






之前写一个抓取某图片网站的图片的Python脚本,觉得下载了太慢,就考虑使用多线程实现,下面记录下实现思路。
使用的是Python包:requests+asyncio+Beautifulsoop。没有使用scrapy,虽然它确实很强大,但是感觉还是有太多的局限,requests虽然不能像scrapy一样能够自动解析,但是和Beatifulsoop一起使用,功能还是可以的。
这个任务是这样滴:
-
要抓取的地址下是有多个分页的网页,每一页中有多个图片,点击图片进入后可以解析到下载的网址,但是这个网址是有权限验证的,验证之后在返回的header中给出具体下载地址
-
去下载网址下载文件,但是由于文件比较大,所以需要一段时间
实现的目标:
1.生产者负责解析具体下载的网址,之后加入任务队列,采用asyncio的quene有一个好处是:当quene满了后会等待,有了空缺再继续解析
2.消费者扶着下载文件,由于速度慢,所以需要用到多线程,我使用的是multiprocessing中的多进程
3.生产者解析完网址后发送一个消息告诉消费者,它生产完了,你慢慢来
4.消费者工作完后,告诉Eventloop:我的任务完成了,你可以结束了,但是由于具体任务执行者是在进程中,所以还要等他们完成
大致流程,(不要嘲笑我,非科班出身):
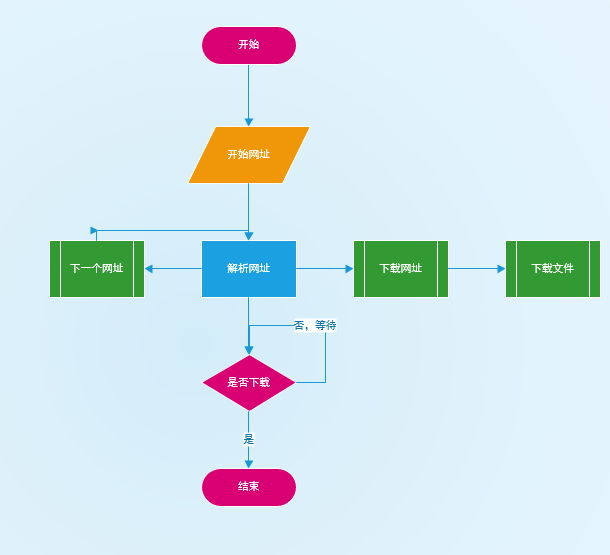
流程图
具体代码(window下运行,其他平台没有试过)
import asyncio
import multiprocessing
import random
import time
import requests
from concurrent.futures import ProcessPoolExecutor
from threading import Event
def worker(item):
file_name = str(int(time.time()*1000))+'-'+str(item)+'.html'
print(file_name)
with open(file_name, 'wb') as f:
res = requests.get('http://www.jianshu.com/p/968be2f00119')
print(res.status_code)
time.sleep(30)
f.write(res.content)
class MySpider(object):
def __init__(self):
self.queue = asyncio.Queue(maxsize=10) # 任务队列
self.pool = ProcessPoolExecutor(max_workers=5) # 进程池
self.event = Event()
@asyncio.coroutine
def producer(self):
# 生产控制者
for i in range(10):
yield from self.producer_001()
self.event.set()
@asyncio.coroutine
def producer_001(self):
# 其中一个生产者
yield from asyncio.sleep(1)
yield from self.producer_002()
@asyncio.coroutine
def producer_002(self):
# 其中一个生产者
yield from asyncio.sleep(1)
yield from self.product_003()
@asyncio.coroutine
def producer_003(self):
# 最后一个生产者,负责把生产的东西加到队列里
item = random.randint(1, 100)
print("put Item", item)
yield from self.queue.put(item)
@asyncio.coroutine
def customer(self, future):
# 消费者
while True:
if self.event.is_set() and self.queue.empty():
break
item = yield from self.queue.get()
self.pool.submit(worker, item)
future.set_result("customer done")
@asyncio.coroutine
def start(self, future):
asyncio.ensure_future(self.producter())
asyncio.ensure_future(self.custom(future))
if __name__ == '__main__':
multiprocessing.freeze_support()
loop = asyncio.get_event_loop()
future = loop.create_future()
loop.create_task(MySpider().start(future))
loop.run_until_complete(future)
print(future.result())
loop.close()
功能说明
- 生产者只关心自己的事情,只管生产网址就行
- worker只负责下载文件,一心只下文件,至于是不是该停工了,队列是不是满了不关心
- 消费者其实充当了scheduler了角色,他只负责拿到网址,分配任务,不关心进程的问题,分配给它任务就可以了,进程池慢不慢不关心
4 消费者任务完成后,告知Eventloop,结束任务
缺陷
- 使用了进程,占用太多资源,可以考虑其他途径
- 功能划分不合理,有重叠
- 在非异步下,进程池满了之后会报错,但是这里却没有报错,而是继续运行,没弄明白
代码解释
其实我也不是太明白,但是代码是我自己写的,我说说自己的理解
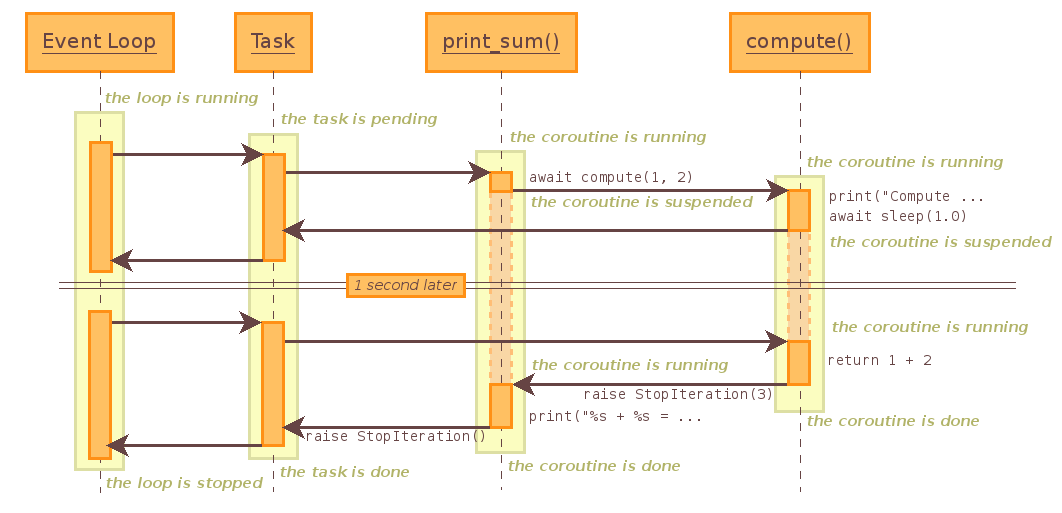
盗窃的Python 官网上的图
看了这张图大概明白个差不多了
- An event loop runs in a thread and executes all callbacks and tasks in the same thread
- While a task is running in the event loop, no other task is running in the same thread
- When the task uses yield from, the task is suspended and the event loop executes the next task.
- To schedule a callback from a different thread, the AbstractEventLoop.call_soon_threadsafe()-- method should be used
- To schedule a coroutine object from a different thread, the run_coroutine_threadsafe() function should be used. It returns a concurrent.futures.
- 要想一个任务被执行,需要用asyncio.ensure_future或者loop.create_task告诉loop,我这里有一个任务,你帮忙安排下
好了,就这么多吧
补充:
建了一个qq群:389954854,主要目的是互帮互助,通过交流促进python技术。很多初学者往往不知道如何下手,还等什么,快快加入进来吧!

或者关注微信公众号:python码码有趣的
















 6936
6936

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









