







1、APACHE KAFKA概念
2、KAFKA群起脚本
zookeeper群起脚本
[atguigu@hadoop102 bin]$ cat myzookeeper
#!/bin/bash
if [ $# -lt 1 ]
then
echo "Input Args Error....."
exit
fi
for i in hadoop102 hadoop103 hadoop104
do
case $1 in
start)
echo "==================START $i ZOOKEEPER==================="
ssh $i /opt/module/apache-zookeeper-3.5.7-bin/bin/zkServer.sh start
;;
stop)
echo "==================STOP $i ZOOKEEPER==================="
ssh $i /opt/module/apache-zookeeper-3.5.7-bin/bin/zkServer.sh stop
;;
*)
echo "Input Args Error....."
exit
;;
esac
done
kafka群起脚本
[atguigu@hadoop102 bin]$ cat mykafka
#!/bin/bash
if [ $# -lt 1 ]
then
echo "Input Args Error....."
exit
fi
for i in hadoop102 hadoop103 hadoop104
do
case $1 in
start)
echo "==================START $i KAFKA==================="
ssh $i /opt/module/kafka/bin/kafka-server-start.sh -daemon /opt/module/kafka/config/server.properties
;;
stop)
echo "==================STOP $i KAFKA==================="
ssh $i /opt/module/kafka/bin/kafka-server-stop.sh stop
;;
*)
echo "Input Args Error....."
exit
;;
esac
done
topic增删查
kafka describe 显示结果解释
# 创建topic
[atguigu@hadoop102 ~]$ kafka-topics.sh --zookeeper hadoop102:2181 --create --replication-factor 3 --partitions 1 --topic first
# 查看topic
[atguigu@hadoop102 ~]$ kafka-topics.sh --zookeeper hadoop102:2181 --list
# 删除topic
[atguigu@hadoop102 ~]$ kafka-topics.sh --zookeeper hadoop102:2181 --delete --topic seconder
# 查看topic属性
[atguigu@hadoop102 ~]$ kafka-topics.sh --zookeeper hadoop102:2181 --describe --topic first
kafka修改Topic副本数和分区数
# 修改topic副本数
[atguigu@hadoop102 data]$ kafka-topics.sh --zookeeper hadoop102:2181 --create --replication-factor 1 --partitions 3 --topic first
Created topic first.
[atguigu@hadoop102 data]$ kafka-topics.sh --zookeeper hadoop102:2181 --describe --topic first
Topic: first PartitionCount: 3 ReplicationFactor: 1 Configs:
Topic: first Partition: 0 Leader: 2 Replicas: 2 Isr: 2
Topic: first Partition: 1 Leader: 0 Replicas: 0 Isr: 0
Topic: first Partition: 2 Leader: 1 Replicas: 1 Isr: 1
[atguigu@hadoop103 data]$ cat << EOF > increase-replication-factor.json
> {"version":1,
> "partitions":[
> {"topic":"first","partition":0,"replicas":[0,2]},
> {"topic":"first","partition":1,"replicas":[0,1]},
> {"topic":"first","partition":2,"replicas":[1,2]}
> ]
> }
> EOF
[atguigu@hadoop102 data]$ kafka-reassign-partitions.sh --zookeeper hadoop102:2181 --reassignment-json-file /opt/data/increase-replication-factor.json --execute
Current partition replica assignment
{"version":1,"partitions":[{"topic":"first","partition":2,"replicas":[1],"log_dirs":["any"]},{"topic":"first","partition":1,"replicas":[0],"log_dirs":["any"]},{"topic":"first","partition":0,"replicas":[2],"log_dirs":["any"]}]}
Save this to use as the --reassignment-json-file option during rollback
Successfully started reassignment of partitions.
[atguigu@hadoop102 data]$ kafka-topics.sh --zookeeper hadoop102:2181 --describe --topic first
Topic: first PartitionCount: 3 ReplicationFactor: 2 Configs:
Topic: first Partition: 0 Leader: 2 Replicas: 0,2 Isr: 2,0
Topic: first Partition: 1 Leader: 0 Replicas: 0,1 Isr: 0,1
Topic: first Partition: 2 Leader: 1 Replicas: 1,2 Isr: 1,2
# 修改topic分区数,分区数只能增加,不能减少
[atguigu@hadoop102 ~]$ kafka-topics.sh --zookeeper hadoop102:2181 --alter --topic first --partitions 6
[atguigu@hadoop102 data]$ kafka-topics.sh --zookeeper hadoop102:2181 --describe --topic first
Topic: first PartitionCount: 6 ReplicationFactor: 2 Configs:
Topic: first Partition: 0 Leader: 2 Replicas: 0,2 Isr: 2,0
Topic: first Partition: 1 Leader: 0 Replicas: 0,1 Isr: 0,1
Topic: first Partition: 2 Leader: 1 Replicas: 1,2 Isr: 1,2
Topic: first Partition: 3 Leader: 0 Replicas: 0,2 Isr: 0,2
Topic: first Partition: 4 Leader: 1 Replicas: 1,0 Isr: 1,0
Topic: first Partition: 5 Leader: 2 Replicas: 2,1 Isr: 2,1
topic生产消费
# 产生实时数据
[atguigu@hadoop102 ~]$ kafka-console-producer.sh --broker-list hadoop102:9092 --topic first
# 消费实时数据
[atguigu@hadoop102 ~]$ kafka-console-consumer.sh --bootstrap-server hadoop102:9092 --topic first
# 会把主题中现有的所有的数据都读取出来
[atguigu@hadoop102 ~]$ kafka-console-consumer.sh --bootstrap-server hadoop102:9092 --topic first --from-beginning
3、kafka架构
3.1、Kafka文件存储机制

3.2、kafka分区策略
Kafka 分区策略
Kafka分区分配策略-RangeAssignor、RoundRobinAssignor、StickyAssignor
Kafka分区分配策略分析——重点:StickyAssignor
3.3、数据可靠性保证
kafka数据可靠性深度解读
kafka系列之数据不丢失的重要保证—ACK(5)
1、Producer收到Topic partition的ACK才会进行下一轮的message发送,否则重新发送数据;
2、Topic partition全部follower(ISR中的follower)完成同步,leader才发送ACK;
3、in-sync replica set (ISR),意为和leader保持同步的follower集合;
4、follower长时间未向leader同步数据,其将被踢出ISR,该时间阈值由replica.lag.time.max.ms参数设定;
5、不是所有情况都需要ISR中的follower响应后,leader才返回ACK(ACK={0(At Most Once),1(会丢失数据),-1(At Least Once)});
6、LEO指的是每个follower最大的offset,ISR队列中最小的LEO称为HW(消费者能见到的最大的offset);
7、follower发生故障后会被临时踢出ISR,待该follower恢复后,follower读取本地磁盘记录的上次HW,将log文件中高于HW的部分截取掉,从HW开始向leader进行同步,等该follower的LEO大于等于该Partition的HW,即follower追上leader之后,就可以重新加入ISR了;
8、leader发生故障之后,会从ISR中选出一个新的leader,之后,为保证多个副本之间的数据一致性,其余的follower会先将各自的log文件高于HW的部分截掉,然后从新的leader同步数据;
① acks = 0(至多一次)
生产者只负责发消息,不管Leader 和Follower 是否完成落盘就会发送ack 。这样能够最大降低延迟,但当Leader还未落盘时发生故障就会造成数据丢失;
这里其实就是相当于是异步的,不需要leader给予回复,producer立即返回,
② acks = 1(至多一次)
Leader将数据落盘后,不管Follower 是否落盘就会发送ack 。这样可以保证Leader节点内有一份数据,但当Follower还未同步时Leader发生故障就会造成数据丢失;
③ acks = -1(至少一次)
生产者等待Leader和ISR集合内的所有Follower 都完成同步才会发送ack 。
但当Follower同步完之后,Leader发送ack之前,Leader发生故障时,此时会重新从ISR内选举一个新的Leader,此时由于生产者没收到ack,于是生产者会重新发消息给新的Leader,此时就会造成数据重复;
总结:ACK=-1时保证数据不丢失但可能会重复,而follower和leader故障恢复机制只能保证数据一致性。
3.4、Exactly Once语义
0.11版本的Kafka,引入了一项重大特性:幂等性。所谓的幂等性就是指Producer不论向Server发送多少次重复数据,Server端都只会持久化一条。幂等性结合At Least Once语义,就构成了Kafka的Exactly Once语义。即:At Least Once + 幂等性 = Exactly Once
要启用幂等性,只需要将Producer的参数中enable.idempotence设置为true即可。Kafka的幂等性实现其实就是将原来下游需要做的去重放在了数据上游。开启幂等性的Producer在初始化的时候会被分配一个PID,发往同一Partition的消息会附带Sequence Number。而Broker端会对<PID, Partition, SeqNumber>做缓存,当具有相同主键的消息提交时,Broker只会持久化一条。
但是Producer重启PID就会变化,同时不同的Partition也具有不同主键,所以幂等性无法保证跨分区(即同一个Producer向不同Partition发送同一个message)或跨会话(即在不同会话下(重启前后),同一个Producer向同一个Partition发送同一个message)的Exactly Once。
3.5、kafka消费者
consumer采用pull(拉)模式从broker中读取数据,pull模式则可以根据consumer的消费能力以适当的速率消费消息。pull模式不足之处是,如果kafka没有数据,消费者可能会陷入循环中,一直返回空数据。针对这一点,Kafka的消费者在消费数据时会传入一个时长参数timeout,如果当前没有数据可供消费,consumer会等待一段时间之后再返回,这段时长即为timeout。
Kafka 0.9版本之前,consumer默认将offset保存在Zookeeper中,从0.9版本开始,consumer默认将offset保存在Kafka一个内置的topic中,该topic为__consumer_offsets。
# 查看__consumer_offsets内容
[atguigu@hadoop102 __consumer_offsets-49]$ kafka-run-class.sh kafka.tools.DumpLogSegments --files /opt/module/kafka/logs/__consumer_offsets-49/00000000000000000000.index --print-data-log
[atguigu@hadoop102 __consumer_offsets-49]$ kafka-run-class.sh kafka.tools.DumpLogSegments --files /opt/module/kafka/logs/__consumer_offsets-49/00000000000000000000.log --print-data-log
Kafka为什么能那么快?高效读写数据,原来是这样做到的
① 通过尽可能的将随机 I/O 转换为顺序 I/O并使用追加写的方式,以此来降低寻址时间和旋转延时,从而最大限度的提高 IOPS
② 通过删除整个文件的方式去删除 Partition 内的数据(Segment ),这种方式清除旧数据的方式,也避免了对文件的随机写操作
③ 通过Page Cache降低磁盘IO时间(小块写组装成大块写、无序写排序成有序写),Pagee Cache非JVM 堆内存,降低了GC负担
④ Memory Mapped Files(简称 mmap),当应用程序不需要对数据进行访问时,避免数据在内核空间与用户空间的来回拷贝
⑤ 通过 NIO 的 transferTo/transferFrom 调用操作系统的 sendfile 实现零拷贝,避免数据在内核空间与用户空间的来回拷贝
⑥ 在进行数据网络传输时,在一个批处理中累积多条记录 (包括读和写),使用更大的数据包,分摊了网络往返的开销
⑦ Producer 将数据压缩后发送给 broker,减少网络传输量,支持算法有Snappy、Gzip、LZ4,一般和批处理配套使用
⑧ 多partition、segment 并行读写数据
PS:使用 Page Cache、零拷贝技术mmap和sendfile 进行Kafka数据的交互时,在服务器宕机机时可能会造成数据丢失。
Zookeeper 在 Kafka 中的作用
Broker注册
# 打开zookeeper客户端
[atguigu@hadoop102 bin]$ zkCli.sh
# 查看所有broker的ID
[zk: localhost:2181(CONNECTED) 3] ls /brokers/ids
[0, 1, 2]
# 获取Broker注册信息
[zk: localhost:2181(CONNECTED) 5] get /brokers/ids/0
{"listener_security_protocol_map":{"PLAINTEXT":"PLAINTEXT"},"endpoints":["PLAINTEXT://hadoop102:9092"],"jmx_port":-1,"host":"hadoop102","timestamp":"1643511732953","port":9092,"version":4}
# Broker创建的节点类型是临时节点
[zk: localhost:2181(CONNECTED) 6] stat /brokers/ids/0
cZxid = 0xe0000007e
ctime = Sun Jan 30 11:02:12 CST 2022
mZxid = 0xe0000007e
mtime = Sun Jan 30 11:02:12 CST 2022
pZxid = 0xe0000007e
cversion = 0
dataVersion = 1
aclVersion = 0
ephemeralOwner = 0x40000036a500001
dataLength = 188
numChildren = 0
Topic注册
[zk: localhost:2181(CONNECTED) 10] ls /brokers/topics
[__consumer_offsets, first, test-topic]
[zk: localhost:2181(CONNECTED) 11] get /brokers/topics/first
{"version":2,"partitions":{"2":[0,2,1],"1":[2,1,0],"0":[1,0,2]},"adding_replicas":{},"removing_replicas":{}}
# 查看topics
[zk: localhost:2181(CONNECTED) 1] ls /brokers/topics
[__consumer_offsets, first, test-topic]
[zk: localhost:2181(CONNECTED) 2] ls /brokers/topics/first
[partitions]
# 查看first的partitions信息
[zk: localhost:2181(CONNECTED) 3] ls /brokers/topics/first/partitions
[0, 1, 2]
[zk: localhost:2181(CONNECTED) 4] get /brokers/topics/first/partitions/2/state
{"controller_epoch":11,"leader":1,"version":1,"leader_epoch":27,"isr":[1,2,0]}
[zk: localhost:2181(CONNECTED) 5] get /brokers/topics/first/partitions/1/state
{"controller_epoch":11,"leader":1,"version":1,"leader_epoch":27,"isr":[1,2,0]}
[zk: localhost:2181(CONNECTED) 6] get /brokers/topics/first/partitions/0/state
{"controller_epoch":11,"leader":1,"version":1,"leader_epoch":31,"isr":[1,2,0]}
# 查看kafka的topic信息
[atguigu@hadoop102 ~]$ kafka-topics.sh --zookeeper hadoop102:2181 --describe --topic first
Topic: first PartitionCount: 3 ReplicationFactor: 3 Configs:
Topic: first Partition: 0 Leader: 1 Replicas: 1,0,2 Isr: 1,2,0
Topic: first Partition: 1 Leader: 1 Replicas: 2,1,0 Isr: 1,2,0
Topic: first Partition: 2 Leader: 1 Replicas: 0,2,1 Isr: 1,2,0
3.6、事务
Kafka Exactly Once和事务
kafka事务机制
数据库事务,原子性(Atomic)、一致性(Consistency)、隔离性(Isolation)、持久性(Durabiliy)
幂等生产者和事务生产者是一回事吗?
幂等性 Producer只能保证单分区上的幂等性,即一个幂等性 Producer 能够保证某个主题的一个分区上不出现重复消息,它无法实现多个分区的幂等性。其次,它只能实现单会话上的幂等性,不能实现跨会话的幂等性。
数据库事务由严格的定义,它必须满足4个特性:
原子性(Atomicity),一致性(consistency),隔离性(Isolation),持久性(Durability)。
原子性: 表示组成一个事务的多个数据库操作是一个不可分割的原子单元,只有所有的操作执行成功,整个事务才提交。事务中的任何一个数据库操作失败,已经执行的任何操作都必须被撤销,让数据库返回初始状态。
一致性: 事务操作成功后,数据库所处的状态和他的业务规则是一致的,即数据不会被破坏。如A账户转账100元到B账户,不管操作成功与否,A和B账户的存款总额是不变的。
隔离性: 在并发数据操作时,不同的事务拥有各自的数据空间,他们的操作不会对对方产生敢逃。准确地说,并非要求做到完全无干扰。数据库规定了多种事务隔离界别,不同的隔离级别对应不用的干扰成都,隔离级别越高,数据一致性越好,但并发行越弱。
持久性: 一旦事务提交成功后,事务中所有的数据操作都必须被持久化到数据库中。即使在事务提交后,数据库马上崩溃,在数据库重启时,也必须保证能够通过某种机制恢复数据。
Kafka 自 0.11 版本开始提供了对事务的支持,目前主要是在 read committed 隔离级别上做事情。它能保证多条消息原子性地写入到目标分区,同时也能保证 Consumer 只能看到事务成功提交的消息。
事务型 Producer 能够保证将消息原子性地写入到多个分区中。这批消息要么全部写入成功,要么全部失败。另外,事务型 Producer 也不惧进程的重启。Producer 重启回来后,Kafka 依然保证它们发送消息的精确一次处理。
简单来说,幂等性 Producer 和事务型 Producer 都是 Kafka 社区力图为 Kafka 实现精确一次处理语义所提供的工具,只是它们的作用范围是不同的。幂等性 Producer 只能保证单分区、单会话上的消息幂等性;而事务能够保证跨分区、跨会话间的幂等性。从交付语义上来看,自然是事务型 Producer 能做的更多。不过,切记天下没有免费的午餐。比起幂等性 Producer,事务型 Producer 的性能要更差,在实际使用过程中,我们需要仔细评估引入事务的开销,切不可无脑地启用事务。
3.6.1 Producer事务
为了实现跨分区跨会话的事务,需要引入一个全局唯一的Transaction ID,并将Producer获得的PID和Transaction ID绑定。这样当Producer重启后就可以通过正在进行的Transaction ID获得原来的PID。
为了管理Transaction,Kafka引入了一个新的组件Transaction Coordinator。Producer就是通过和Transaction Coordinator交互获得Transaction ID对应的任务状态。Transaction Coordinator还负责将事务所有写入Kafka的一个内部Topic,这样即使整个服务重启,由于事务状态得到保存,进行中的事务状态可以得到恢复,从而继续进行。
3.6.2 Consumer事务(精准一次性消费)
上述事务机制主要是从Producer方面考虑,对于Consumer而言,事务的保证就会相对较弱,尤其是无法保证Commit的信息被精确消费。出于以下原因,Kafka并不能保证事务中所有已提交的消息都能够被消费:
1.对采用日志压缩策略的主题而言,事务中的某些消息有可能被清理(相同key的消息,后写入的消息会覆盖前写入的消息)
2.事务中消息可能分布在同一个分区的多个日志分段LogSegment中,当老的日志分段被删除时,对应的消息可能会丢失
3.消费者可以通过seek()方法访问任意offset的消息,从而可能遗漏事务中的部分消息。
4.消费者在消费时可能没有分配到事务内所有分区,如此它就不能读取事务中的所有消息。
如果想完成Consumer端的精准一次性消费,一个基本操作,kafka消费端将消费过程和提交offset过程做原子绑定。此时我们需要将kafka的offset保存到支持事务的自定义介质(比如mysql)。
4、Kafka API
4.1、Producer API
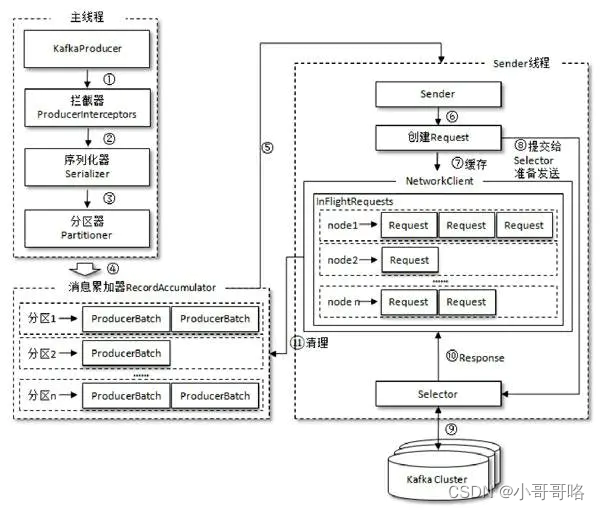
Properties props = new Properties();
props.put("bootstrap.servers", "localhost:9092");
props.put("acks", "all");
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
Producer<String, String> producer = new KafkaProducer<>(props);
for (int i = 0; i < 100; i++)
producer.send(new ProducerRecord<String, String>("my-topic", Integer.toString(i), Integer.toString(i)));
producer.close();
Since the send call is asynchronous it returns a Future for the RecordMetadata that will be assigned to this record. Invoking get() on this future will block until the associated request completes and then return the metadata for the record or throw any exception that occurred while sending the record.
4.2、Consumer API
手动提交offset的方法有两种:分别是commitSync(同步提交)和commitAsync(异步提交)。两者的相同点是,都会将本次poll的一批数据最高的偏移量提交;不同点是,commitSync阻塞当前线程,一直到提交成功,并且会自动失败重试(由不可控因素导致,也会出现提交失败);而commitAsync则没有失败重试机制,故有可能提交失败。
5、Kafka Eagle
Kafka-Eagle 安装到使用全教程
Kafka Eagle安装详情及问题解答
登录页面查看监控数据:http://192.168.202.102:8048/ke
6、Kafka面试
7、其他
项目经验之Kafka压力测试
# Kafka Producer压力测试
[atguigu@hadoop102 ~]$ kafka-producer-perf-test.sh --topic test --record-size 100 --num-records 100000 --throughput -1 --producer-props bootstrap.servers=hadoop102:9092,hadoop103:9092,hadoop104:9092
100000 records sent, 69348.127601 records/sec (6.61 MB/sec), 480.52 ms avg latency, 692.00 ms max latency, 501 ms 50th, 672 ms 95th, 688 ms 99th, 692 ms 99.9th.
# Kafka Consumer压力测试
[atguigu@hadoop102 ~]$ kafka-consumer-perf-test.sh --broker-list hadoop102:9092,hadoop103:9092,hadoop104:9092 --topic test --fetch-size 10000 --messages 10000000 --threads 1
start.time, end.time, data.consumed.in.MB, MB.sec, data.consumed.in.nMsg, nMsg.sec, rebalance.time.ms, fetch.time.ms, fetch.MB.sec, fetch.nMsg.sec
WARNING: Exiting before consuming the expected number of messages: timeout (10000 ms) exceeded. You can use the --timeout option to increase the timeout.
2022-04-26 20:11:14:940, 2022-04-26 20:11:32:833, 28.6102, 1.5990, 300000, 16766.3332, 1650975075324, -1650975057431, -0.0000, -0.0002















 559
559











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









