







1、Apache Flink
选择Spark:数据批处理,延迟性在数百毫秒到数秒之间;(Executor故障容错性高)
选择Flink:数据流处理,延迟性在微秒到毫秒级;(Executor故障容错性低)
2、Flink的IDEA编程
Github代码:https://github.com/jieky-1/Flink_Java
重点概念:内部类、有状态、富函数、水位线、CEP、动态表;
API 类型:开箱即用 API、自定义实现 API;(数据源、转化算子、输出 Sink)
Apache Flink Code Style and Quality Guide — Scala
Flink 中的 API
Apache Flink——运行时架构
① We use Scala for Scala APIs or pure Scala Libraries.
② We do not use Scala in the core APIs and runtime components. We aim to remove existing Scala use (code and dependencies) from those components.
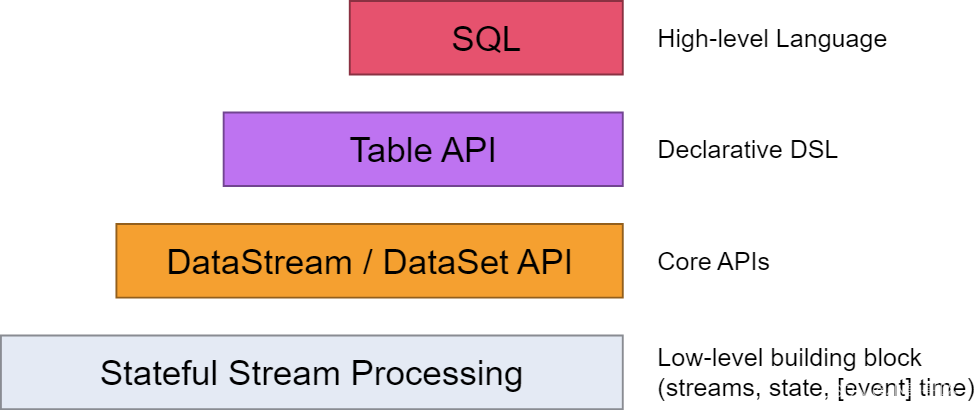
Flink APL抽象
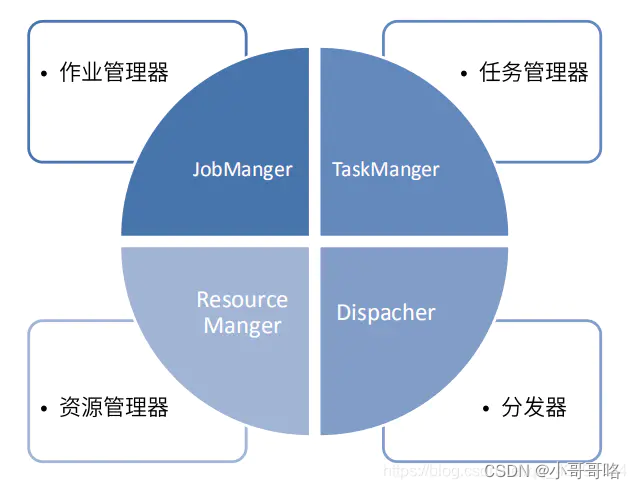
Flink运行时组件
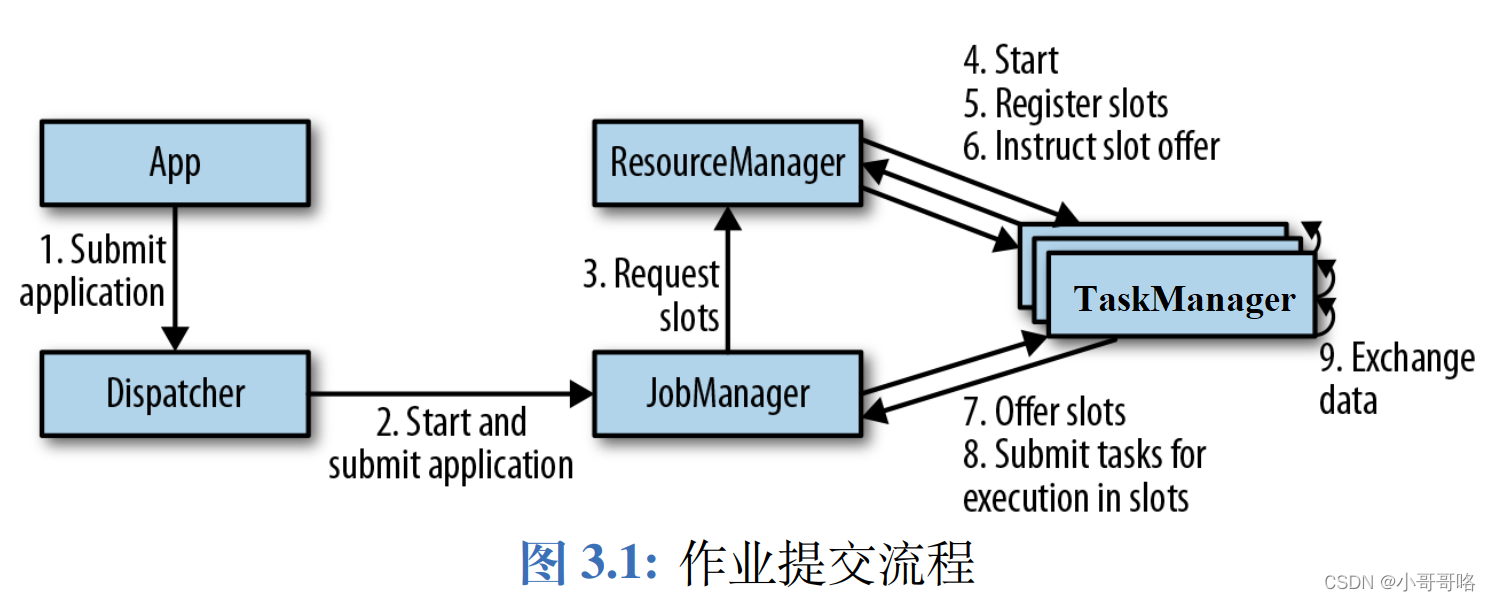
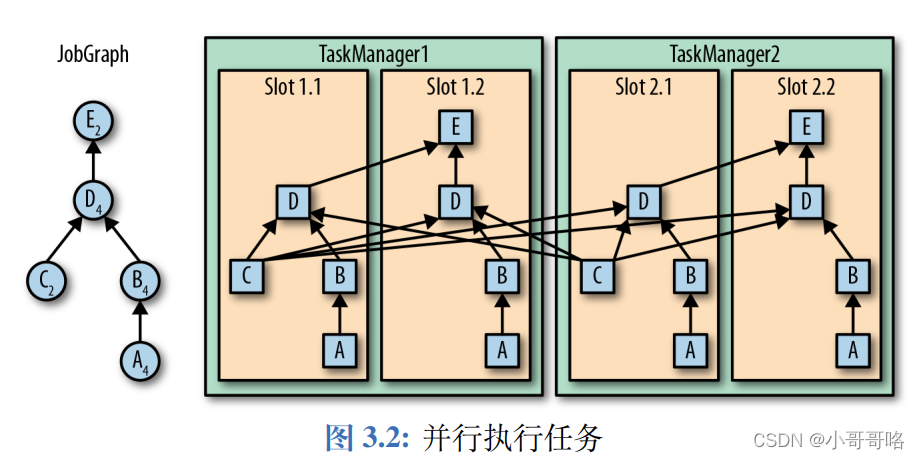
并行度设置:算子级别 > env级别 > Client级别 > 系统默认级别
3、流处理基础
如何形象的描述反应式编程中的背压(Backpressure)机制?
总结:Backpressure 指的是在 Buffer 有上限的系统中,Buffer 溢出的现象;它的应对措施只有一个:丢弃新事件。Backpressure 只是一种现象,而不是一种机制。
如果上游生产速度可能会快到把系统搞崩溃,而事件也不可丢弃,怎么办?这个时候,你就要修改程序的设计了:修改代码设计来规避风险,或者修改软件设计、通过让步的方式来从根源上避免问题发生。总之,这已经不是 Buffer 或者 Backpressure 能解决的问题了。
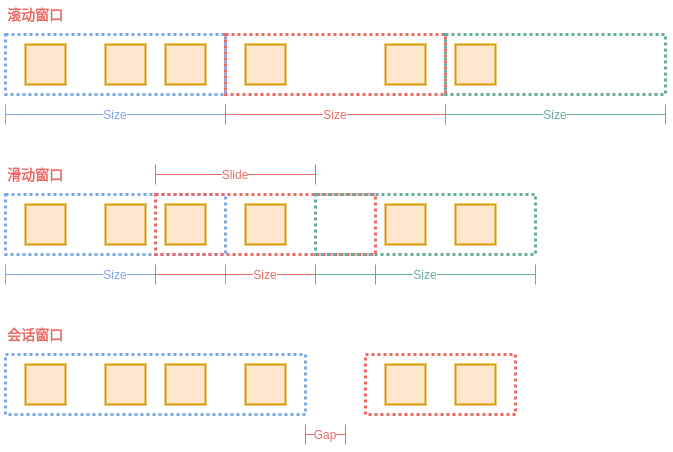
在我们基于Flink类型系统支持的数据类型进行编程时,Flink在运行时会推断出数据类型的信息,程序员在基于Flink编程时,几乎是不需要关心类型和序列化的。Flink使用TypeInformation来描述所有Flink支持的数据类型,每一种Flink支持的数据类型都对应的是TypeInformation的子类。除了对类型地描述之外,TypeInformation还提供了序列化的支撑。Flink的中TypeInformation创建的序列化器会以稠密的方式来将对象写入到内存中。
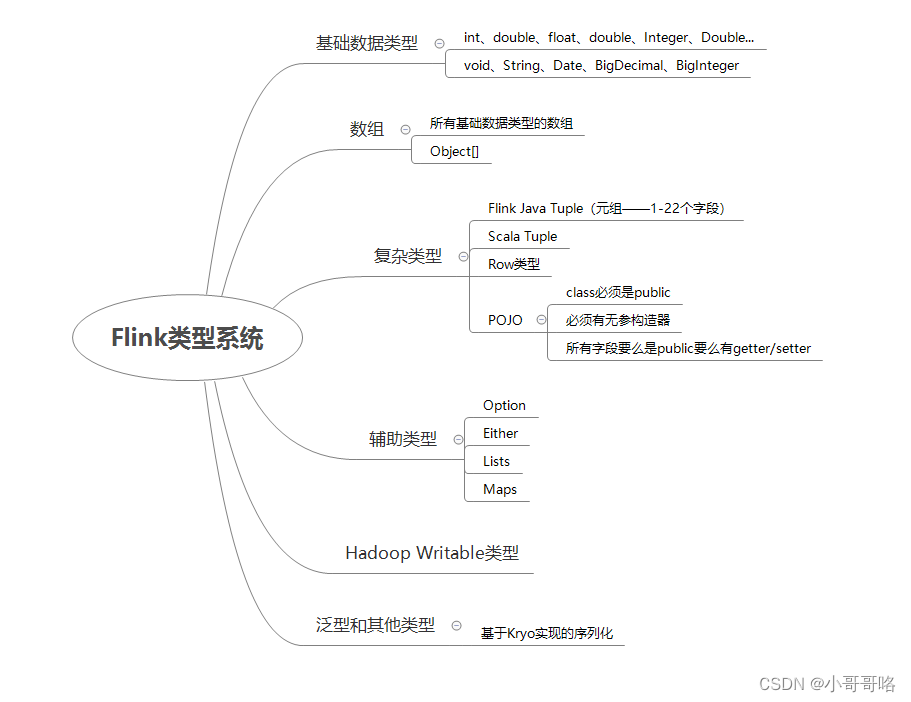
有一个概念需要大家记住:泛型类型可以用于匿名类。javac编译器遇到匿名类时,会在字节码中创建数据结构(注意该结构只在运行时可用),这个数据结构中就包含了实际的泛型参数信息。所以,使用匿名类实例化对象是不会进行类型擦除的。
举例:
SingleOutputStreamOperator<String> eachTypeDS = phoneTypeDS.flatMap((val, out) -> {
val.stream().forEach(t -> out.collect(t));
});
Exception in thread “main” org.apache.flink.api.common.functions.InvalidTypesException: The return type of function ‘main(FlinkTypeDemo.java:37)’ could not be determined automatically, due to type erasure. You can give type information hints by using the returns(…) method on the result of the transformation call, or by letting your function implement the ‘ResultTypeQueryable’ interface.
因为Java的类型擦除,所以Flink根本无法推断出来该flatMap要输出的类型是什么。Flink需要我们指定该类型的TypeInformation,给它一个提示(TypeHint)。下面三种方案都可:
phoneTypeDS.flatMap((List<String> val, Collector<String> out) -> {
val.stream().forEach(t -> out.collect(t));
})
.returns(TypeInformation.of(String.class))
.print();
phoneTypeDS.flatMap((List<String> val, Collector<String> out) -> {
val.stream().forEach(t -> out.collect(t));
})
.returns(new TypeHint<String>() {})
.print();
phoneTypeDS.flatMap(new FlatMapFunction<(List<String> , String>() {
@Override
public void flatMap(List<String> value, Collector<String> out) throws Exception {
val.stream().forEach(t -> out.collect(t));
}
})
.print();
// 没有使用匿名内部类
ArrayList<String> strings1 = new ArrayList<String>();
// 使用匿名内部类,没有重写父类任何方法
ArrayList<String> strings2 = new ArrayList<String>() {};
① 所需类型不同
匿名内部类:可以是接口,也可以是抽象类,还可以是具体类。
Lambda表达式:只能是接口
② 使用限制不同
如果接口中有且仅有一个抽象方法,可以使用Lambda表达式,也可以使用匿名内部类。 如果接口中多于一个抽象方法,那么只能使用匿名内部类,而不能使用Lambda表达式。
③ 实现原理不同
匿名内部类:编译之后会产生一个单独的.class字节码文件
Lambda表达式:编译之后不会产生一个单独的.class字节码文件。对应的字节码会在运行的时候动态生成。
一些必要的概念
真实世界的系统,网络和通信渠道远非完美,流数据经常被推迟或无序 (乱序) 到达。理解如何在这种条件下提供准确和确定的结果是至关重要的。更重要的是,流处理程序可以按原样处理事件制作的也应该能够处理相同的历史事件方式,从而实现离线分析甚至时间旅行分析。当然,前提是我们的系统可以保存状态,因为可能有故障发生。在流处理应用可能发生故障的语境下,深入探讨时间和状态的概念。
时间语义:处理时间(快)和事件时间(准)
①处理时间是处理流的应用程序的机器的本地时钟的时间(墙上时钟)。处理时间的窗口包含了一个时间段内来到机器的所有事件。这个时间段指的是机器的墙上时钟。
②事件时间是流中的事件实际发生的时间。事件时间基于流中的事件所包含的时间戳。通常情况下,在事件进入流处理程序前,事件数据就已经包含了时间戳。
怎样去决定何时触发事件时间窗口的计算?也就是说,在我们可以确定一个时间点之前的所有事件都已经到达之前,我们需要等待多久?我们如何知道事件是迟到的?在分布式系统无法准确预测行为的现实条件下,以及外部组件所引发的事件的延迟,以上问题并没有准确的答案。
运算符一旦接收到水位线(默认情况下Flink使用的是处理时间,显示调用assignTimestampsAndWatermarks才会使用事件时间,使用事件时间后才有水位线的概念),运算符会认为一段时间内发生的所有事件都已经观察到,可以触发针对这段时间内所有事件的计算了。水位线提供了一种结果可信度和延时之间的妥协。激进的水位线设置可以保证低延迟,但结果的准确性不够。在这种情况下,迟到的事件有可能晚于水位线到达,我们需
要编写一些代码来处理迟到事件。另一方面,如果水位线设置的过于宽松,计算的结果准确性会很高,但可能会增加流处理程序不必要的延时。
在很多真实世界的场景里面,系统无法获得足够的知识来完美的确定水位线。所以仅仅依靠水位线可能并不是一个很好的主意。流处理系统还需要提供一些机制来处理迟到的元素(在水位线之后到达的事件)。根据应用场景,我们可能需要把迟到事件丢弃掉,或者写到日志里,或者使用迟到事件来更新之前已经计算好的结果。
如果任务再接收到的数据违反了 watermark 的这一属性,也就是时间戳小于以前接收到的水位线时,它所属的那部分计算可能已经完成了。这种数据被称为延迟数据(late records)。 Flink 提供了处理延迟数据的不同方式。
4、Flink 状态管理
相对于其他流计算框架,Flink 一个比较重要的特性就是其支持有状态计算。即你可以将中间的计算结果进行保存,并提供给后续的计算使用。具体而言,Flink 又将状态 (State) 分为 Keyed State 与 Operator State。
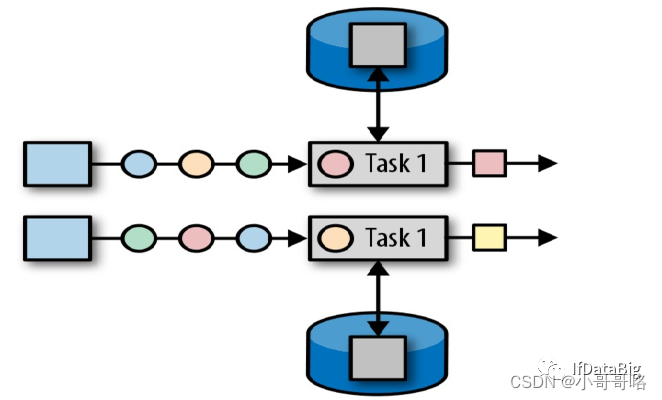
算子状态 (Operator State):顾名思义,状态是和算子进行绑定的,一个算子的状态不能被其他算子所访问到。官方文档上对 Operator State 的解释是:each operator state is bound to one parallel operator instance,所以更为确切的说一个算子状态是与一个并发的算子实例所绑定的,即假设算子的并行度是 2,那么其应有两个对应的算子状态。算子状态目前支持的存储类型只有以下三种:
① ListState:存储列表类型的状态。
② UnionListState:存储列表类型的状态,与 ListState 的区别在于:如果并行度发生变化,ListState 会将该算子的所有并发的状态实例进行汇总,然后均分给新的 Task;而 UnionListState 只是将所有并发的状态实例汇总起来,具体的划分行为则由用户进行定义。
③ BroadcastState:用于广播的算子状态。
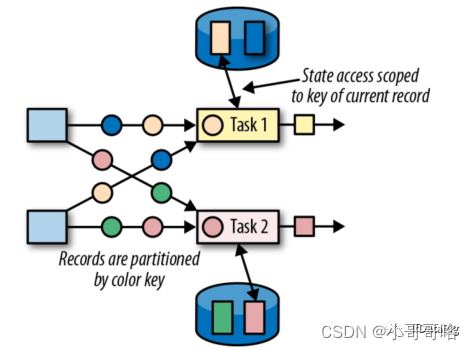
键控状态 (Keyed State) :是一种特殊的算子状态,即状态是根据 key 值进行区分的,Flink 会为每类键值维护一个状态实例。如下图所示,每个颜色代表不同 key 值,对应四个不同的状态实例。需要注意的是键控状态只能在 KeyedStream上进行使用,我们可以通过 stream.keyBy(…)来得到 KeyedStream。Flink 提供了以下数据格式来管理和存储键控状态 (Keyed State):
① ValueState:存储单值类型的状态。可以使用 update(T) 进行更新,并通过 T value() 进行检索。
② ListState:存储列表类型的状态。可以使用 add(T) 或 addAll(List) 添加元素;并通过 get() 获得整个列表。
③ ReducingState:用于存储经过 ReduceFunction 计算后的结果,使用 add(T) 增加元素。
④ AggregatingState:用于存储经过 AggregatingState 计算后的结果,使用 add(IN) 添加元素。
⑤ FoldingState:已被标识为废弃,会在未来版本中移除,官方推荐使用 AggregatingState 代替。
⑥ MapState:维护 Map 类型的状态。
PS:以上任何类型的 keyed state 都支持配置有效期 (TTL)
5、Flink 状态一致性、端到端的精确一次(ecactly-once)保证
检查点机制(Flink 流处理器内部的精确一次(ecactly-once)保证)
5.1 CheckPoints
为了使 Flink 的状态具有良好的容错性,Flink 提供了检查点机制 (CheckPoints) 。通过检查点机制,Flink 定期在数据流上生成 checkpoint barrier ,当某个算子收到 barrier 时,即会基于当前状态生成一份快照,然后再将该 barrier 传递到下游算子,下游算子接收到该 barrier 后,也基于当前状态生成一份快照,依次传递直至到最后的 Sink 算子上。当出现异常后,Flink 就可以根据最近的一次的快照数据将所有算子恢复到先前的状态。
5.2 开启检查点
默认情况下,检查点机制是关闭的,需要在程序中进行开启:
// 开启检查点机制,并指定状态检查点之间的时间间隔
env.enableCheckpointing(1000);
// 其他可选配置如下:
// 设置语义
env.getCheckpointConfig().setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE);
// 设置两个检查点之间的最小时间间隔
env.getCheckpointConfig().setMinPauseBetweenCheckpoints(500);
// 设置执行Checkpoint操作时的超时时间
env.getCheckpointConfig().setCheckpointTimeout(60000);
// 设置最大并发执行的检查点的数量
env.getCheckpointConfig().setMaxConcurrentCheckpoints(1);
// 将检查点持久化到外部存储
env.getCheckpointConfig().enableExternalizedCheckpoints(
ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION);
// 如果有更近的保存点时,是否将作业回退到该检查点
env.getCheckpointConfig().setPreferCheckpointForRecovery(true);
5.3 保存点机制
保存点机制 (Savepoints) 是检查点机制的一种特殊的实现,它允许你通过手工的方式来触发 Checkpoint,并将结果持久化存储到指定路径中,主要用于避免 Flink 集群在重启或升级时导致状态丢失。示例如下:
# 触发指定id的作业的Savepoint,并将结果存储到指定目录下
bin/flink savepoint :jobId [:targetDirectory]
端到端的精确一次(ecactly-once)保证
端到端(end-to-end)状态一致性取决于它所有组件中最薄弱的一环,也就是典型的木桶理论了。具体可以划分如下:
① 内部保证:依赖 checkpoint
② source 端:需要外部源可重设数据的读取位置(kafka可以实现)
③ sink 端: 需要保证从故障恢复时,数据不会重复写入外部系统
sink 端有幂等(Idempotent)写入和事务性(Transactional)写入,两种具体的实现精确一次的方式:
① 幂等写入:所谓幂等操作,是说一个操作,可以重复执行很多次,但只导致一次结果更改,也就是说,后面再重复执行就不起作用了。
② 事务写入:需要构建事务来写入外部系统,构建的事务对应着 checkpoint,等到 checkpoint 真正完成的时候,才把所有对应的结果写入 sink 系统中。对于事务性写入,具体又有两种实现方式:预写日志(WAL,任意外部 sink 系统,收到 checkpoint 完成的通知的时候,一次性写入 sink 系统)和两阶段提交(2PC,外部 sink 系统需要支持事务,收到 checkpoint 完成的通知时,它才正式提交事务,实现 “预提交” 的真正写入)。
PS:Flink 由 JobManager 协调各个 TaskManager 进行 checkpoint 存储,checkpoint 保存在 StateBackend 中,默认 StateBackend 是内存级的,也可以改为文件级的进行持久化保存。当 checkpoint 启动时,JobManager 会将检查点分界线(barrier)注入数据流;barrier 会在算子间传递下去。每个内部的 transform 任务遇到 barrier 时,都会把状态存到 checkpoint 里。当所有算子任务的快照完成,也就是这次的 checkpoint 完成时,JobManager 会向所有任务发通知,确认这次 checkpoint 完成。
6、StateBackend 状态后端
flink的Checkpoint开启与配置
StateBackend 状态后端
Flink学习笔记(5) – Flink 状态(State)管理与恢复
Flink之state processor api实践
Flink 中的每个方法或算子都能够是有状态的。 状态化的方法在处理单个元素/事件 的时候存储数据,让状态成为使各个类型的算子更加精细的重要部分。 为了让状态容错,Flink 需要为状态添加 checkpoint(检查点)。Checkpoint 使得 Flink 能够恢复状态和在流中的位置,从而向应用提供和无故障执行时一样的语义。
Flink 的 checkpoint 机制会和持久化存储进行交互,读写流与状态。一般需要:
① 一个能够回放一段时间内数据的持久化数据源,例如持久化消息队列(例如 Apache Kafka、RabbitMQ、 Amazon Kinesis、 Google PubSub 等)或文件系统(例如 HDFS、 S3、 GFS、 NFS、 Ceph 等)。
② 存放状态的持久化存储,通常为分布式文件系统(比如 HDFS、 S3、 GFS、 NFS、 Ceph 等)。
默认情况下 checkpoint 是禁用的,通过调用 StreamExecutionEnvironment 的 enableCheckpointing(n) 来启用 checkpoint,里面的 n 是进行 checkpoint 的间隔,单位毫秒。在启动 CheckPoint 机制时,状态会随着 CheckPoint 而持久化,以防止数据丢失、保障恢复时的一致性。 状态内部的存储格式、状态在 CheckPoint 时如何持久化以及持久化在哪里均取决于选择的 State Backend。Flink 内置了以下这些开箱即用的 state backends :MemoryStateBackend、FsStateBackend、RocksDBStateBackend,如果不设置,默认使用 MemoryStateBackend。
MemoryStateBackend
内存级的状态后端,state数据保存在java堆内存中,执行checkpoint的时候,会把state的快照数据保存到jobmanager的内存中,基于内存的state backend在生产环境下不建议使用。
特点:快速、低延迟,但不稳定
FsStateBackend
执行checkpoint的时候,会把state的快照数据保存到配置的文件系统中;而对于本地状态,跟 MemoryStateBackend 一样,也会存在 TaskManager 的 JVM 堆上
特点:同时拥有内存级的本地访问速度,和更好的容错保证
RocksDBStateBackend
RocksDB跟上面的都略有不同,它会在本地文件系统中维护状态,state会直接写入本地rocksdb中。同时它需要配置一个远端的filesystem uri(一般是HDFS),在做checkpoint的时候,会把本地的数据直接复制到filesystem中。fail over的时候从filesystem中恢复到本地,RocksDB克服了state受内存限制的缺点,同时又能够持久化到远端文件系统中,比较适合在生产中使用。
前不久,Flink社区发布了FLink 1.9版本,在其中包含了一个很重要的新特性,即state processor api,这个框架支持对checkpoint和savepoint进行操作,包括读取、变更、写入等等。
7、使用Flink算子编程
FlinkCEP是在Flink之上实现的复杂事件处理(CEP)库。它允许您在无穷无尽的事件流中检测事件模式,使您有机会掌握数据中哪些是重要的。
【深入浅出flink】第7篇:从原理剖析flink中所有的重分区方式keyBy、broadcast、rebalance、rescale、shuffle、global、partitionCustom
flink任务在执行过程中,一个流(stream)包含一个或多个分区(Stream partition)。TaskManager中的一个slot的subtask就是一个stream partition(流分区),一个Job的流(stream)分布在多个不同的Slot上执行。每一个算子可以包含一个或多个子任务(subtask),这些subtask执行在不同的分区中,本质是在不同的线程、不同的物理机或不同的容器中彼此互不依赖地执行。
Flink中的重分区算子定义上下游subtask之间数据传递的方式。SubTask之间进行数据传递模式有两种,一种是one-to-one(forwarding)模式,另一种是redistributing的模式:
① One-to-one:数据不需要重新分布,上游SubTask生产的数据与下游SubTask受到的数据完全一致,数据不需要重分区,也就是数据不需要经过IO,比如上图中source->map的数据传递形式就是One-to-One方式。常见的map、fliter、flatMap等算子的SubTask的数据传递都是one-to-one的对应关系。类似于spark中的窄依赖。
② Redistributing:数据需要通过shuffle过程重新分区,需要经过IO,比如上图中的map->keyBy。创建的keyBy、broadcast、rebalance、shuffle等算子的SubTask的数据传递都是Redistributing方式,但它们具体数据传递方式是不同的。类似于spark中的宽依赖。
“富函数” 是 DataStream API 提供的一个函数类的接口,所有Flink 函数类都有其Rich 版本。它与常规函数的不同在于,可以获取运行环境的上下文,并拥有一些生命周期方法,所以可以实现更复杂的功能。简单的可以概括如下:
① 在函数处理数据之前,需要做一些初始化的工作;
② 或者需要在处理数据时可以获得函数执行上下文的一些信息;
③ 以及在处理完数据时做一些清理工作。
Rich Function 有一个生命周期的概念,典型的生命周期方法有:
① open()方法是rich function 的初始化方法,当一个算子例如map 或者filter被调用之前open()会被调用;
② close()方法是生命周期中的最后一个调用的方法,做一些清理工作;
③ getRuntimeContext()方法提供了函数的RuntimeContext 的一些信息,例如函数执行的并行度,任务的名字,以及state 状态;
知识扩展
Spark Streaming保证Exactly-Once语义
Kafka auto.offset.reset值详解
从Lambda架构到Kappa架构再到?浅谈未来数仓架构设计~
详解数仓中的数据分层:ODS、DWD、DWM、DWS、ADS














 777
777











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









