









先分析应用场景特点,本文不讲如何用cache,讲互联网公司数据库如何使用。
互联网场景:
- 前台业务
- 数据量大
- 并发量大
- 数据库成为瓶颈
军规优化的核心方向:
- 降低数据库CPU计算、降低磁盘IO。
- 读写分离2台以上数据库,降低单台数据库的负担
- 增加数据cache减少数据库访问
- 增加SQL索引
- 编写优质的SQL语句
SQL军规:
- 大对象不要存储数据库里,字段存储小数据量。
- 不要数据库做复杂的CPU计算,非必须的计算在service层进行计算。(服务层容易通过加机器来扩展,数据库层很难不改变架构的情况下水平切分和扩展)
- 禁止使用外键,由service层保证保证数据完整性
- 禁止使用存储过程,视图,触发器,event (对性能影响极大)
- join必须字符集、类型、长度相同,表字符集不同join会发生笛卡尔查询,降低性能如下。需要索引来优化:1、where 条件的字段需要建立索引。2、并且select id,name,sex建立联合索引index(name,sex),也叫覆盖索引。



- 禁止%开头的like 。不能命中索引,导致全表扫描。
- 字段类型与字段赋值的类型必须相同,否则不能命中索引,导致全表扫描:name字段varchar 值是 select id from user where name=1 发生强制类型转换降低性能。
- 禁止在列上进行函数或表达式计算。因为不能命中索引,导致全表扫描。
- 禁止主键字段NULL,NULL会被查询出来。
- select count(*) 需要where 条件,否则全表扫描
- 使用innodb引擎行锁,支持事务(有数据修复机制,数据一致性高的场景),myisam表锁不支持(有一定造成文件损坏,虽然可以实现事务但性能很低)。
- myisam表锁,写入时候锁表
- innodb支持细粒度的行锁,写入时候锁行,锁在索引上不是锁物理记录上,如果不能命中索引情况下也不会使用行锁。
- 垂直拆分表。user表拆成2个,user_base存放基本用户短数据,user_ext表存放用户描述等字段长的信息。
- 索引不是越多越好,根据数据库的具体CPU和内存情况来定。因为索引占用MYSQL的缓存buffer空间,假设1G的缓存空间里面存储索引和数据,索引多造成数据少,数据从磁盘IO获取降低性能。
- 禁止select * ;原因这样用不了覆盖索引提高效率。
- insert into 必须指定列
- 拒绝大的SQL,复杂SQL拆成多个SQL
- 必须捕获数据访问异常。有俩个地方:mysql binlog里天然有写操作CUD日志,建议DAO层加CURD日志用于测试追踪。
- 关于系统性能差,核心原因是service应用层的架构设计不合理造成,烂代码造成数据库性能瓶颈。
- 互联网大厂的读写分离,在service层代码做代码读写分离,互联网大厂而没有用mycat等组件sharding.
- 如果复杂的SQL必须要用,并且like %suibin% 这种查询的效率极低必须用,又拆不了复杂的SQL,常用的是把数据同步到外置索引CACHE里:
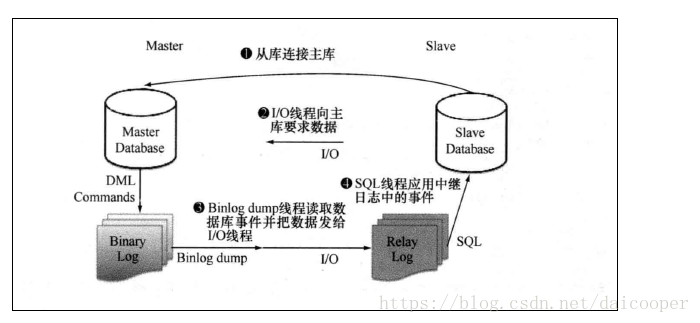
1、比如同步到ES里用ES模糊查询。或者同步数据到MongoDB实现模糊查询。这样需要写SQL还需要再写一套ES或MongoDB语法通过判断切换,还要写一个数据库同步表数据的逻辑。 - 关于MYSQL高可用:双主同步,每个主有自己的从库。在俩台主库上做虚IP,当一个主库出现问题漂移到另外一个主库。
集群的情况:








Redis哨兵模式(sentinel)学习总结及部署记录(主从复制、读写分离、主从切换) - 散尽浮华 - 博客园CentOS 7.5 部署 MySQL 5.7 基于GTID主从复制+并行复制+半同步复制+读写分离(ProxySQL) 环境- 运维笔记 (完整版) - 散尽浮华 - 博客园
MySQL HA 方案 MMM、MHA、MGR、PXC 对比 - heaventouch - 博客园
MHA(小日本做的一个binlog同步选主的管理端)+GTID主从复制(支持选主;方便维护修复但只支持innodb等事务引擎;MGR组复制也只支持innodb等引擎)+并行复制(解决主从延迟的问题)+半同步复制(解决relog同步丢失的问题)
MySQL+MGR 单主模式和多主模式的集群环境 - 部署手册 (Centos7.5) - 散尽浮华 - 博客园
Centos 7.5基于MySQL 5.7的 InnoDB Cluster 多节点高可用集群环境部署记录 - 散尽浮华 - 博客园
MySQL 5.7 基于组复制(MySQL Group Replication) - 运维小结 - 散尽浮华 - 博客园















 262
262











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









