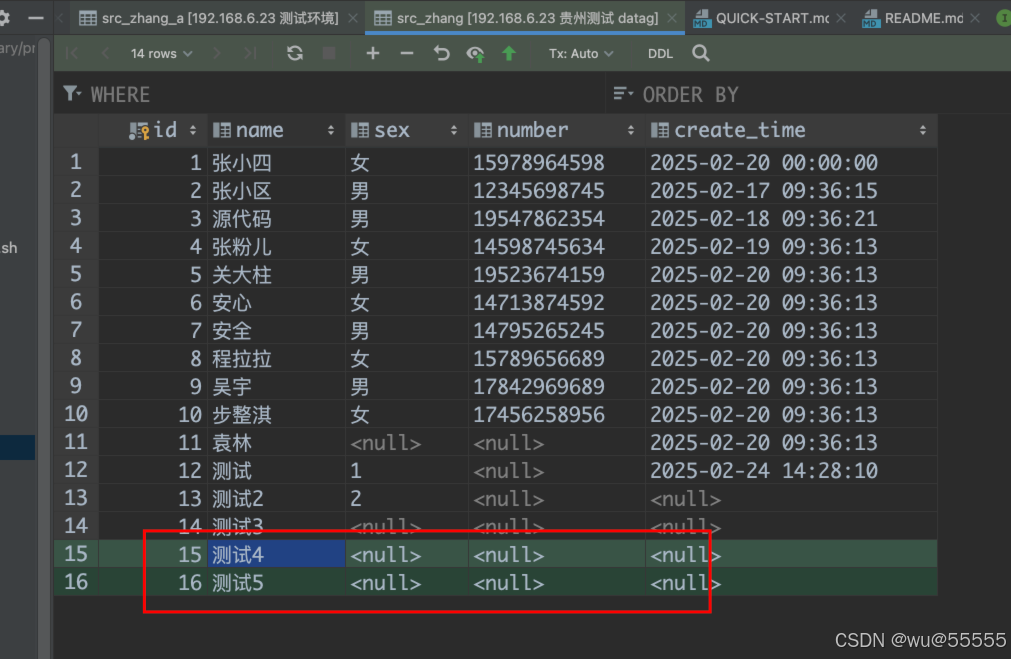
7、再查看日志信息,会发现起始id和终止id都替换为了最新的数据,并且衔接上了上一次同步的终止id最为起始id,如此就实现了自动的增量数据同步
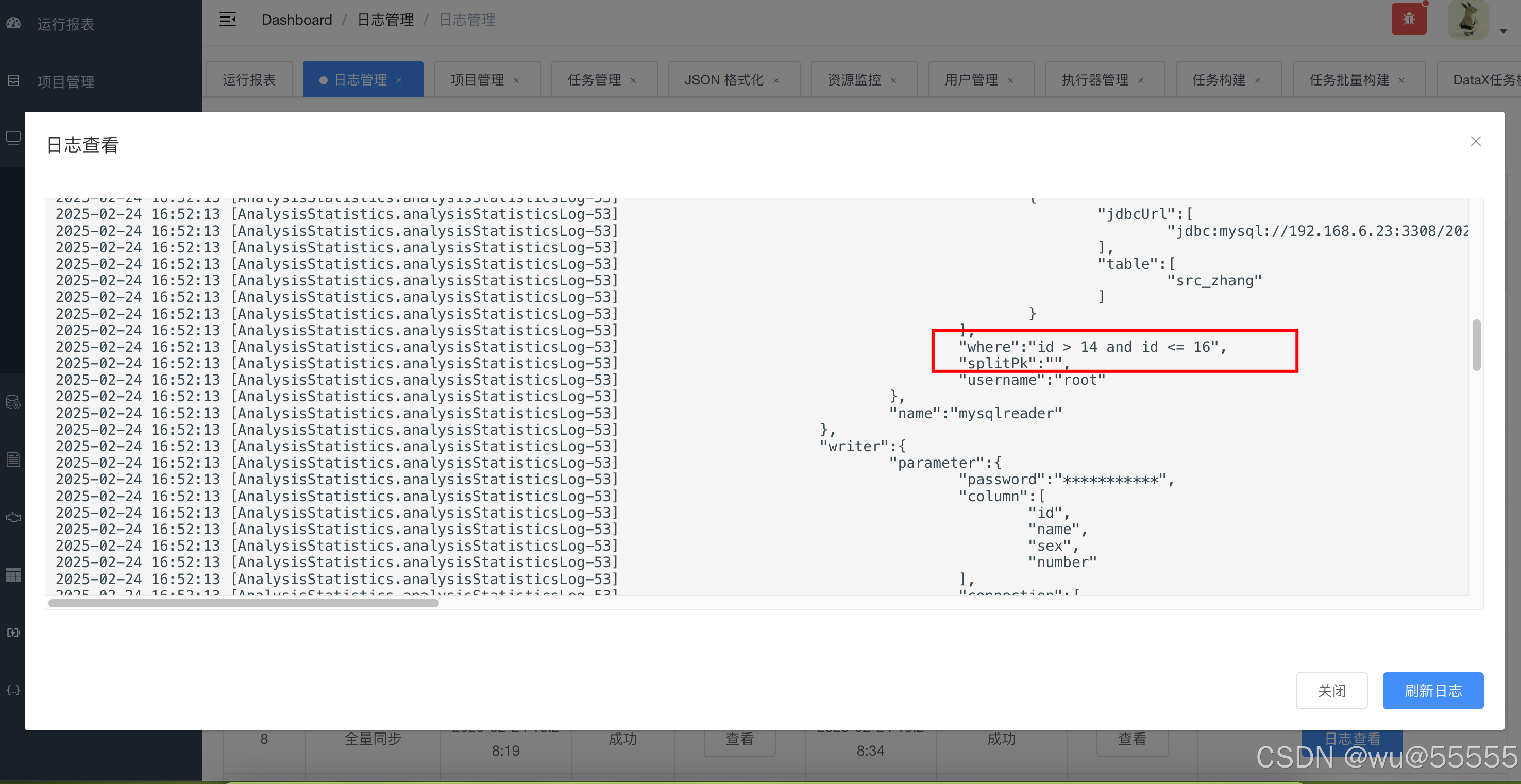
当然目标表中也是将两条新增数据同步进去了
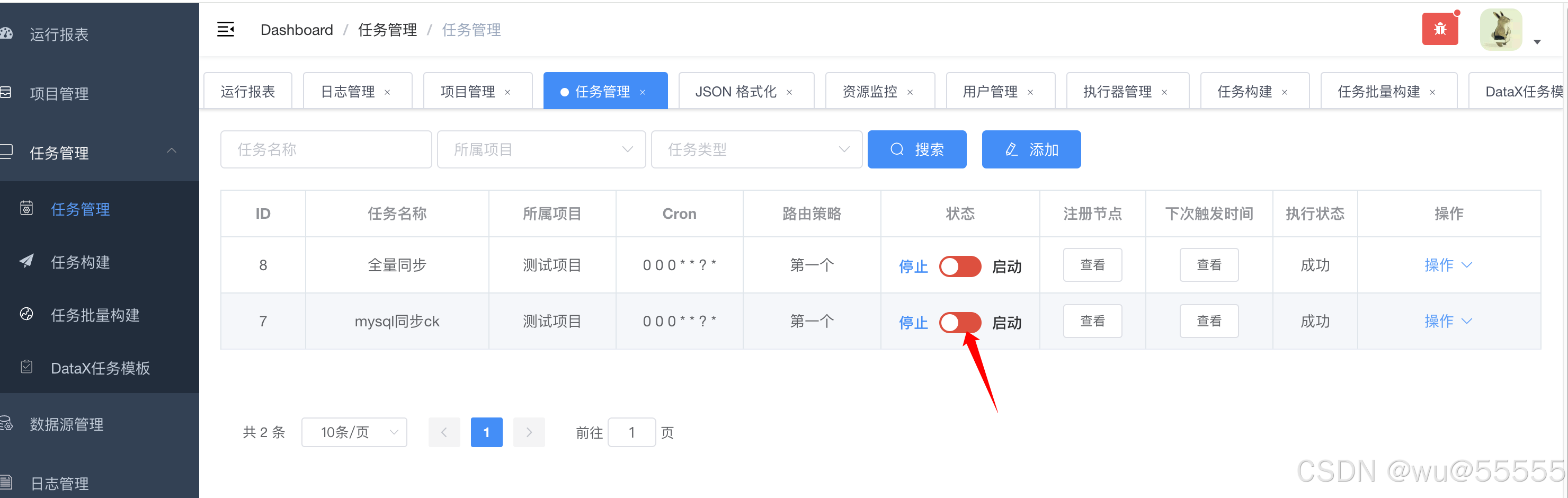
8、如果要开启定时调度,在任务管理中点击状态按钮即可开启,让其定时自动同步
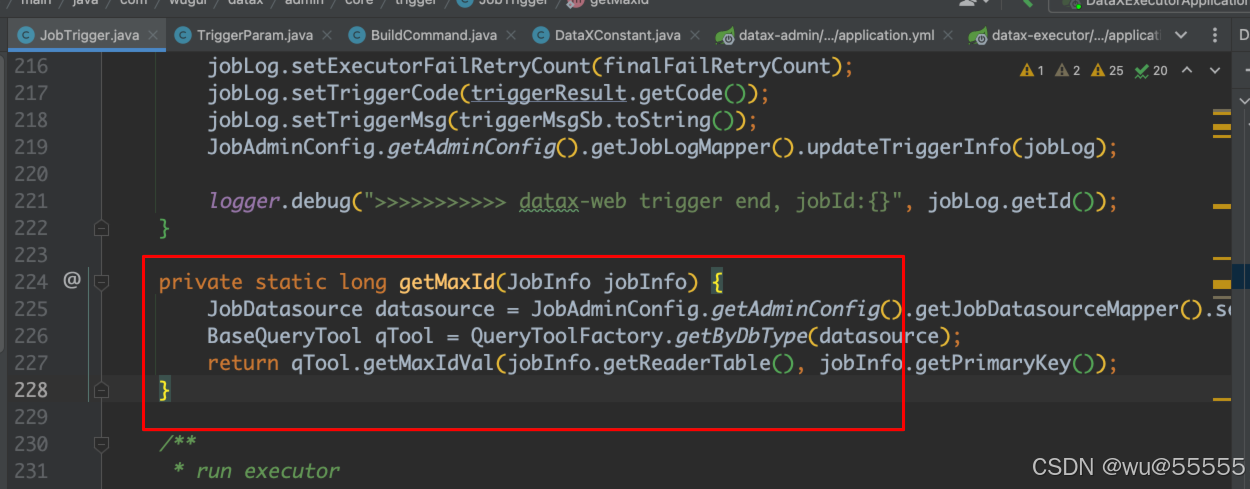
9、这里再额外拓展一下,datax-web中是通过将上一次任务的max_id记录在job_log表中,再执行时从该表获取数据,如果你修改了任务配置,会导致该任务的startId重置
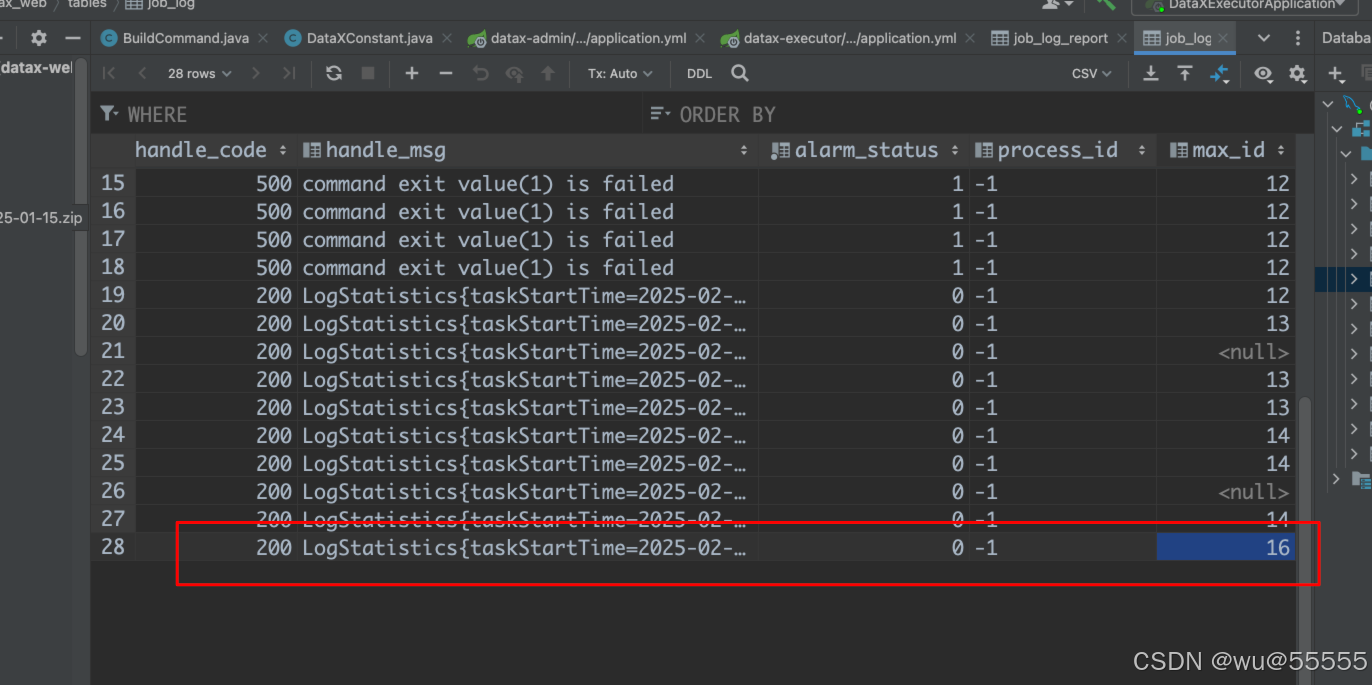
而maxId则是通过getMaxId方法来从数据库查询获取的,有兴趣的可以阅读源码来了解这一流程
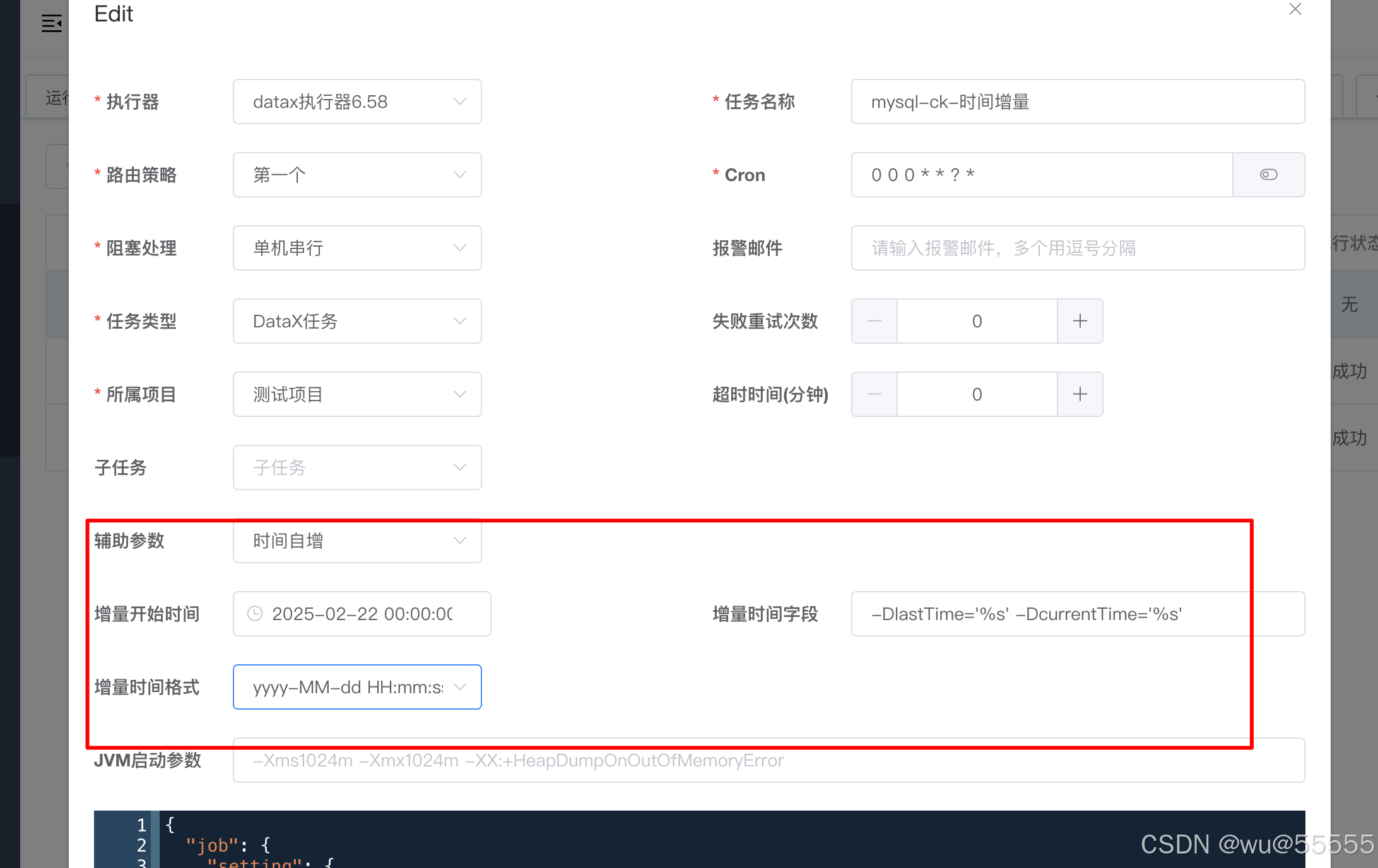
2.3 时间类型增量同步配置
1、任务配置中选择时间自增, 选择对应的时间字段和时间格式,注意这里的时间字段配置是-DlastTime='%s' -DcurrentTime='%s'(中间有一个空格)
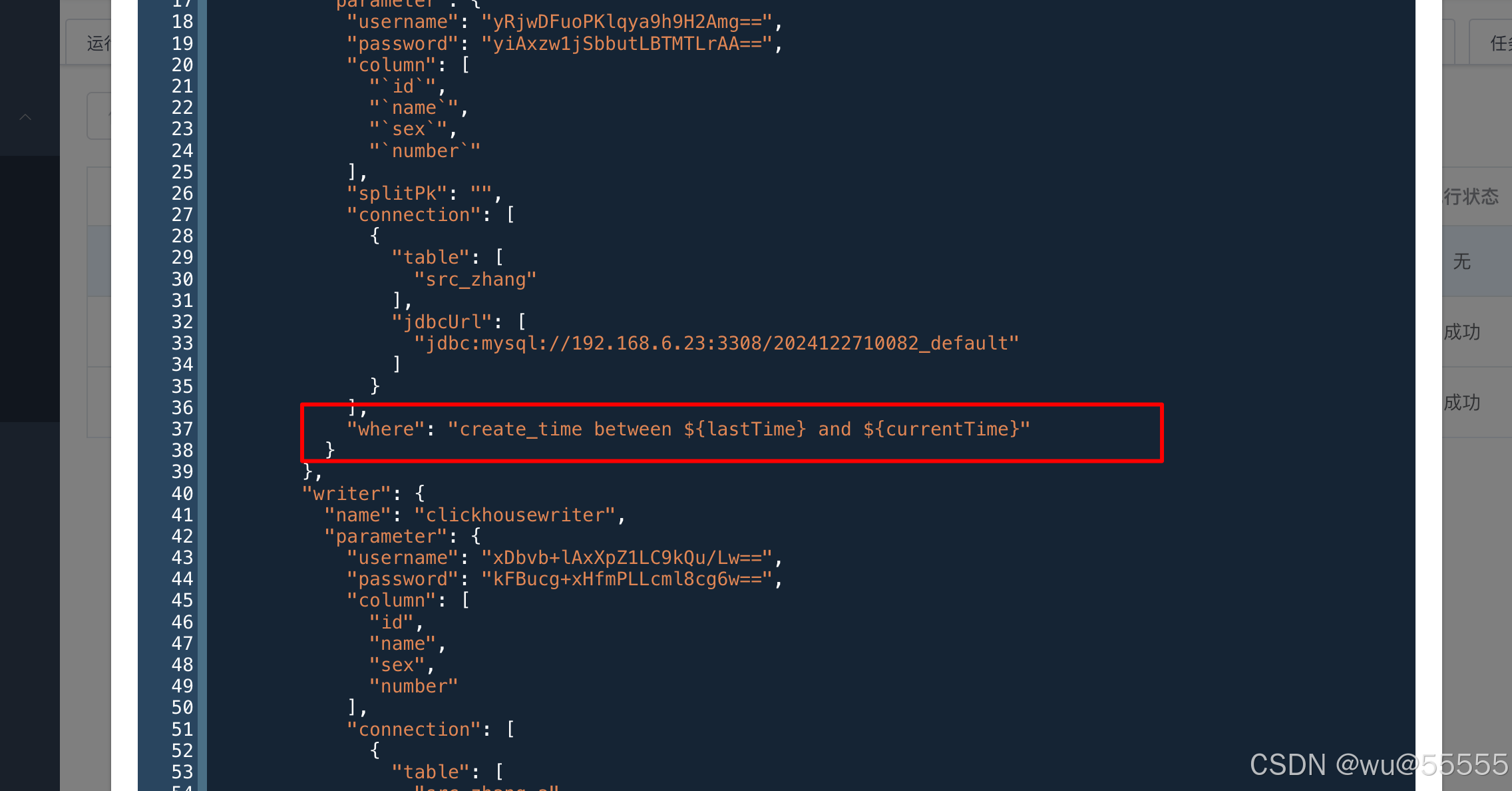
2、where配置中用between ... and ... 来进行时间的比较,这里就不用加引号了,前面已经配置过了。
3. 总结
如此,我们就通过datax-web实现了数据的增量、全量定时同步,当然也可以参考datax-web的思路,将maxId或者triggerTime记录到数据库,下次执行时从数据库获取然后利用datax -p参数替换占位符参数,以自定义实现定时同步


















 1505
1505

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











