







1、Spark yarn模式运行机制
2、大数据开发:Spark通讯架构解析
3、RPC是什么,看完你就知道了
4、Spark 三种部署模式:YARN,Mesos,Standalone 介绍
5、深入理解Spark任务调度
6、图文详解两种算法:深度优先遍历(DFS)和广度优先遍历(BFS)
7、Spark Scheduler调度
8、Spark任务调度-Stage的划分与提交
9、Spark内核解析之五:Spark Shuffle解析
关于shuffle map的数量: 假设Spark任务从HDFS中读取数据,那么初始RDD分区个数由该文件的split个数决定,也就是一个split对应生成的RDD的一个partition。
关于shuffle reduce的数量: 一些算子可以自己传入一个分区器,分区器中定义了相关分区数的操作,默认都是HashPartitoner,并且数量默认是 spark.default.parallelism (默认200),默认情况下这个参数会决定reduce端任务的并行度,如果没有配置这个参数,则会以map端的partitions数作为reduce的分区数,可以参考如下代码。
// 获取spark.default.parallelism参数配置的值
if (rdd.context.conf.contains("spark.default.parallelism")) {
//这里直接就是用的此参数配置的值作为reduce分区数
new HashPartitioner(rdd.context.defaultParallelism)
} else {
//这里直接就用Map端的分区数了 就是map reduce 的分区一致
new HashPartitioner(rdds.map(_.partitions.length).max)
}
10、LRU(最近最少使用)和LFU(最近最不常用)算法的区别
LRU是最近最少使用页面置换算法(Least Recently Used),也就是首先淘汰最长时间未被使用的页面!
LFU是最近最不常用页面置换算法(Least Frequently Used),也就是淘汰一定时期内被访问次数最少的页!
11、Spark内存管理机制
堆内内存 = 存储(Storage)内存 【基本可控】+ 执行(Execution)内存 【基本可控】+ 其他内存(用户定义的对象+spark内部对象)【JVM负责分配和回收,不太可控】
Spark中非序列化的对象占用的内存是通过周期性地采样近似估算而得,导致某一时刻的实际内存占用有可能远远超出预期。此外,在被 Spark 标记为释放的对象实例,很有可能在实际上并没有被 JVM 回收,导致实际可用的内存小于 Spark 记录的可用内存。所以 Spark 并不能准确记录实际可用的堆内内存,从而也就无法完全避免内存溢出(OOM, Out of Memory)的异常。
堆外内存 = 储内存【精确地申请和释放】 + 执行内存【精确地申请和释放】
# 启用堆外内存参数
spark.memory.offHeap.enabled
# 设定堆外空间的大小参数
spark.memory.offHeap.size
静态内存管理(Static Memory Manager)图
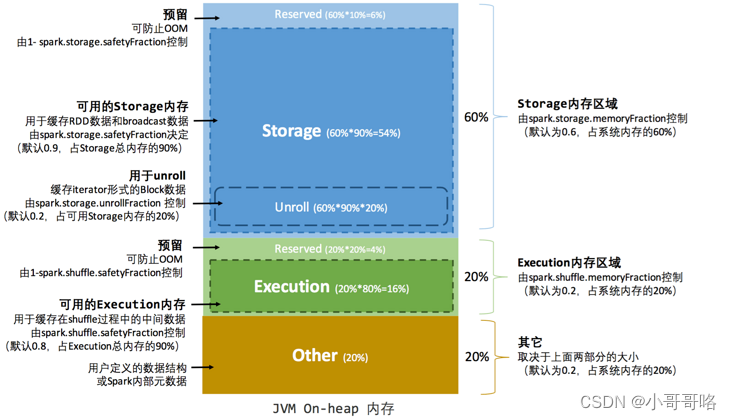
可用的存储内存 = systemMaxMemory * spark.storage.memoryFraction * spark.storage.safetyFraction
可用的执行内存 = systemMaxMemory * spark.shuffle.memoryFraction * spark.shuffle.safetyFraction
PS:堆内内存,在逻辑上预留出 1-safetyFraction 这么一块保险区域,降低因实际内存超出当前预设范围而导致 OOM 的风险(上文提到,对于非序列化对象的内存采样估算会产生误差)。堆外的空间分配较为简单,只有存储内存和执行内存,由于堆外内存占用的空间可以被精确计算,所以无需再设定保险区域。
MemoryManager 的具体实现上,Spark 1.6 之后默认为统一管理(Unified Memory Manager)方式,1.6 之前采用的静态管理(Static Memory Manager)方式仍被保留,可通过配置 spark.memory.useLegacyMode 参数启用。两种方式的区别在于对空间分配的方式。
静态内存管理机制实现起来较为简单,但如果用户不熟悉 Spark 的存储机制,或没有根据具体的数据规模和计算任务或做相应的配置,很容易造成"一半海水,一半火焰"的局面,即存储内存和执行内存中的一方剩余大量的空间,而另一方却早早被占满,不得不淘汰或移出旧的内容以存储新的内容。由于新的内存管理机制的出现,这种方式目前已经很少有开发者使用,出于兼容旧版本的应用程序的目的,Spark 仍然保留了它的实现。
统一内存管理(Unified Memory Manager)图
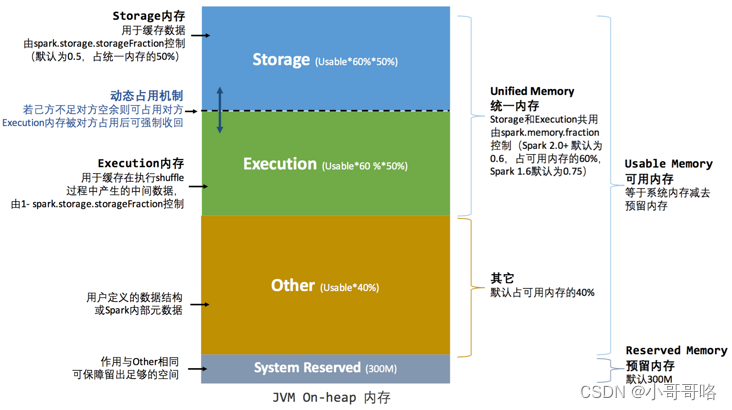
Spark 1.6 之后引入的统一内存管理机制,与静态内存管理的区别在于存储内存和执行内存共享同一块空间,可以动态占用对方的空闲区域。堆外内存除了没有 other 空间,堆外内存与堆内内存的划分方式相同。
其中最重要的优化在于动态占用机制,其规则如下:
① 设定基本的存储内存和执行内存区域(spark.storage.storageFraction 参数),该设定确定了双方各自拥有的空间的范围;
② 双方的空间都不足时,则存储到硬盘;若己方空间不足而对方空余时,可借用对方的空间;(存储空间不足是指不足以放下一个完整的 Block);
③ 执行内存的空间被对方占用后,可让对方将占用的部分转存到硬盘,然后"归还"借用的空间;
④ 存储内存的空间被对方占用后,无法让对方"归还",因为需要考虑 Shuffle 过程中的很多因素,实现起来较为复杂;
存储内存管理
RDD 的持久化由 Spark 的 Storage 模块负责,实现了 RDD 与物理存储的解耦合。Storage 模块负责管理 Spark 在计算过程中产生的数据,将那些在内存或磁盘、在本地或远程存取数据的功能封装了起来。Storage 模块在逻辑上以 Block 为基本存储单位,RDD 的每个 Partition 经过处理后唯一对应一个 Block(BlockId 的格式为 rdd_RDD-ID_PARTITION-ID )。
通过对数据结构的分析,可以看出存储级别从三个维度定义了 RDD 的 Partition(同时也就是 Block)的存储方式:
① 存储位置:磁盘/堆内内存/堆外内存。如 MEMORY_AND_DISK 是同时在磁盘和堆内内存上存储,实现了冗余备份。OFF_HEAP 则是只在堆外内存存储,目前选择堆外内存时不能同时存储到其他位置。
② 存储形式:Block 缓存到存储内存后,是否为非序列化的形式。如 MEMORY_ONLY 是非序列化方式存储,OFF_HEAP 是序列化方式存储。
③ 副本数量:大于 1 时需要远程冗余备份到其他节点。如 DISK_ONLY_2 需要远程备份 1 个副本。
RDD 在缓存到存储内存之前,Partition 中的数据一般以迭代器(Iterator)的数据结构来访问,这是 Scala 语言中一种遍历数据集合的方法。通过 Iterator 可以获取分区中每一条序列化或者非序列化的数据项(Record),这些 Record 的对象实例在逻辑上占用了 JVM 堆内内存的 other 部分的空间,同一 Partition 的不同 Record 的空间并不连续。
RDD 在缓存到存储内存之后,Partition 被转换成 Block,Record 在堆内或堆外存储内存中占用一块连续的空间。将Partition由不连续的存储空间转换为连续存储空间的过程,Spark称之为"展开"(Unroll)。因为不能保证存储空间可以一次容纳 Iterator 中的所有数据,当前的计算任务在 Unroll 时要向 MemoryManager 申请足够的 Unroll 空间来临时占位,空间不足则 Unroll 失败,空间足够时可以继续进行。
对于序列化的 Partition,其所需的 Unroll 空间可以直接累加计算,一次申请。而非序列化的 Partition 则要在遍历 Record 的过程中依次申请,即每读取一条 Record,采样估算其所需的 Unroll 空间并进行申请,空间不足时可以中断,释放已占用的 Unroll 空间。如果最终 Unroll 成功,当前 Partition 所占用的 Unroll 空间被转换为正常的缓存 RDD 的存储空间,如下图所示:
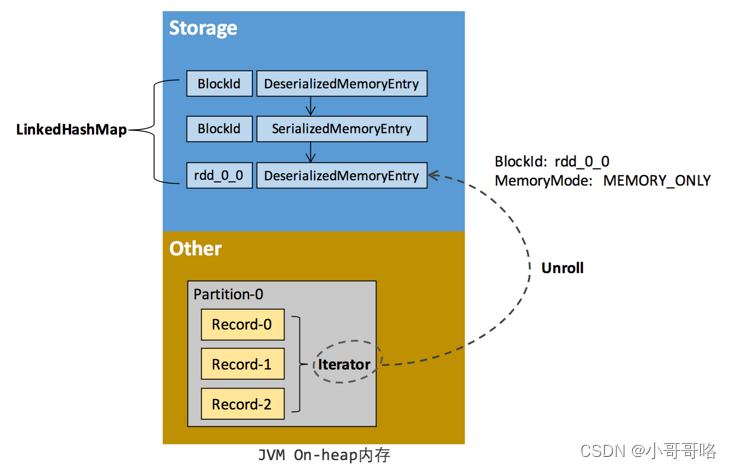
统一内存管理(Unified Memory Manager)图和静态内存管理(Static Memory Manager)图 可以看到,在静态内存管理时,Spark 在存储内存中专门划分了一块 Unroll 空间,其大小是固定的,统一内存管理时则没有对 Unroll 空间进行特别区分,当存储空间不足时会根据动态占用机制进行处理。
存储内存的淘汰和落盘。由于同一个 Executor 的所有的计算任务共享有限的存储内存空间,当有新的 Block 需要缓存但是剩余空间不足且无法动态占用时,就要对 LinkedHashMap 中的旧 Block 进行淘汰(Eviction),而被淘汰的 Block 如果其存储级别中同时包含存储到磁盘的要求,则要对其进行落盘(Drop),否则直接删除该 Block。存储内存的淘汰规则为:
① 被淘汰的旧 Block 要与新 Block 的 MemoryMode 相同,即同属于堆外或堆内内存
② 新旧 Block 不能属于同一个 RDD,避免循环淘汰
③ 旧 Block 所属 RDD 不能处于被读状态,避免引发一致性问题
④ 遍历 LinkedHashMap 中 Block,按照最近最少使用(LRU)的顺序淘汰,直到满足新 Block 所需的空间。(其中 LRU 是 LinkedHashMap 的特性)
落盘的流程则比较简单,如果其存储级别符合_useDisk 为 true 的条件,再根据其_deserialized 判断是否是非序列化的形式,若是则对其进行序列化,最后将数据存储到磁盘,在 Storage 模块中更新其信息。
执行内存管理
Executor 内运行的任务同样共享执行内存,Spark 用一个 HashMap 结构保存了任务到内存耗费的映射。每个任务可占用的执行内存大小的范围为 1/2N ~ 1/N,其中 N 为当前 Executor 内正在运行的任务的个数。每个任务在启动之时,要向 MemoryManager 请求申请最少为 1/2N 的执行内存,如果不能被满足要求则该任务被阻塞,直到有其他任务释放了足够的执行内存,该任务才可以被唤醒。
执行内存主要用来存储任务在执行 Shuffle 时占用的内存,Shuffle 是按照一定规则对 RDD 数据重新分区的过程,我们来看 Shuffle 的 Write 和 Read 两阶段对执行内存的使用:
Shuffle Write:
① 若在 map 端选择普通的排序方式,会采用 ExternalSorter 进行外排,在内存中存储数据时主要占用堆内执行空间。
② 若在 map 端选择 Tungsten 的排序方式,则采用 ShuffleExternalSorter 直接对以序列化形式存储的数据排序,在内存中存储数据时可以占用堆外或堆内执行空间,取决于用户是否开启了堆外内存以及堆外执行内存是否足够。
Shuffle Read:
在对 reduce 端的数据进行聚合时,要将数据交给 Aggregator 处理,在内存中存储数据时占用堆内执行空间。如果需要进行最终结果排序,则要将再次将数据交给 ExternalSorter 处理,占用堆内执行空间。在 ExternalSorter 和 Aggregator 中,Spark 会使用一种叫 AppendOnlyMap 的哈希表在堆内执行内存中存储数据,但在 Shuffle 过程中所有数据并不能都保存到该哈希表中,当这个哈希表占用的内存会进行周期性地采样估算,当其大到一定程度,无法再从 MemoryManager 申请到新的执行内存时,Spark 就会将其全部内容存储到磁盘文件中,这个过程被称为溢存(Spill),溢存到磁盘的文件最后会被归并(Merge)。
总结
Spark 的存储内存和执行内存有着截然不同的管理方式:对于存储内存来说,Spark 用一个 LinkedHashMap 来集中管理所有的 Block,Block 由需要缓存的 RDD 的 Partition 转化而成;而对于执行内存,Spark 用 AppendOnlyMap 来存储 Shuffle 过程中的数据,在 Tungsten 排序中甚至抽象成为页式内存管理,开辟了全新的 JVM 内存管理机制。
PS:Tungsten 的排序简介
Tungsten 采用的页式内存管理机制建立在 MemoryManager 之上,即 Tungsten 对执行内存的使用进行了一步的抽象,这样在 Shuffle 过程中无需关心数据具体存储在堆内还是堆外。每个内存页用一个 MemoryBlock 来定义,并用 Object obj 和 long offset 这两个变量统一标识一个内存页在系统内存中的地址。堆内的 MemoryBlock 是以 long 型数组的形式分配的内存,其 obj 的值为是这个数组的对象引用,offset 是 long 型数组的在 JVM 中的初始偏移地址,两者配合使用可以定位这个数组在堆内的绝对地址;堆外的 MemoryBlock 是直接申请到的内存块,其 obj 为 null,offset 是这个内存块在系统内存中的 64 位绝对地址。Spark 用 MemoryBlock 巧妙地将堆内和堆外内存页统一抽象封装,并用页表(pageTable)管理每个 Task 申请到的内存页。
Tungsten 页式管理下的所有内存用 64 位的逻辑地址表示,由页号和页内偏移量组成:
① 页号:占 13 位,唯一标识一个内存页,Spark 在申请内存页之前要先申请空闲页号。
② 页内偏移量:占 51 位,是在使用内存页存储数据时,数据在页内的偏移地址。
有了统一的寻址方式,Spark 可以用 64 位逻辑地址的指针定位到堆内或堆外的内存,整个 Shuffle Write 排序的过程只需要对指针进行排序,并且无需反序列化,整个过程非常高效,对于内存访问效率和 CPU 使用效率带来了明显的提升














 297
297











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









